

在达观数据举办的自然语言处理学术交流研讨会上,有幸邀请到复旦大学计算机科学技术学院邱锡鹏教授前来做客活动现场,并和大家分享了《自然语言处理中的多任务学习》的主题报告。以下为现场分享内容整理,内容略有删减。
本次分享内容围绕基于深度学习的自然语言处理、深度学习在自然语言处理中的困境、自然语言处理中的多任务学习、新的多任务基准平台四大模块展开。
什么是自然语言处理?自然语言就是人类语言,区别于程序语言,目前来讲自然语言处理有很多方面,是一个非常大的学科。包括语音识别、自然语言理解、自然语言生成、人机交互以及所涉及的中间阶段。
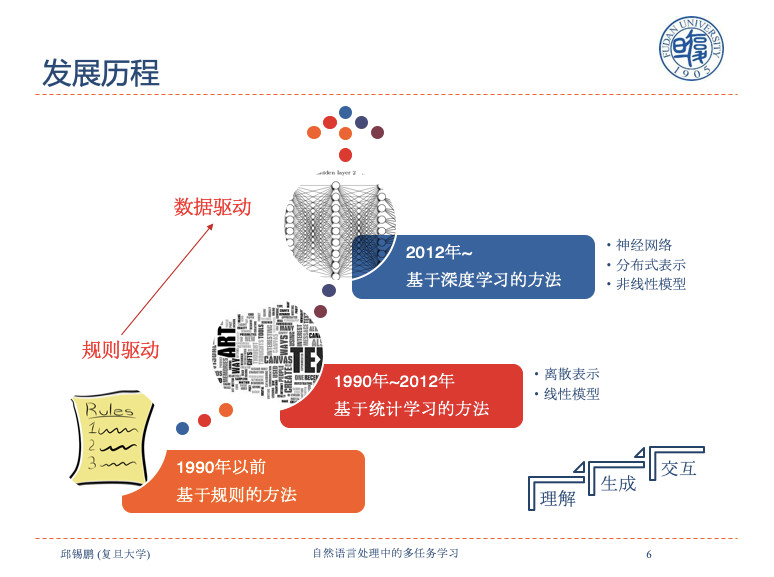
自然语言的发展经历了从规则到统计再到深度学习的过程,在深度学习方法大规模应用之前,自然语言处理主要存在两种学派,基于规则(rule-based)的符号学派和基于概率方法的统计学派。Noam Chomsky是前者的代表人物。在1990以前,自然语言处理多采用人工规则的方法,其后,在语料库(corpus-based)数据驱动(data-deriven)下,基于统计或机器学习模型的概率学方法成为主流。