
本文整理自8月21日,达观数据董事长兼CEO陈运文博士出席由南京市建邺区人民政府主办、南京建邺高新区管委会、南京市建邺区发展和改革委员会、创业黑马科技集团股份有限公司共同举办的“南京建邺数字经济暨AIGC产业大会”以《ChatGPT大语言模型的创新与应用》为主题的演讲分享。
ChatGPT应用背景
当今,很多白领的日常工作与文档的审阅、归纳、分析、起草、填报等息息相关的,需要他们坐在电脑面前一天8个小时不停做这些工作,但是,现在用一个AI技术自动化就可以很快完成这些工作。
陈运文提到,“我们今天写出来的文字资料,只是我们人类认知的表面,其实冰山以下是我们人类各种各样的知识,比如我们这里以一个狗为例,狗写出来是一个字,但是狗背后有很多的知识,有常识也有文化含义,还有很多的专业知识,怎么样把这个知识能够提炼出来,能够让计算机掌握,这其实是我们讲的AI里面最难事。”

他强调,大语言模型实质上是将文本中的知识提取和加工,进而驱动智能应用,并指出,ChatGPT从版本3.5到4的升级中,对知识的提炼和加工,以及多模态处理的能力得到了显著提升。

在谈到应用的需求方面,陈运文提到了算力、数据和算法。他指出,需要大量GPU以及专业人才来构建高度可用的系统。数据方面,除了收集大量数据外,还需要精细加工,以提取垂直领域的有价值知识。此外,算法的调优和应用同样需要专业人才的参与。当前,高性能的GPU算力在市场上备受追捧。在这个领域,英伟达的GPU积累众多,同时也与国内GPU厂商展开合作。达观数据已经成功将其模型与国产GPU进行对接,实现了在国产GPU上的推理操作。
“曹植”大模型
大模型的应用上面,大模型行业里面分两大类,一类是通用的,一类是垂直专用的模型,通用模型更像一个搜索引擎的增强版可以做各行各业的知识归纳总结,以前要搜索,一条一条看里面的结果,现在有一个模型提前看好了,更好总结出来。在这方面,达观数据专注于垂直领域的大语言模型,因为其主要服务面向企业(To B领域),需要将各个领域的专业知识集成到其模型中。同时,达观数据的大语言模型名为”曹植”,灵感来自中国历史上的曹植,以他七步成诗的典故闻名。

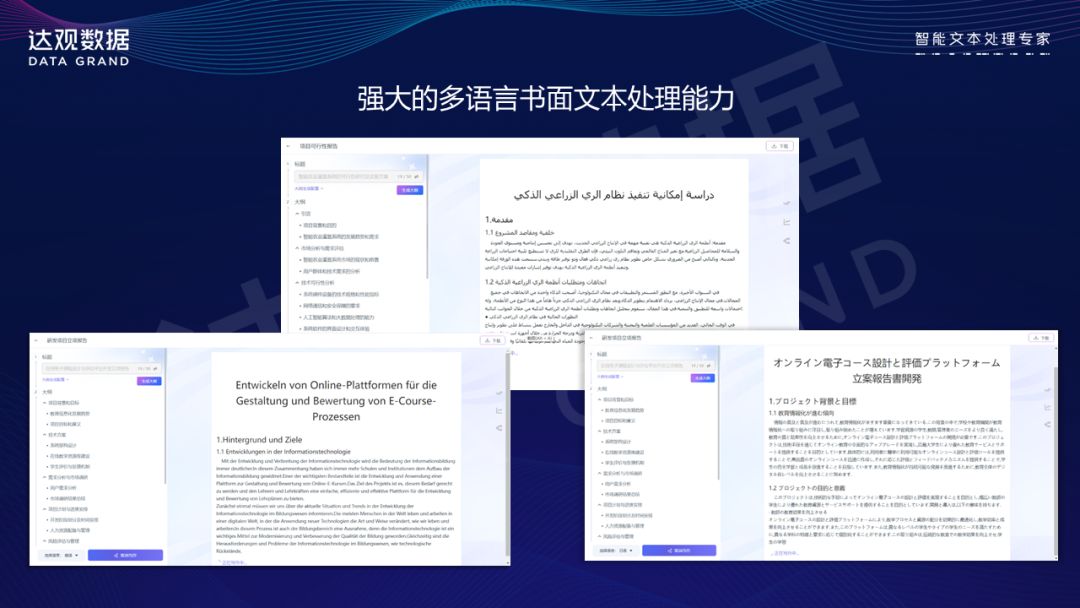
“曹植”大模型是一款垂直、专用、国产的大模型,具备长文本、多语言、垂直化三大特点。在日常的商业应用当中,其实大量的文档资料都是报告、合同、单据等等,这些文档资料对大模型来说非常有商业价值,所以“曹植”大模型特别擅长做这件事。多语言的应用非常有价值,不光是处理中文,也可以处理其他各种各样的文字,能够把各种语言、文字集合在一起,让一个模型理解和分析,不光是做翻译,也可以做很多的创新应用。垂直化是指将特定领域的专业知识融入模型,以完成相关任务。
“曹植”大模型创新性地采用了多模型并联(Ensemble)架构。由于在实际商业应用中,垂直领域的应用对准确性要求极高,单一模型难以满足预期效果,因此需要将多个不同算法模型融合,以更好地发挥作用。这是“曹植”大模型的重要特点,通过将不同参数规模和不同类型的模型相结合,更好地解决垂直行业的问题。

