
项籍是下相人,字羽。开始起事的时候,他二十四岁。项籍的叔父是项梁,项梁的父亲是项燕,就是被秦将王翦所杀害的那位楚国大将。项氏世世代代做楚国的大将,被封在项地,所以姓项。
(原文:项籍者,下相人也,字羽。初起时,年二十四。其季父项梁,梁父即楚将项燕,为秦将王翦所戮者也。项氏世世为楚将,封于项,故姓项氏。)
- 姓名:项籍/项羽
- 籍贯:下相(今江苏宿迁)
- 出道:24岁
- 叔父:项梁
- 叔父的爹(爷爷):项燕
- 仇家:秦国 王翦
- 姓氏由来:项家世世代代为楚国大将,被封在项地,所以姓项
现在请在20秒时间内看一下上面的信息并给别人介绍一下项羽,可以选择看原文,也可以选择看提取之后的信息。相信很多人会选择看后一种。这是因为后一种行文方式其核心信息不丢失,但是内容更简练,逻辑性更强,更容易记忆。这就是信息提取的意义。接下来的篇章将用更通俗的方式介绍一下文本信息提取技术的产业应用。
一.信息披露背景下的金融文档提取
下图是达观数据文档智能审阅系统(以下简称:IDPS)对招股书进行提取的示例,通过将文档上传到文档智能审阅系统中,一份大几百页的招股书被快速提取成右边上千个核心要素,包括董监高信息、财务信息、专利情况、募集资金与应用、上下游企业、重大合同、发行人所处行业等。同时支持点击跳转功能,比如点击右侧董事基本情况,除了直接提取出董事的姓名、出生年月、国籍、学历等信息外,左侧窗口页面也会滚动到招股书原文的对应位置。
图1 利用IDPS对招股书进行提取
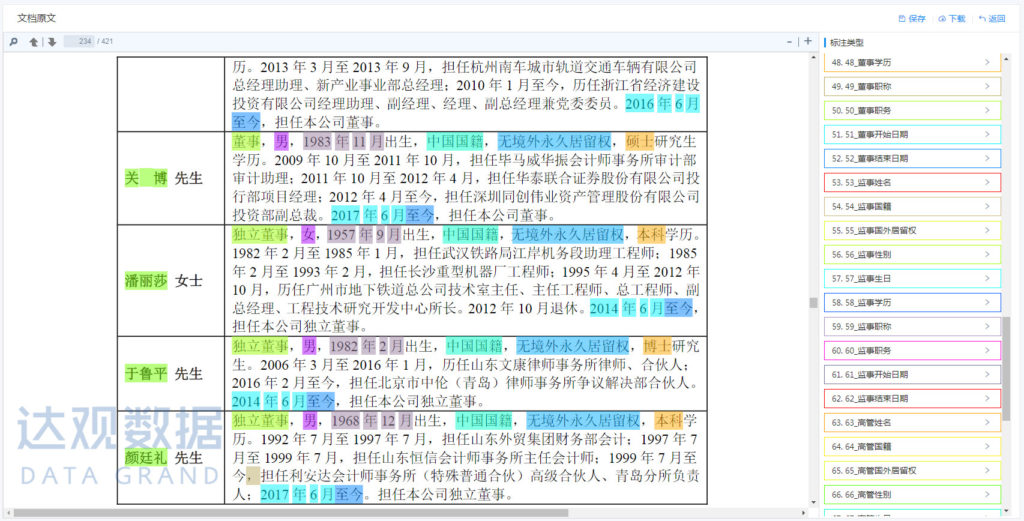
图2 利用IDPS对招股书中董监高信息进行提取
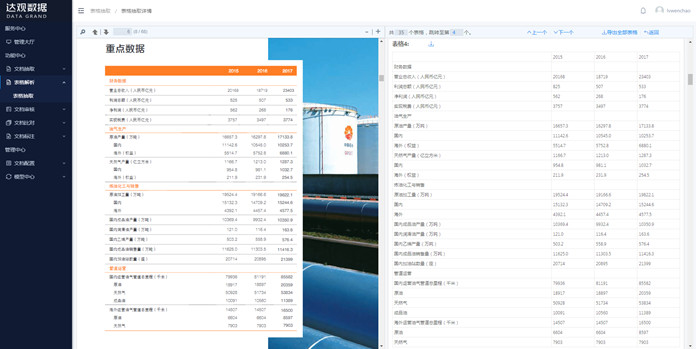
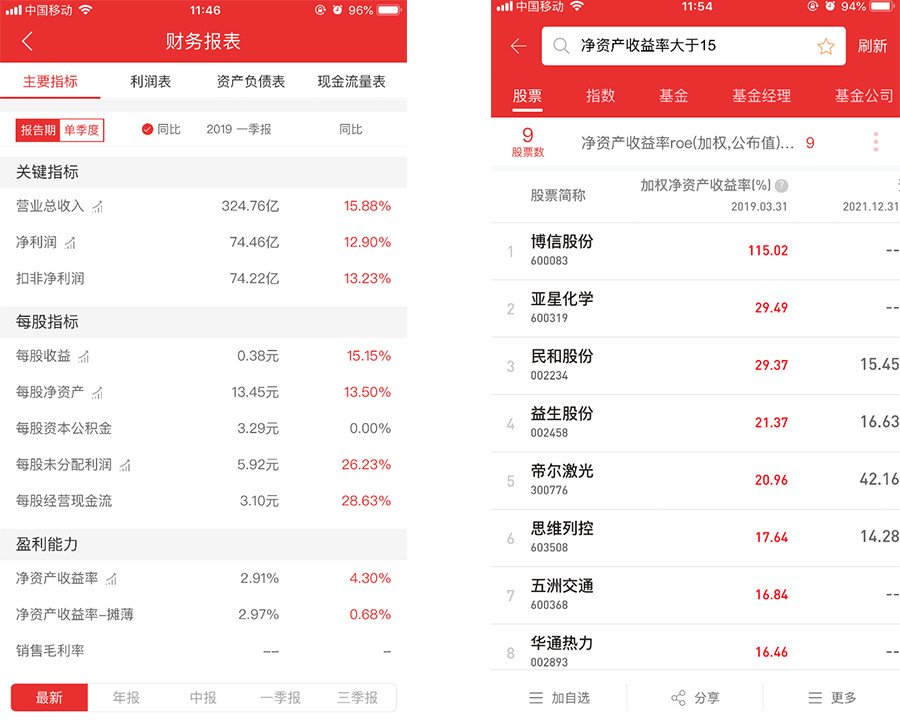
图3 利用IDPS表格提取对PDF格式的财报进行提取
你可能会问,企业的经营状况尤其是财务状况在其公告中都有非常详细的报表(资产负债表,利润表,现金流量表),为什么还要做提取呢?这是因为信息提取解决的并不是有与无的问题,而是解决效率和标准的问题,比如同样是2018年的上市财报,各家的格式、排版都不一样。所以人工阅读一份财报了解一家企业的基本面状况,同样的时间,借助信息提取了解的可能是一个行业几十家企业的基本面状况。这种有效信息量的巨大差异,对于投资决策的影响必定不同,带来的投资回报一定也是不一样的。
