
2023年8月27日,在第十七届全国知识图谱与语义计算大会(CCKS 2023)上,达观数据联合中国中文信息学会语言与知识计算专业委员会发起和倡导的开放知识图谱社区联盟项目OpenKG 、蚂蚁集团、同济大学、天津大学、浙江大学等核心参编单位发布了《语义增强可编程知识图谱(Semantic-enhanced Programmable Graph)白皮书》,达观数据副总裁王文广、 资深人工智能专家贺梦洁参与白皮书编写。语义增强可编程知识图谱(以下简称”SPG”)主要从企业数字化转型的视角出发,探讨如何利用知识图谱技术扩展属性图来帮助企业更好地管理数据和知识资产、发现数据与知识的价值。通过 SPG 框架,我们可以实现知识的动态到静态自动分层、领域内知识的唯一性和知识之间的依赖关系定义。同时,SPG框架还提供了可编程的范式,支持快速构建新的领域图谱和和图谱跨场景迁移。(文末点击“阅读原文下载白皮书)

SPG:语义增强可编程框架
首先,SPG通过形式化描述和客观事实两个视角,明确了数字世界知识的定义,如图1所示,从领域类型结构约束、领域内实例唯一性和知识间逻辑依赖性对形式化表示进行了定义,使机器可理解和处理。然后,SPG框架实现了知识层级间的兼容递进,以适应工业级的知识图谱应用。最后,SPG框架通过分层递进,可以有效衔接大数据架构,实现数据体系到知识体系的自动构建。
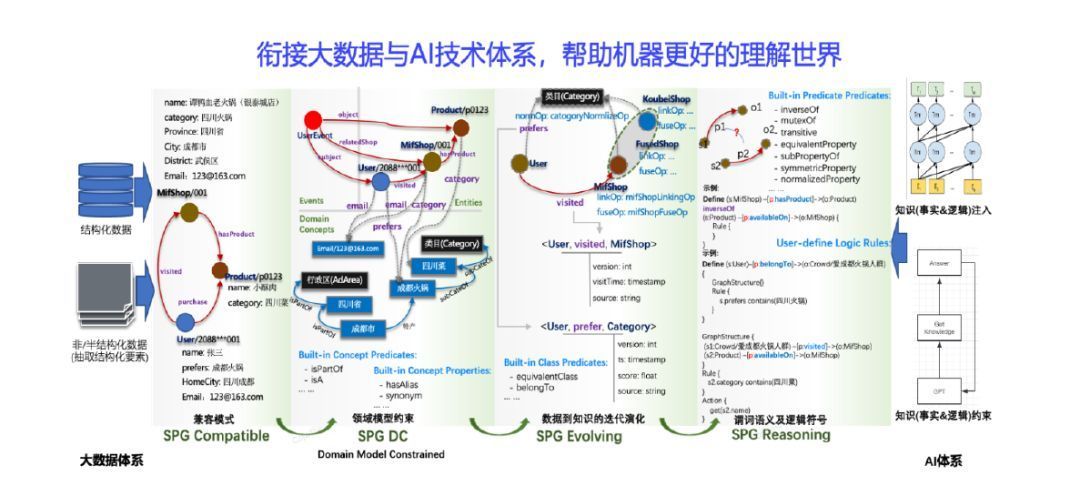
图1 SPG 知识语义框架
SPG 的核心目标是构建基于 SPG 的标准化知识引擎架构,给领域图谱构建提供明确的语义表示、逻辑规则定义、算子框架(构建、推理)等,支持各厂商可插拔的适配基础引擎、算法服务,构建解决方案等。
“曹植”+SPG提升领域知识构建与推理效率