2012年以后,基于神经网络(neural-based)的方法开始大规模应用,以Sequence to Sequence Learningwith Neural Networks论文为代表的端到端模型在实践中取得重大突破。
在研究领域,工作重心也转变到了深度学习方法之上。早期NLP基本上有很多方式,各种各样的建模,把大系统拆成小块,把小块做好。现在更容易一些,端到端的系统,中间是神经网络。
目前NLP的现状是,我们所谓的深度学习其实模型并不深。一个主要原因在于NLP的数据量不够,因为标注成本太高。与图像标注不同的是,NLP更需要认知,通常需要专家来进行标注,所以成本非常高。
标注成本高需要我们转变思路:能否从学习框架上改变?现在用的非常多的比如无监督预训练,多任务学习和深度学习。
1.无监督预训练
去年暑假时很多报告在说ELMo,下半年就出现了另外一个BERT。相较于只有3层的ELMO,BERT具有12层网络结构,,并且证明在NLP里仍然有足够强大的表现能力。所以我们现在的问题是,NLP的数据不足,很大层面是通过大量标注数据来辅助训练,很多人把这种方法叫做自监督训练。
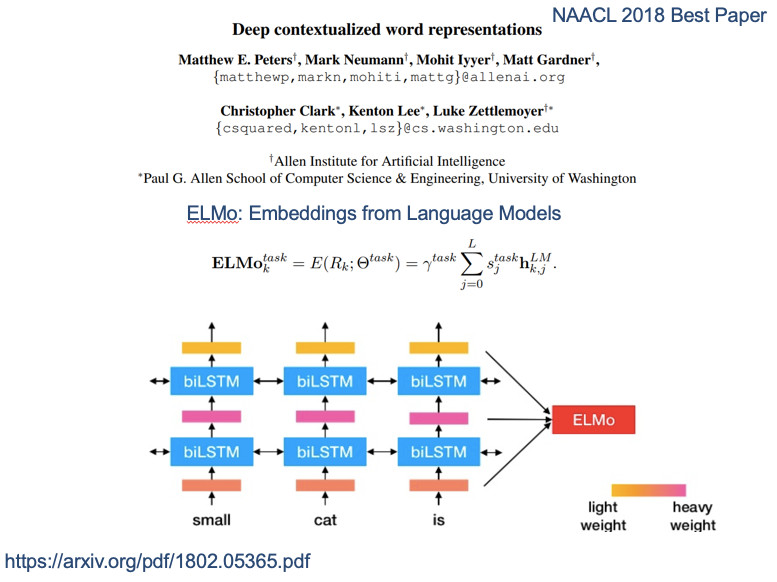
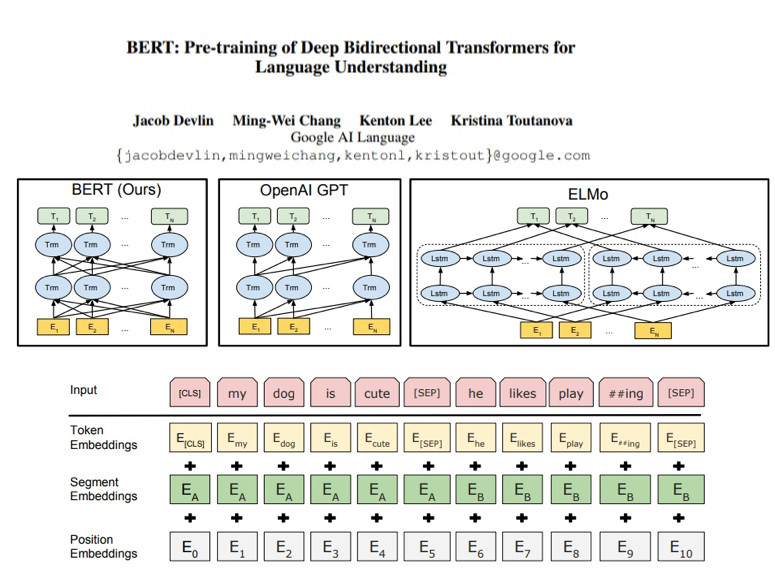