你可能还会问,能否自上到下推广一套统一的财报标准,所有企业都按照这个标准来披露财务状况,这样就不会有“代沟”了。其实行业内已经存在了,这里补充一个小插曲。
XBRL,1998年美国人提出,被誉为财务报表领域内的条形码。XBRL是在XML的基础上发展而来的,专门用于财务报告编制、披露和使用的计算机语言。XBRL通过对商业报告中的数据增加特定的标签和分类标准,以支持数据信息的识别、处理与交流。XBRL主要由技术规范、分类标准和实例文档三部分组成。技术规范是XBRL的总纲,定义了各类专业术语,规范XBRL文档结构。分类标准是根据XBRL技术规范对商业报告中的元素及其关系进行标记和描述的“业务词典”,是编制XBRL实例文档的具体规范。XBRL实例文档是依据前两个制作的实际财务或商业数据文件,是XBRL数据的载体。
在 XBRL 推出前,财务信息披露的数据格式包括 TXT、PDF、WORD、EXCEL等。这些财务数据披露格式很难实现不同形式数据间自由转换的功能,从而增加了信息使用者对信息对比分析的难度。XBRL打破了这一瓶颈,为财务信息提供了一个统一的标准化格式,可以实现财务信息的跨空间、跨时间对比。
在我国,XBRL推广主要包括证监会和财政部。证监会在上市公司财报披露,财政部在大型国资企业信息披露都有试点。但截止到目前,XBRL真正的潜力和作用并没有被完全发挥。这其中的原因较为复杂,从设立标准角度看,建立一套接轨国际同时满足行业、地域、监管要求的标准何其难;从推广使用角度看,上市公司、资本市场尚未对XBRL有足够的重视。所以,尽管大家都能理解XBRL是个好东西。但是要到普遍的推广应用,还有很长的道路要走。
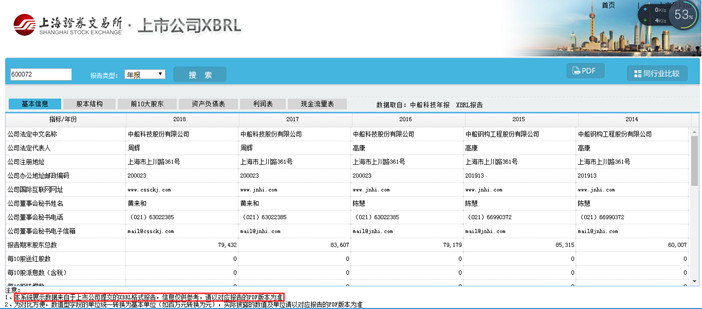
证监会是XBRL在国内最早的推广者。上证交易所官网有利用XBRL披露上市公司年报。但在网页下方会提示:“本系统展示数据来自于上市公司提交的XBRL格式报告,信息仅供参考,请以对应报告的PDF版本为准”。
二.法律判决文书的信息提取