2023年7月7日,达观正式发布“曹植”大模型。区别于chatGPT等通用大模型,作为垂直专用的国产大语言模型,“曹植”大模型能针对金融、工业、财税、政务、能源等垂直行业来开发特定应用,可以为每个客户量身定制、私有化部署,确保数据安全私密。
“曹植”大模型具有长文本、垂直化和多语言的特点,同时创新性地采用多模型并联的架构融合多种NLP和知识图谱。既能充分发挥大模型和传统模型的优点,又能有效避免大模型“幻觉”特性带来的准确性问题。知识图谱的事实性、时效性和逻辑严谨性成为了“曹植”大模型的绝佳能力补充。同时并联架构使得“曹植”大模型具有很强的鲁棒性,可以提供更优质的人工智能服务和产品。
与此同时,多模型并联架构带来的好处还有,不同尺寸、不同参数量级的大模型相互融合,能够很好地适应不同细分行业、不同垂直应用场景的差异性需求,模型落地性效果好、实用性强;并联架构能充分兼容各类其他外部模型,并为后续扩展预留充足藕合空间,为未来本地化部署中客户原生模型兼容问题未雨绸缪。
区别于一问一答的简单短文本生成,“曹植”大模型支持多种语言长文本的自动化写作和多语种翻译等功能,全方位赋能长文档写作、机器翻译、语义分析审核、知识问答、text-to-SQL等场景,可针对不同行业、领域的文案需求,进行深度优化和个性化定制。
“曹植”可准确完成多类型、复杂结构的长文本写作,自动起草多种类型的文档,同时具有自动排版、智能纠错、文本润色、自动生成摘要等特色功能;还将实现多模态内容生成,如长文档中的表格、图表、图片等;支持中文、英文、法语、德语、日语、韩语等数十种语言的写作,辅助人工大幅提高办公效率;在长文档翻译方面,对原文的标题、段落等内容实现 1:1版式还原,提供实时的翻译体验,广泛应用于多语言文档密集处理的场景。
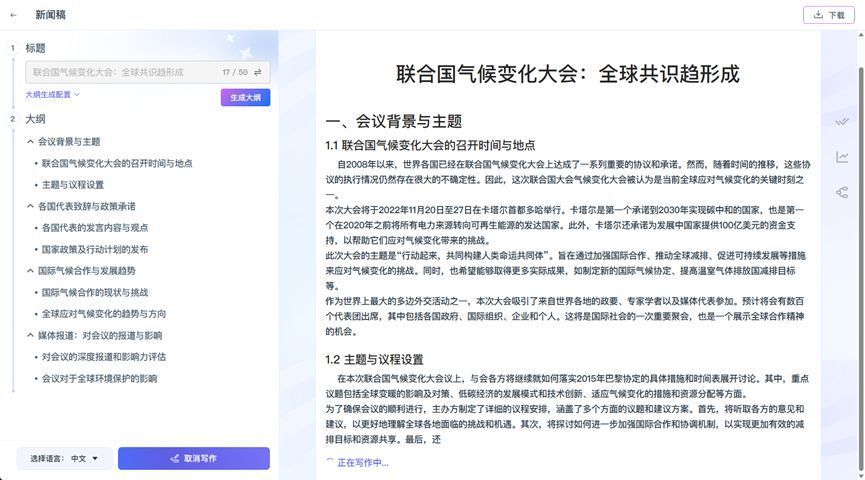
图2 “曹植”长文本写作应用
基于SPG强Schema、逻辑约束、符号化的表达能力,“曹植”大模型可以充分发挥其强大的结构、语义、逻辑理解能力,进一步提升领域知识构建与推理效率。