在NLP中表示学习依然十分重要,什么是好的文本表示?“好的表示”是一个非常主观的概念,没有一个明确的标准。一般而言,一个好的表示具有以下几个优点:
1.应该具有很强的表示能力
2.应该使后续的学习任务变得简单
3. 应使后续的推断任务变得简单
2.多任务学习
从上面三点出发,就对应到了多任务学习。我们的目标是学到一个表示,对所有任务都试用。既然这样,就直接让多任务一起学,把所有任务数据放到一起进行学习。举个例子,比如说有在三元组处理的POS标签和Chunking,用一个模型解决两件事。
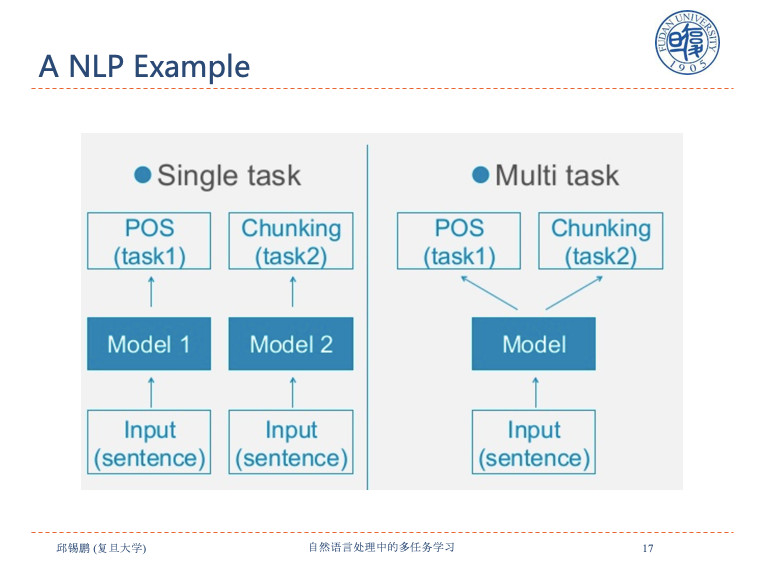
多任务学习在1997年被提出来。多任务学习加NLP在传统离散表示的时候,非常难,如何设置共享的表示很困难,因为是离散的空间很难投影做互相转化。现在,基于神经网络的深度学习方法的应用,使得多任务学习变得十分简单。
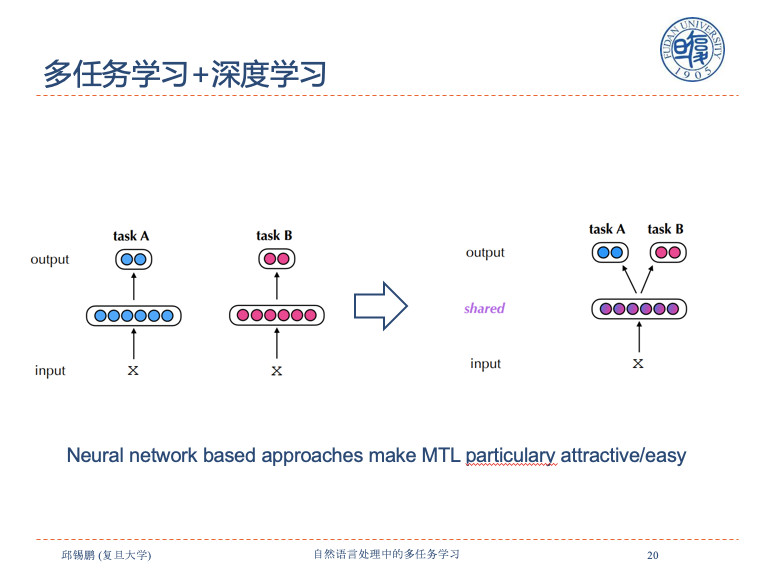
多任务学习和几类学习特别相似,一类是多标签学习,是指一个X进去,多个Y出来。一句话既可以有实体,还有实体之间的关系,相当于同样X上有不同的标签。多任务学习可能一个X在每个任务上只有一种标签,不同X有不同的标签。它的标签是离散的,一个句子一般不会把所有任务标签都打上。还有相关的是迁移学习,目标是在一个任务上学好然后迁移到另外的东西上。