2014年,最高人民法院为贯彻落实审判公开原则,促进司法公正,提升司法公信力,发布了《关于人民法院在互联网公布裁判文书的规定》,除涉及国家秘密、未成年人犯罪等少数几类判决文书不公布外,其余判决文书都需要在互联网上公开。(最高法裁判文书网,http://wenshu.court.gov.cn/)。
同提取金融领域披露的信息公告一样,也可以对公布的判决文书进行信息提取。比如针对一份民事判决书,我们可以提取案号、案由、审级、原被告、代理律师、代理律所、依据法律、审判机关、判决日期、判决结果等上百个核心要素信息。
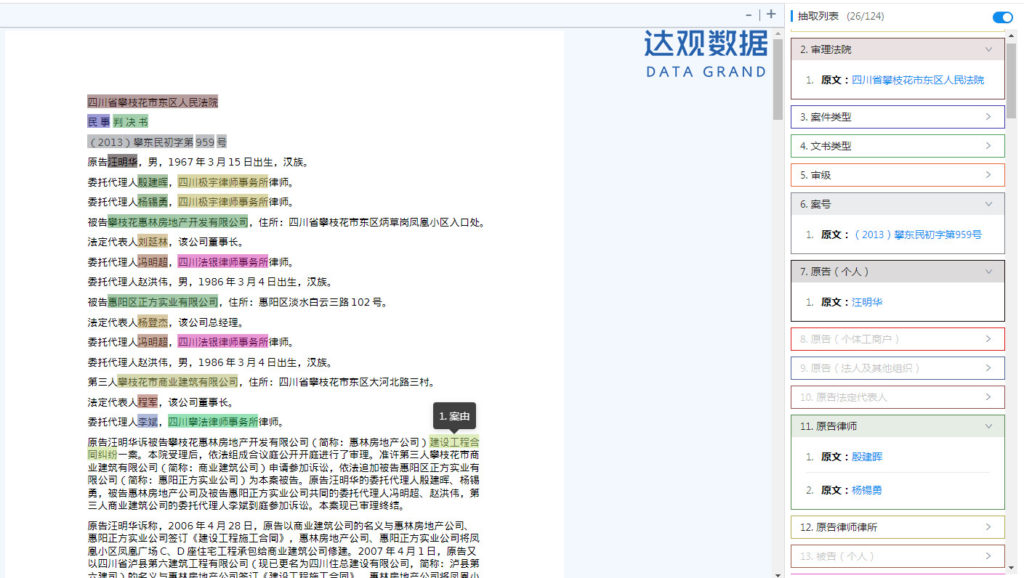
图4 利用达观IDPS提取民事判决文书中的要素
三.信息提取技术的原理
通过前文介绍,大概了解了信息提取这项技术的应用。接下来简单介绍下这些技术的原理。
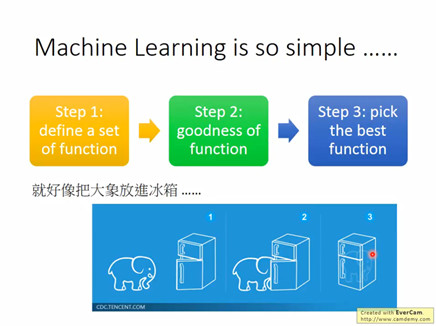
我们知道机器学习是已知一组自变量(input)和一组因变量(output),找到一个函数能够最优地拟合这组input和output。当有新的input进入时,利用这个函数可以得出output。所以,机器学习就好比把大象装冰箱,只需要三步。
如何利用机器学习去做信息提取呢,常用的就是序列标注。序列标注简单讲就是选用一些标签对输入的序列数据进行标签化。比如我想提取6月25日美空军战斗机在东地中海上空开展编队飞行这个事件中的时间和地点。选用BMEO(Begin, Middle, End, Other)来标记,BMEO每一个字母代表一个单字,一个词由多个单字组成,所以B代表中文单词的第一个汉字,M代表单词中间的汉字,E代表单词最后的汉字,用O代表其他不需要提取的字。我用T代表时间(此时T_B代表时间的第一个字,T_M代表时间中间的字,T_E代表时间最后的字)。用L代表地点(此时L_B代表地点的第一个字,L_M代表地点中间的字,L_E代表地点最后的字)。
四.总结
信息提取解决的并不是信息的有和无问题,而是解决效率和标准的问题。它用更加效率的方式将信息重新整合成一种标准规范的方式,从而用一个更为宽广的视角去审阅这些信息。
关于作者
吕文超:达观数据解决方案架构师,负责达观推荐引擎,搜索引擎,NLP,RPA等AI产品和技术在金融、政府、互联网等行业的应用落地。




