近十年来,档案管理工作由原来的纸质档案管理转向了电子档案的管理,电子档案的产生对彻底改变了原有的档案管理模式,同时对电子档案的应用是电子政务建设过程中避不开的重要问题。利用人工智能技术对现有档案系统进行升级改造,对存量档案进行加工,使得活化档案内容,更便于应用,是新时代的档案建设的一大要务。国家对档案管理和应用工作一直十分重视,多年来对档案管理工作的智能化提出了具体的建设要求,如下表所示:
| 时间线 |
规划 |
指导意见 |
| 2014 |
《关于加强和改进新形势下档案工作的意见》 |
“各档案馆(室)要加强对档案信息的分析研究、综合加工、深度开发,提供深层次、高质量档案信息产品,不断挖掘档案的价值,努力把“死档案”变成“活信息”、把“档案库”变成“思想库””。 |
| 2021 |
《“十四五”全国档案事业发展规划》 |
“积极探索知识管理、人工智能、数字人文等技术在档案信息深层加工和利用中的应用。” |
另一方面,近年来智慧城市如火如荼的建设,带动了城市各种公共设施的智慧化,相继出现了“智慧交通”、“智慧医疗”、“智慧法院”、“智慧图书馆”等概念和应用。在此背景下,档案界提出了“智慧档案馆”的设想。
智慧档案馆是智慧城市中的一个子系统,“是适应大数据背景下的第四代档案馆,是继数字档案馆之后档案信息化发展的高级形态”。智慧档案馆的目标是实现跨时空的档案信息资源共享、跨平台的服务集成,使用户可以一站式获取所需要的档案信息资源。
但是现有的“智慧档案馆”建设大多还停留在档案馆本身的建设、设备、管理模式的改变。对于档案本身携带信息的活化、应用服务却没有进展。达观数据认为真正的智慧档案馆应该是充分运用各类技术手段,对档案资源管理并开发。档案馆运行等各类信息进行感知、挖掘,经综合分析和提炼萃取形成智慧信息,并将其应用于决策、管理和服务。