多任务学习非常常见的训练方式是所有模型先联合训练,因为有共享的表示,这些层次在所有任务上进行训练,同时有私有层,在私有层每个特定任务上单独训练。经过Joint Training之后再进行Fine Tuning。
多任务学习之所以会有效可以从几方面来看:
1.因为实现了隐式数据的增强,因为数据增强是经常用的任务,但是在NLP里很难用。
2.我们的表示对所有任务都适用,所以学习了更加通用的数据表示。
3.正则化,尽可能去选择泛化能力比较高的点。一个表示对所有任务起作用,每个任务都有参数空间,所有任务参数空间的交集和搜索范围非常小,这样的程度讲,相当于正则化手段。
4.窃听技术,每个任务可以从另外的任务中获取对自己任务有帮助的信息。像这个盲人摸象,理解一个大象的话,可能不同任务是测试他的一个部件。如果把所有任务拼在一起可能会得到一个非常好的表示。
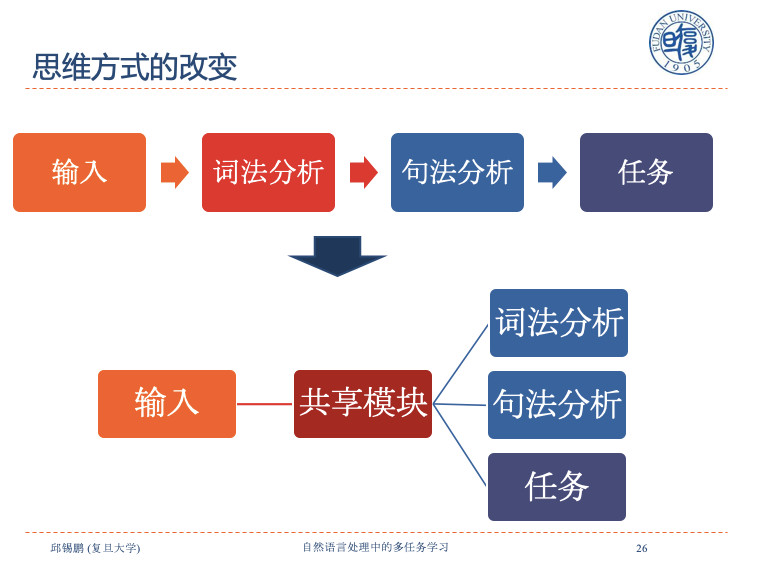