大模型和SPG的双向驱动目标架构,主要分为四部分:大模型适配接口(LLM Adapter Interface)、知识图谱的自动抽取&构建(SPG Constructor)、基于大模型实现SPG的自然语言查询(SPG NL Query)和推理(SPG NL Reasoner)。
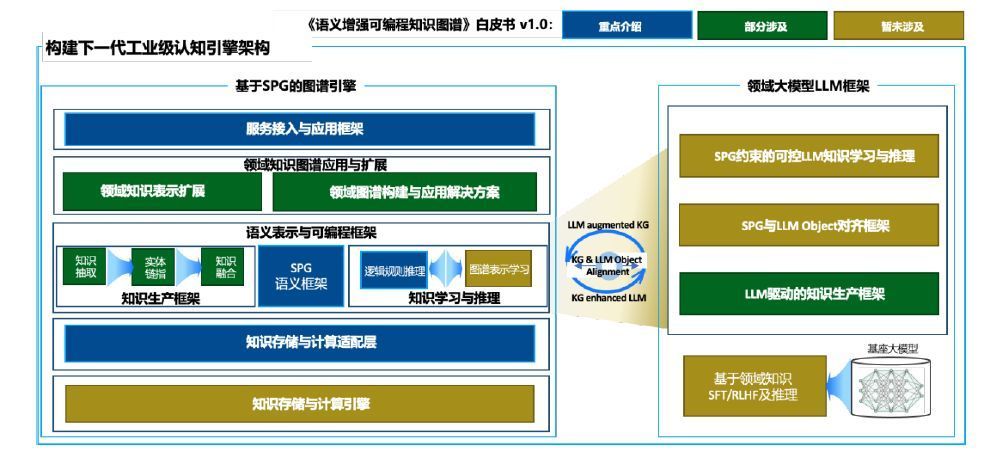
图3 SPG和LLM双向驱动的目标架构
基于“曹植”大模型的知识图谱构建
达观知识图谱平台是集成图谱建模、数据处理、知识抽取、图谱构建、图谱编辑、图谱应用等功能模块的可运营、可管理的知识图谱平台,支持创建并管理多个知识图谱,支持知识图谱迭代更新,支持创建、评估、管理多种模型,支持RBAC模式的权限管理。
以往达观知识图谱的知识抽取功能基于BERT模型和传统实体关系抽取模型利用多份标注样本进行模型训练实现,并需要根据场景和样本情况进行调参优化,对标注样本质量、数量及算法工程经验均有一定要求。
接入“曹植”大模型后,可以基于所设计的 Schema 进行提示工程的工作,来实现基于小样本量的实体、关系和属性的自动抽取,进而构建出知识图谱。
自动化生成 Prompt 的引擎,也可以参考本体中的推理引擎来实现。这里自动生成 prompt 会依赖于 Schema 中的自然语言注释,以及人工梳理的样例。在实践中,通过人工梳理样例或使用大模型自动生成抽取样例,有助于使用少样本学习,来提升大模型抽取的准确性。
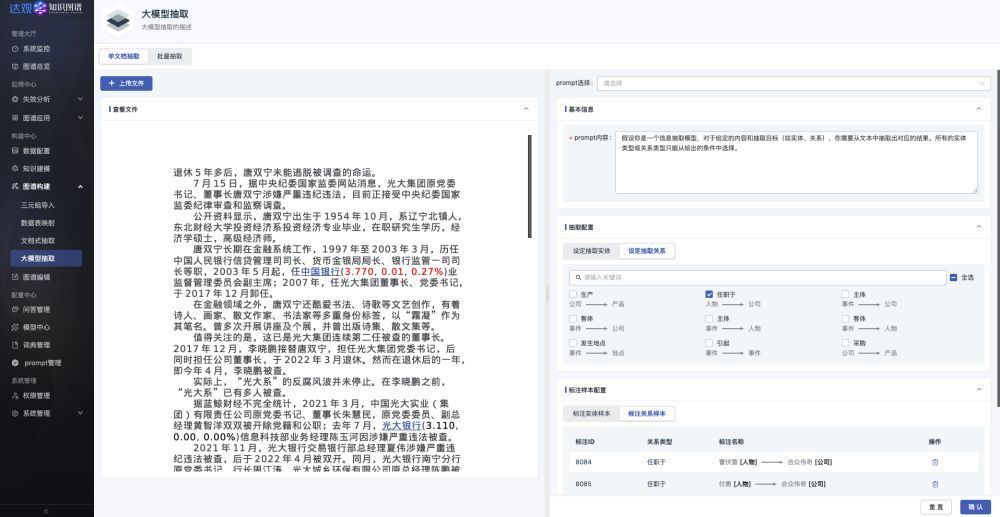
图4 大模型抽取示例
达观知识图谱平台利用“曹植”大模型来构建知识图谱,同时,在必要的情况下,提供人工审核来确保所构建知识图谱的准确性。
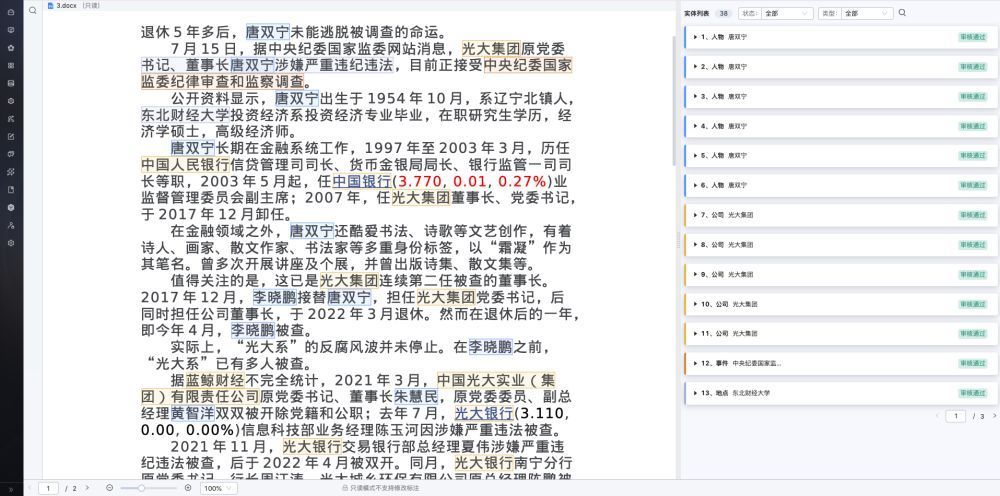