在以“曹植”大模型为核心的基础上,达观数据在垂直行业应用方面做了广泛拓展,涵盖问答、写作、搜索等多个应用领域。以证券领域为例,达观将其应用场景划分为落地可行性和大规模的应用两个维度来进行分析。利用曹植大模型实现了知识问答的场景,涵盖政策、人事、财务、业务等方面。以前这些任务都需要人工处理,但现在通过AI技术,可以自动阅读大量相关文档,完成问答操作。陈运文举例说到,“在监管领域里面典型的情况就是监管非常严、政策非常多,而且宣贯非常难,这些都可以用AIGC的技术自动完成。“在问答操作中,“曹植”大模型可以延展出多个相关问题,并能够根据行业知识提供准确、客观的回答。为了增强回答的可信度,大模型可提供政策原文的引用,以及其他参考资料。
“曹植”大模型的应用
在演讲过程中,陈运文还分享了“曹植”大模型在上市公司的应用案例,该模型用于董秘回答股民问题,使回答更加生动流畅,更加符合人们的预期。此外,“曹植”大模型在证券金融领域也应用了文档抽取和智能审核等人工智能技术,在这个过程中,也结合了大模型和传统算法,包括规则引擎等融合在一起,以更好地发挥各自的优势。

陈运文强调,“大模型的东西并不是大家所想的灵感妙药,并不是上去以后包治百病,有很多的弊端。比如大模型实际做文档结构化抽取的时候很难做到100%准确,纯粹用大模型抽取,往往不如很多用大量的数据精调过的很多传统的其他算法精度高,但是泛化能力比较强,所以一定要取长补短,这才是务实的态度。一个大模型传统的机器学习模型仍然可以发挥巨大的作用,所以要结合在一起,相互融合能够很好提升效果。以达观数据智能文本处理应用场景产品的实例,提交一个金融文档到大模型中,再使用大模型技术结合转动的算法模型,我们可以非常好对文档里面的要素和字段进行抽取的工作,我们抽取完了可以进一步用转动的规则引擎,针对行业这些文档进行任何的工作。任何我们做了很多方面的工作,包括这些要素是否完备性、真实性、一致性等等,最后自动生成一个审核报告。”
在多个垂直领域的专业文档处理中,达观数据取得了重要进展。陈运文提到,“函证是我们金融领域财务领域特殊的样式,而且样式非常复杂和多变,今天不仅可以让AI自动审核函证,我们可以让AI自动生成函证,不管是生成还是审核,都可以大幅度提升我们金融垂直领域应用的价值。”
在证券领域的辅助写作应用中,达观数据开发并落地了许多专业场景,包括发行人的上市申请、债券情况披露、行业研究报告、资管行业合同、信托、定制、尽调、托管等专业报告。这些专业报告的应用价值明显,以前靠人写的报告,首先效率低,写一个几十页的报告,一个专业团队要花几周的时间,现在有了AI技术,这个时间可以缩短十分之一,甚至是更好。

此外,人工撰写报告常常出错,而使用AI技术可以将错误率降至1%以下。大模型本身具备不断学习和成长的能力,可以吸收专家经验。这些应用不仅局限于证券和金融领域,而是在其他行业也开始落地。例如政府部门,大量的行政审批和材料审核工作可以通过AI技术进行预审,提高效率。
大模型行业的未来发展
未来行业的应用生态可能分成上游、核心和下游,上游就是算力、数据就是人工智能时代生产资料提供方。核心就是通用大语言模型研发方,像达观数据还有互联网巨头所做的通用大语言模型,下游就是各行业落地方案解决方案,这些落地解决方案其中包括一部分也正在开发,在未来在各行各业都可以创造出巨大的市场机会。

未来的办公状态会有巨大的变化,随着智能文本处理进行技术的发展,办公室可以把大量的工作自动化,让电脑自动工作,完成文档的审核、审批的工作,这些价值未来会逐步突破,相应的技术未来会逐步出来。
最后,陈运文提到,“我们相信未来智能化的文本处理技术,一定可以创造巨大的价值,宋代的发明家毕昇,他是活字印刷术的发明者,今天我们做的智能文本处理技术,就和1000年以前的活字印刷术一样用新的技术手段去实现文档资料的智能化处理工作,这个我们相信对各行各业都会有巨大的影响。我们觉得未来创新的技术能够让我们未来的生活更加美好,让我们的自动化程度越来越高。”