有了多任务学习之后,就可以改变做事的思维方式。输入——词法分析——句法分析——任务。我们很难把中间某一块做得特别好,如果中间有一块错了,就导致后面全错误。我们可以把词法分析和句法分析作为目标任务平行,然后一起去学习。因为要输出词法和句法分析,假设隐含了某种词法和句法的表示能力,直接送到目标任务上,这样就避免了错误传播。
NLP可以用的多任务学习有几种类型,一种是分类分析。有不同的领域,电影领域的和评价领域。这是天然的多任务学习,每个领域有单个任务,把所有任务放在一起学习电影评论中学习的情感词,这对上面的评论也会有用。比如刚才讲的自然语言的词性标注,到分词、句法。越往上越偏语义。这是与传统不太一样的多任务学习方式,我们需要严格设计共享方式。
现在越来越多的是文本和图象放在一起做交叉的检索推荐等,情感分析目前也做的非常多。我们在NLP里很多任务适合做多任务学习。还有一类万能的任务是语言模型,可以和任何任务结合,提高对应任务的效果。
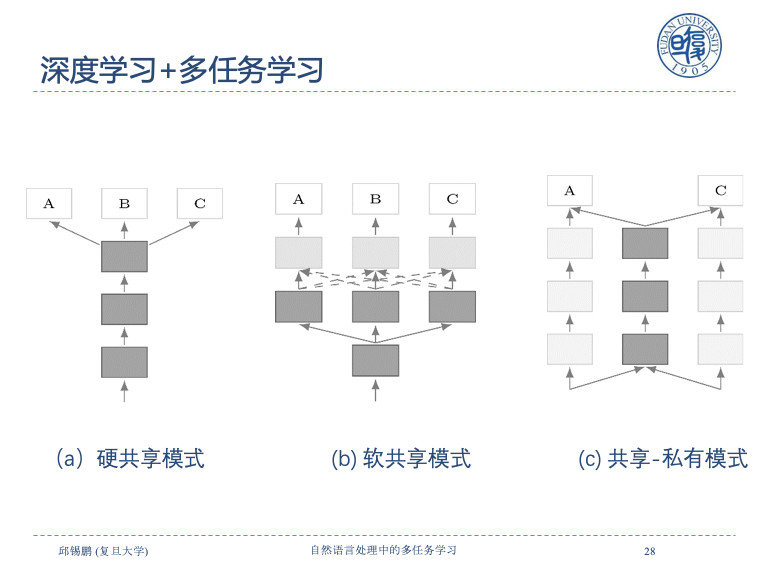
这里讲三个非常简单的共享方式,左边的a是硬共享模式,上面接三个不同私有层,中间是软共享,每个任务有自己主线,还有虚线,可以通过其他的注意力机制选择相关信息进来。c是共享私有模式,都有各自私有部分、共享部分。
1.硬共享模式
