
企业真实场景中,知识乱象问题尤为突出:
企业级 RAG 的核心价值,从来不是打造聊天工具,而是构建可信任、可管控、可落地的知识服务体系。其核心能力体现在三个层面:
真正成熟的 RAG 架构,是知识工程、检索工程、权限工程的深度融合。用户提问后,系统先识别身份与权限范围,再改写优化提问,按权限过滤知识范围,通过混合检索与重排筛选有效内容,最终生成带来源追溯的权威答案,同时支持低置信度拒答、未命中问题沉淀、持续迭代优化,形成完整闭环。这也印证了一个行业共识:语料、权限、召回三通,普通模型也能稳定输出;三通不通,顶尖模型也只能在混乱信息中编造答案。
企业建设AI知识库,应跳出模型崇拜,回归知识治理本质。优先梳理知识来源、规范文档版本、建立权限体系、优化召回机制,再叠加模型能力,才能实现从“演示可用”到“全员好用”的跨越。RAG如同镜子,映照的不是AI能力,而是企业知识管理、权限管理、流程管理的真实水平,只有理顺底层机制,智能知识库才能真正成为业务支撑引擎。
达观智能知识管理系统(KMS)深耕企业知识治理与RAG落地场景,搭载垂直领域大模型,内置全流程知识治理工具,可自动完成文档分类、元数据提取、版本管理、去重清洗,从源头解决语料混乱问题。系统具备精细化权限管控能力,支持岗位级、部门级、片段级权限控制,实现检索前权限过滤,全面防范敏感信息泄露风险。同时采用关键词+向量+标签混合检索、多路召回与智能重排机制,精准匹配业务提问,大幅提升答案准确率与稳定性。
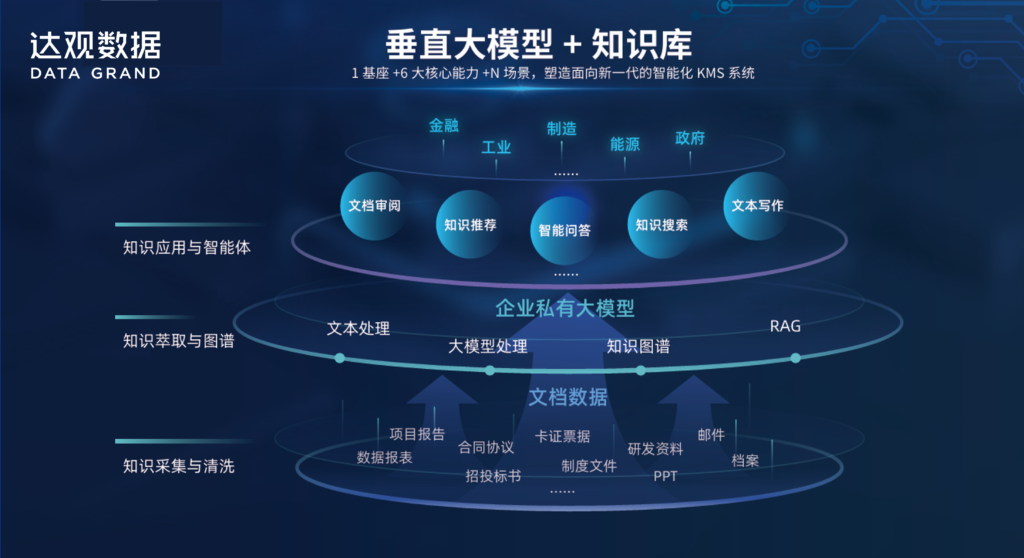
达观智能知识管理系统(KMS)可无缝对接OA、ERP、业务系统,兼容各类非结构化文档,支持智能问答、知识审核、智能写作、自动归类等全场景应用,已在金融、制造、能源、政务等行业实现规模化落地,帮助千余家企业构建可信任、可管控、可迭代的智能知识体系。达观智能知识管理系统(KMS)以 “知识治理为基、权限安全为底、精准召回为核”,让企业告别 RAG 落地困境,真正实现知识资产化、服务化、价值化,为企业数字化转型提供坚实的知识能力支撑。