图5 大模型抽取审核示例
基于大模型进行实体抽取、关系提取等方式,从大量文本中构建出知识图谱的核心在于知识图谱 Schema 中定义了知识图谱中的实体类型、关系类型和属性类型等元素的规范,特别是相关的自然语言注释。这与 SPG-Schema 的规范强相关,在 Schema 中提供自然语言注释,有助于将其转化为大模型抽取和交互的 Prompt。
Schema 的自然语言注释,一方面能够实现 Prompt 的自动生成,另一方面在利用大模型进行知识图谱构建时,可以利用大模型来自动生成少样本学习的样本。在实践中,在关系抽取中,少样本学习是非常重要的,零样本要实现好的关系抽取非常难,而少样本学习能够大幅提升关系抽取的效果。
“曹植”大语言模型
“曹植”针对不同行业开发特定应用和训练专属数据库,使用海量训练数据进行“曹植”大模型的预训练,生成具备基础语言能力和垂直应用能力的模型;支持个性化定制,本地服务器私有化部署,独家提供精调服务,以加强垂直领域专用任务的能力;坚持训练数据与算法模型自主可控,与国产GPU合作伙伴开展长期合作,不断优化高质量硬件设备,以适应市场需求和技术发展,让大模型赋能百业。

“曹植”大语言模型也将进一步夯实达观产业应用智能化基座,全面增强AI全产品矩阵能力。这也是国内大规模语言模型中首批可落地的产业应用级模型,未来将可持续赋能金融、政务、制造等多个垂直领域和通用场景人工智能的落地和发展。达观知识图谱多年深耕金融、制造、能源等行业,积累了丰富的知识建模和应用场景经验,融合“曹植”大模型以后,充分发挥“曹植”大模型超强的语义、结构、逻辑理解力,进一步提升了知识抽取的准确性和泛化能力,同时补足了传统模型下小样本难以实现自动抽取的短板。另一方面,借助达观知识图谱提供知识基座,能够有效避免单一大模型的“胡编”、“幻觉”等不确定性问题,真正让大模型在产业实际场景下落地应用。