目前在NLP里的共享模式非常多,首先看硬共享模式,在2008年的时候就提出了自然语言神经网络处理。早期非常简单,只是把每个词的信息共享受。到2015年做机器翻译,机器翻译是天生可以多任务的,比如说英翻译成中文、德文、日文等。因为所有编码原文都是英文,所以没有设立多个编码器,让不同任务可以共享,这也是一种方式。
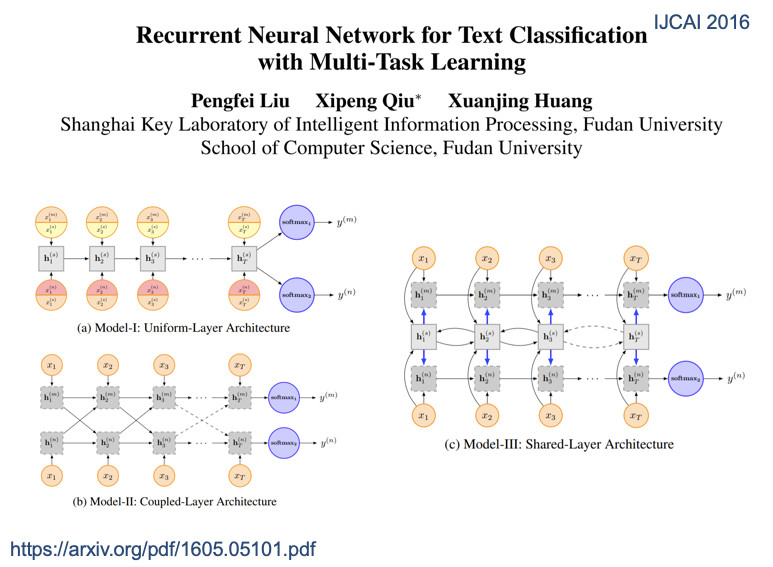
这个是我们之前的工作,把刚才三个共享方式用到深化神经网络中。现在看起来比较简单,当时没有人用。硬共享、软共享、私有共享模式,把三个共享放到文本分类上。包括这两年,通用表示在NLP上非常火热。用一个语言表示所有语言,这也是非常新兴的研究方向。我们目标是做多任务学习,同样的句子,虽然是面向不同任务,但是希望用同样的表示模型去表示。
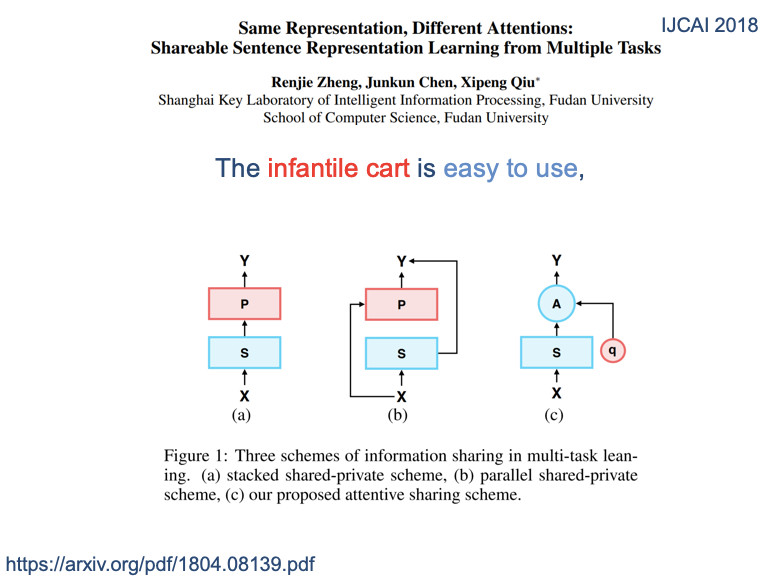
最左边的a是标准的硬共享模式,下面共享,上面是私有层,中间是共享私有模式。最右边是提出一个全共享模式。所有的X在不同任务的表示都一样。如果都一样,做不同任务,我们是否认为一个共享表示可能不能体现特定的任务信息?所以我们引入了一个任务相关的查询,叫Q。这个Q可以从共享表示中选出和任务相关的信息。用相同的不同的注意力进行多任务的框架。就是同样的表示,只是不同任务中不一样的部分,非常简单的同一个框架处理,以下是具体的学习模型。