随着计算机信息技术的发展,档案数据的类型日趋多样化,由单一的结构化数据变得多样化,档案数据规模也显著增长。相比以前的纸质档案,数字化档案带来了更丰富的信息资源,同时也对档案信息的检索提出了挑战。
现阶段大多数数字化档案馆采用的存储检索方案是使用关系型数据库存储档案编号和人工著录项,再基于关键字进行匹配检索。这种存储检索方案忽略了档案数据内部隐含的大量信息以及档案数据之间的关联关系,无法完全满足用户日益增加的检索需求,更无法发掘档案数据之间隐含的关系。达观数据所擅长的AI+知识图谱技术改变档案数据的存储方式和档案资源的使用方式,为档案智能检索提供一种新的思路。
2012年谷歌公司提出了知识图谱(KonwledgeGraph),初衷是为了提高其搜索引擎的准确度和用户的搜索体验。本质上,知识图谱作为一张巨大的语义网络,描述了现实生活中存在的各种实体、概念及其关系。实体、概念使用节点来描述,属性、关系使用边来描述。现在各种大规模的知识库均可归类于知识图谱的范畴。
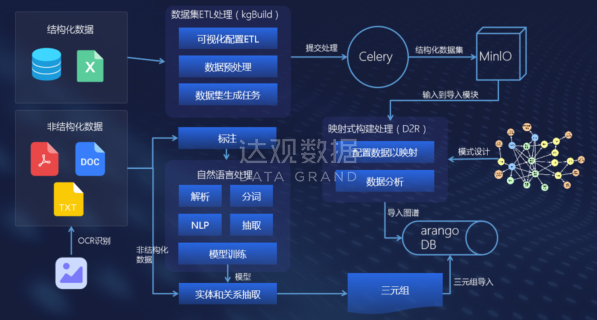
图 基于达观数据文本智能分析的技术,可以实现结构化和非结构化的数据都可以用来构建知识图谱
基于近些年人工智能技术的快速发展,知识图谱技术因其强大的语义处理能力和信息关联能力,在垂直领域中也得到了广泛的关注。垂直领域的知识图谱和通用型知识图谱在数据源、信息广度、知识准确率上都有很大的差异。相比之下,垂直领域的知识图谱的数据量较小、数据质量较高、知识更为集中因此构建垂直领域知识图谱通常需要针对该领域特定的数据源采取定制化的特征提取方案才能够高效地从数据中抽取出数据实体。构建档案领域知识图谱将为多源异构的档案数据提供关联,充分挖掘档案之间的关联关系,为档案智能检索提供了一种新的思路。
档案本体通俗来说就是档案领域内部各个层次的词汇、概念和它们之间相关关联的明确界定。常用的本体构建的方法有骨架法、Methontology法、循环获取法、TOVE企业建模法、七步构建法等,通过综合比较以上几种本体构建方法并结合档案领域特点后建议选用斯坦福大学医学院(StanfordUniversitySchoolOfMedicine)发布的七步法来构建档案本体,具体步骤如下图所示:
实际而言在建立档案知识图谱的过程中,需要根据档案的不同类型和应用场景来建立实体和关系,举例来说,城建档案侧重于大量的实施方案、规划图纸、检验单据等,人事档案侧重于身份材料、经历证明、奖惩信息等,不同的场景需要抽抽取的实体和关系千差万别。因此在整个实体的建立过程中需要根据不同的场景和应用,建立不同模式的图谱,以保证图谱内容契合于业务需求。
图 对于检测或验收单据的核心要素抽取
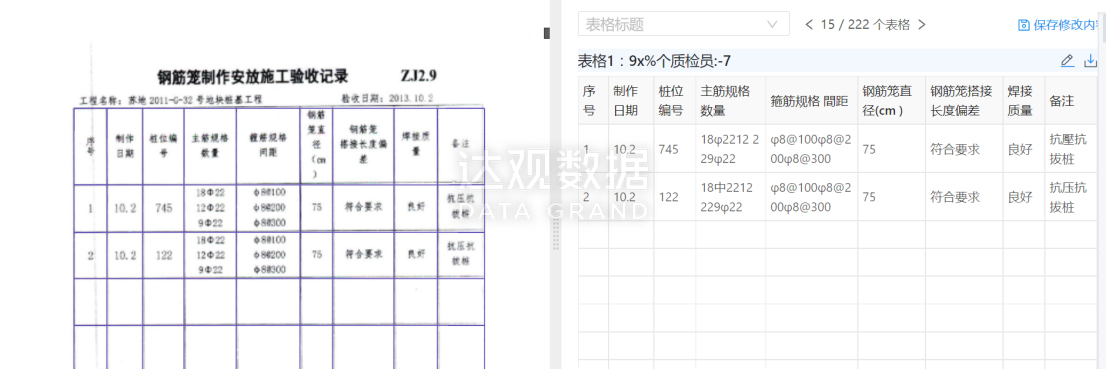
图 基于表格数据的核心要素抽取
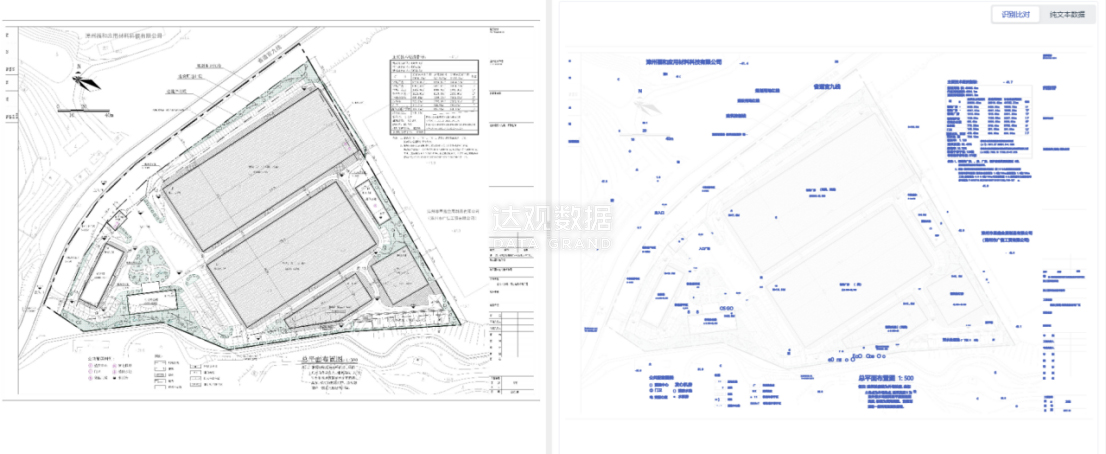
图 基于图纸的核心要素抽取,及图纸文本信息索引入库
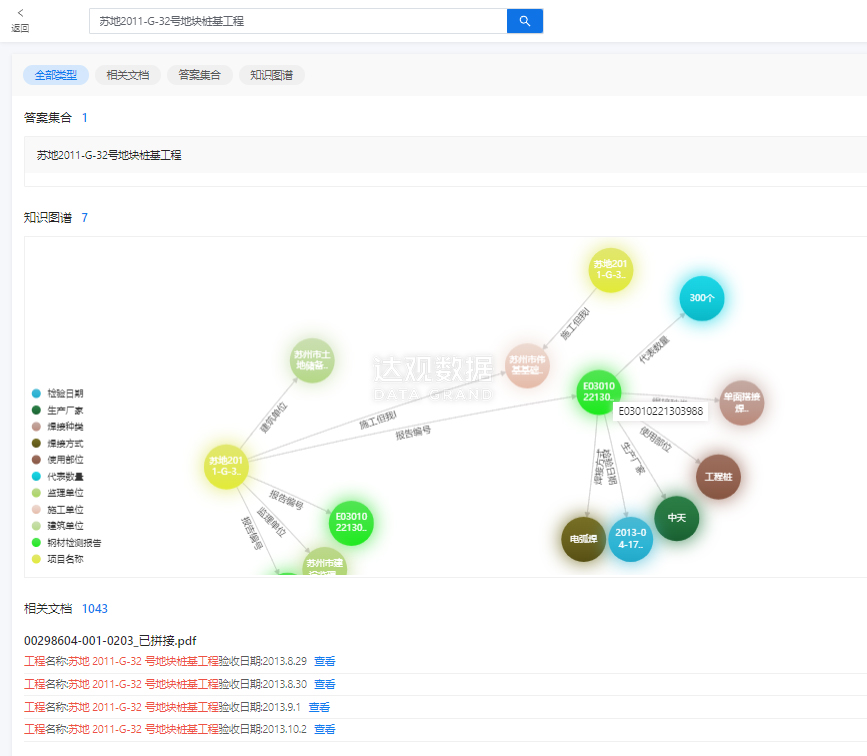
图 各个来源抽取的要素通过知识图谱进行关联,同时可以对检验单据和图纸的文本内容进行搜素
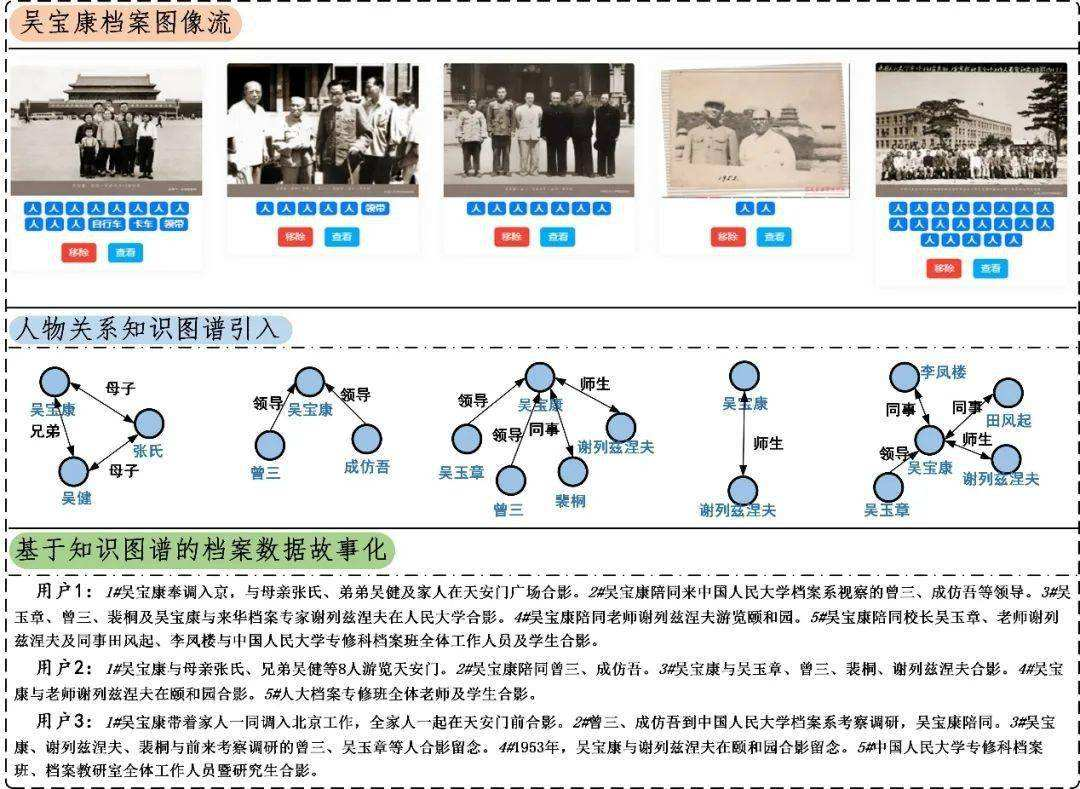
同时,知识图谱的应用将不光基于文字信息实体的抽取和关系搭建,存档的海量图像信息也可以进行知识图谱化,便于群众对档案信息的检索和应用。下面的例子就是说明了怎么从图片中抽取实体和关系来建立知识图谱。(吴宝康教授是我国著名档案学家、新中国档案学和档案教育奠基人)
图 摘自中国电子科技集团公司电子科学研究院论文《档案知识图谱构建技术研究》论文编号:8300015-2019-S14 作者:郭雪薇
达观数据现在已经与全国多家档案馆进行合作,深入探索人工智能技术在档案管理应用领域的发展,预计在不久的将来就会有实际的档案数据图谱案例落地。未来达观数据将在档案事业发展的“十四五”建设中发挥自己的核心技术能力。