
随着IDP文档智能处理技术不断发展,智能文档产品化商业化百花齐放,作为国内IDP赛道的领跑者,达观数据始终坚持技术引领与产品打磨,致力于为用户提供更先进、更便利、更易用的IDP产品。达观IDP文档智能处理平台具备文档撰写、文档结构化、文档审核在内的办公文档全生命周期处理能力。

达观IDP产品示意图
零样本学习算法
深度学习模型的训练往往需要大量标注良好的训练样本,但是这种训练样本的获取成本非常高昂。而零样本学习(zero-shot learning)让计算机模拟人类的推理方式,来识别在训练阶段没有见过新事物,从而大幅降低模型对人工标注的数据依赖。
本次达观IDP文档智能处理系统全新升级零样本学习(Zero-Shot Learning),无需标注训练模型,直接抽取文档信息,真正实现让AI触手可及。用户只需输入想要提取的字段信息,例如上市公司名称,股票代码,合同总金额,甲方地址,模型可自动提取关键信息。
零样本学习预标注数据
以公开数据集上市公司股权质押公告为例,传统的标注训练模式下,比赛提供4万份样本,截止目前市面上模型训练的最好效果是80.1%(F1值),而采用零样本的方式,在零标注的情况下,平均的字段抽取F1已可达到60%,在模型抽取错误的结果上,辅以人工复核修正,修正10份样本,迭代训练,模型的抽取F1即可达到70%。修正100份样本模型F1平均可达到75%,修正400份样本模型F1平均可达到80%,标注量减少99%。
从达观自身实践来看,传统模式下,以数百页的招股书为例,平均单字段的标注量为200份左右,单字段的标注+复核耗时约2小时,经算法工程师训练后模型平均字段准确率80%-95%。在零样本模式下,业务人员仅需复核模型的抽取结果,平均模型迭代仅需100份左右的标注数据,单字段的复核耗时约0.5小时,标注效率平均提升75%,同时,模型训练可由无算法经验和代码开发能力的业务人员1天内完成。

抽取效果示例
文档处理一站式学习平台
达观IDP文档智能处理平台集成智能文档处理全景能力模型,支持一站式标注-训练-抽取-人工反馈-模型自优化的业务闭环,结合本次全新升级的零样本学习,进一步降低智能文档处理应用难度,大幅减少人工成本,未来智能文档处理有望真正像人类一样自我学习。
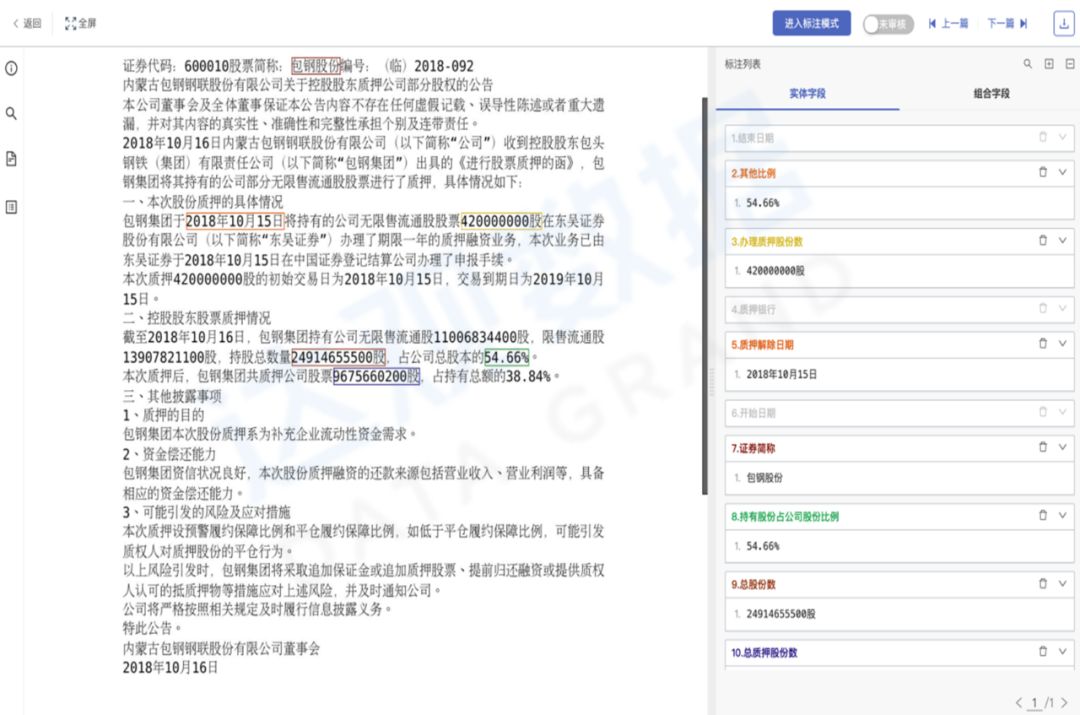
零样本直接抽取效果示例
达观IDP文档智能处理平台已深入应用于金融、制造、通信、法律、审计、政府等领域,提供智能撰写、信息抽取、文档审核等服务能力,为企业数据、风险管理、合规管理创造价值。