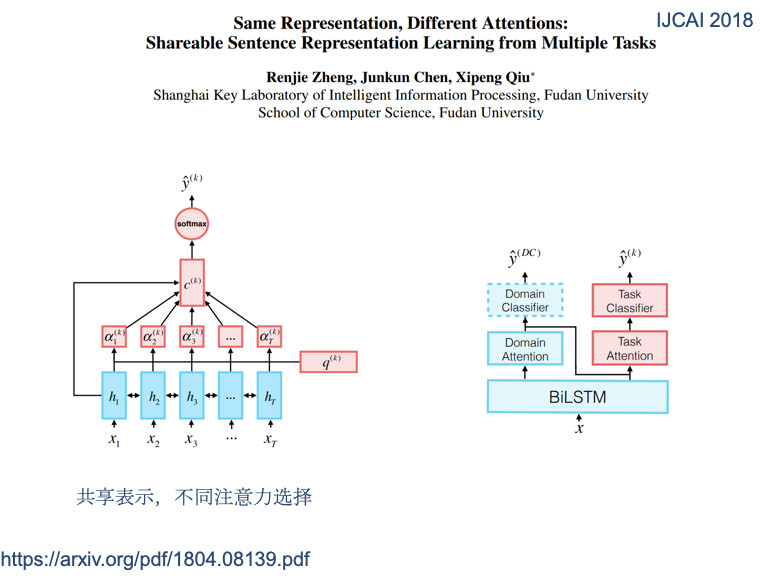

同样的文本在不同任务中,他的Attention是不一样的,红色表示Attention的权重,颜色越深表示任务越重要。不同任务的Attention不一样。
后面所谓的通用表示,这个概念越来越热,其实也是类似想法,只是用的任务更复杂,包括现在谷歌推出所有语言放在一起训练,得到更加通用的表示。
2.软共享模式
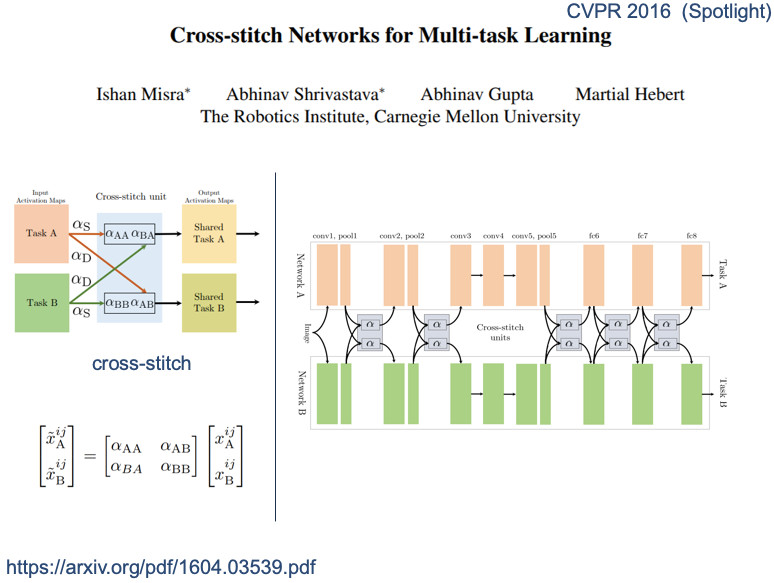
第二种是软共享表示。在每一层的时候,我们都可以从其他任务中去选一些信息过来,看起来非常像十字绣的方式。这是在NLP里的任务,更加复杂的网络,无非把任务的交互信息选来选去。
3.共享-私有模式
最后是共享私有模式。在该模式下,通过设置外部记忆共享机制实现信息在所有任务中的共享。
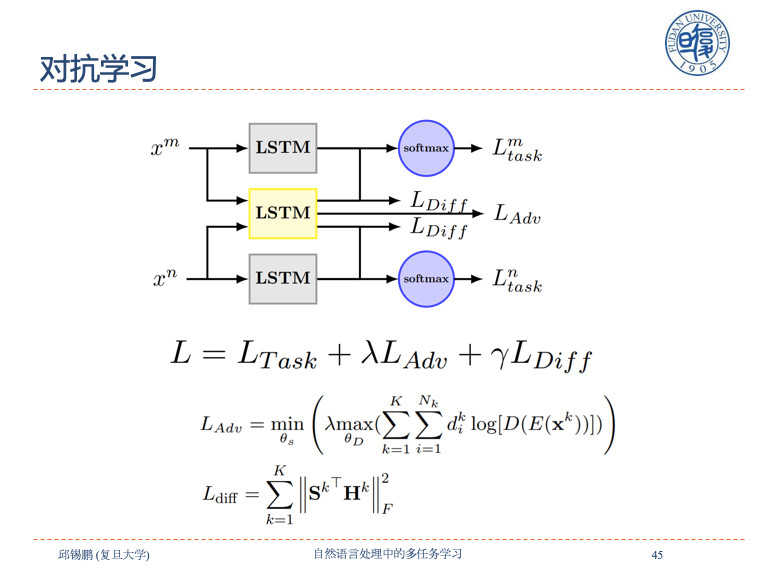
共享私有模式还有一个:避免在共享路径上传递负迁移的信息,这些信息对另外的任务有损害,我们可以通过对抗学习,引入对抗层可以有效避免不迁移的信息。
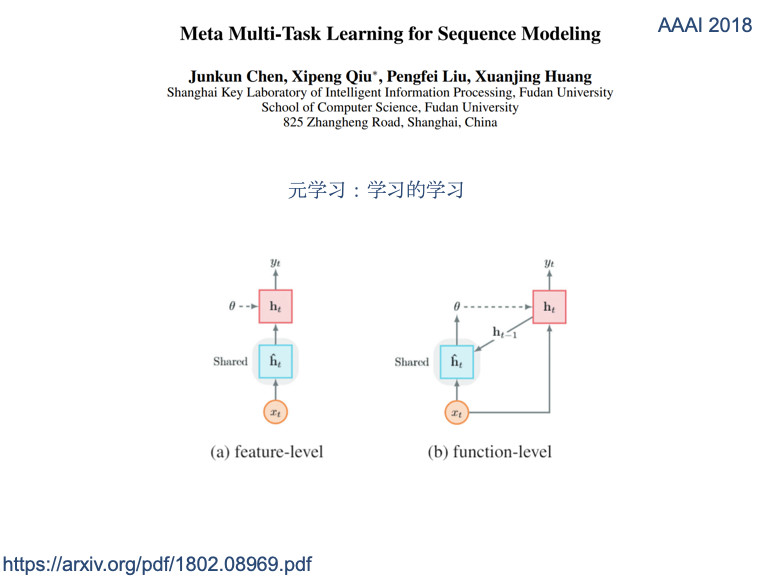
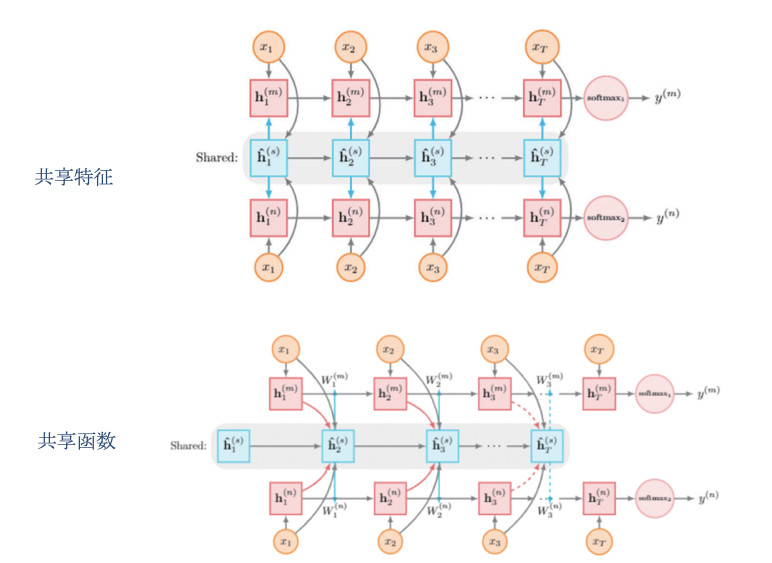
元共享,叫Meta Multi–task Learning, 这个函数生成各种不同的深层,我们叫多任务学习,生成各自任务的参数。
共享模式搜索是实现共享模式的自动组合,从而产生更加灵活的模型。在面向NLP的神经网络结构搜索中用一个控制器、一个STO的网络,生成一个目标网络,这个目标网络用来处理不同的NLP任务。上面的m是从共享词里自动挑出来的,这就实现了在所有任务中进行多任务共享。
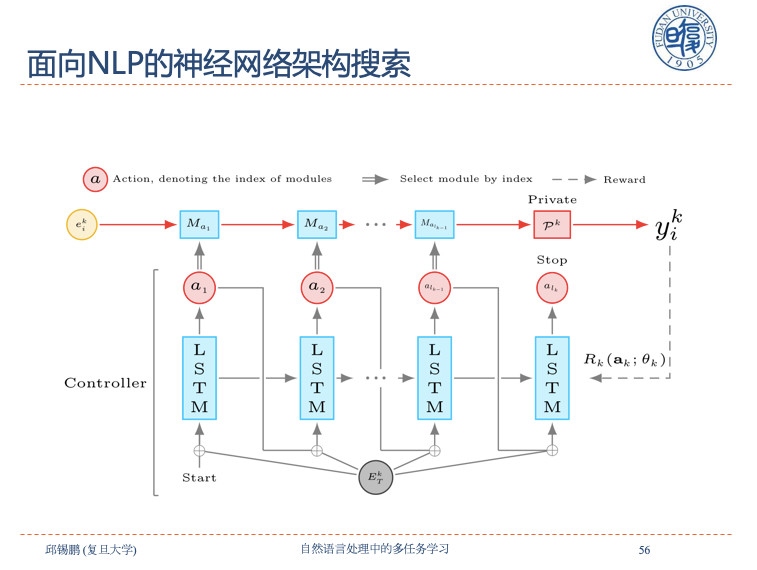
用一个控制器、一个STO的网络,生成一个目标网络,这个目标网络用来处理不同的NLP任务。上面的m是从共享词里自动挑出来的,这就实现了在所有任务中进行多任务共享。

这个是一个例子,这是自动挑出来的网络结构。比如说POS用了M1,chunk用了M1,紧接着用了m2,NER用了M1、M2、M3,这种方式将模型带入任务训练,从而实现了模型的自动选择组合。
今天分享就到这里,谢谢大家!




