
本文整理自11月2日第七届达观杯专家培训讲堂上复旦大学计算机科学技术学院研究员、博导李斌教授《基于先验信息的中文场景文本识别》的主题分享。
在当下,随着数字化技术的快速发展和应用场景的多样化,中文字符和文本识别成为了许多领域的重要任务,包括自然语言处理、光学字符识别(OCR)、智能输入法、信息检索等。而利用先验信息来辅助中文场景下的中文字符和文本的识别,则成为提高准确性和效率的关键手段。先验信息指的是根据已有知识和经验构建的模型或规则,用于指导识别过程,其可以解决中文文字复杂多样的特点带来的挑战,推动相关领域的发展和应用。
中文字符的先验信息
一、层次结构
在报告中,李斌教授分享到,截止2005年,我国共收录27533个汉字,其中的3755个被列为常用字,其余文字在自然场景中出现的频率较低,属于严重的长尾分布。但文字可以分为12种不同的解构方式,这12种解构如图所示,可以经过递归的层级,形成像树一样的结果,比如右边所示的“刺绣”的”绣”,它形成了一个两层的棵树,这是这我们称为部首树的树。

二、少量笔画
李斌教授表示,中文字符不仅在部首上存在官方定义的结构方式,我们还可以自定义一些特定的解构方式。比如说中文字符可以拆解成一个五种笔画组合而成的笔画序列。当然中文汉字本身不止这么多笔画,但是在汉字识别的任务当中,我们把它定义成5种笔画就是横、竖、撇、点、折。当然这个折它包含很多的不同的子类,但是我们都认为它也是,比如说竖折钩、竖弯钩、横折钩等。再比如说右上角这边3个汉字,它是用5种笔画的表示,12345就表示不同的笔画的序号,然后笔画序号来用一个序列来表示汉字的笔画构成。由于中文字符较多的是方正的字,所以这个笔画均有较为特定方向,因此中文字符可以在横竖斜,在横、竖、左斜和右斜4个方向上进行拆解,得到方向性的变化信息。

三、空间布局
同时,李斌教授提到,中文的文本还存在布局上的先验信息。像这边左图就是单文本行,横向文本的长度往往大于整行宽度,而纵向文本的长要小于宽度。所以这个信息其实我们在做文本判断的时候,大家都会用到的先验信息,另外针对多文本古籍中均为自右向左,然后自上而下的这种模式,而现代文中均为自上而下,自左向右。这一类的先验信息能够提供相应的阅读顺序,进而为模型引入特定的布局先验信息。

中文字符识别方法
一、开放集下的中文字符识别方法
李斌教授介绍到,该任务要求模型能够有效的识别机制,识别出训练及见过的这些汉字,而且能够发现新的字符,新的词汇,也就是说训练集中未见过,如一个日本字,然后能通过不重新训练模型的方式快速调整模型来识别发现的新字符。为了从根本上解决新样本字符问题,我们提出了基于笔画先验的中文字符识别方法。提出的方法如图所示:
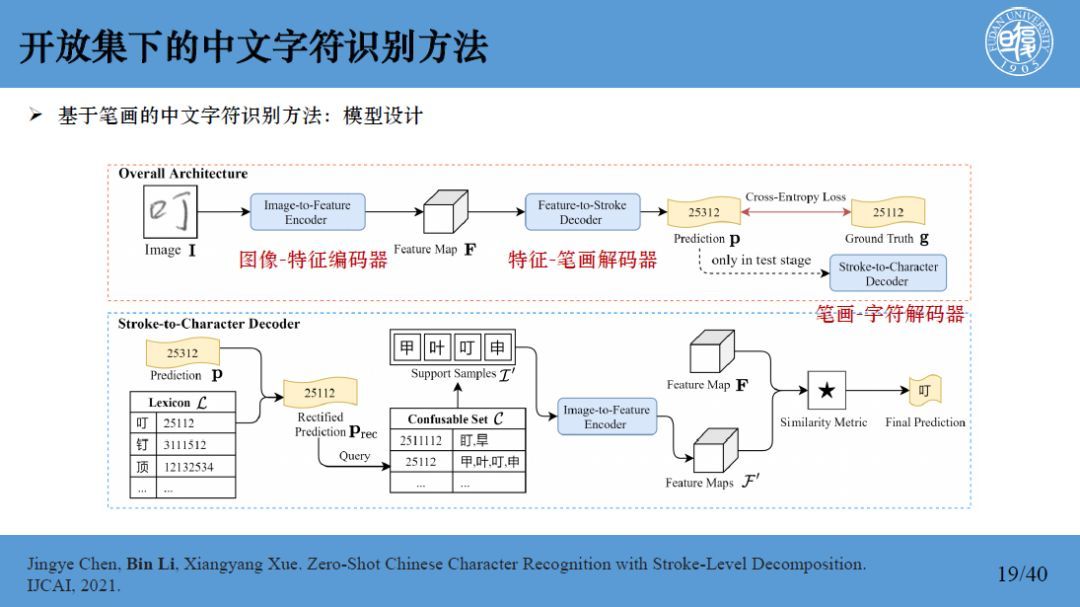
模型整体是有三个模块,一个是图像-特征编码器,另一个是特征-笔画解码器,还有一个是笔画-字符解码器。在训练阶段,我们仅需要对前两个模块进行训练,并用相应的笔画序列对这种模型的预测进行监督,采用交叉熵损失。
然后在测试阶段我们引入笔画-字符解码器,将这个笔画序列映射到相应的字符类别上,笔画字符解码器的具体结构就是上图的下半部。得到预测的笔画序列之后,我们利用边际距离找到和预测笔画序列最接近的字,笔画序列,我们称其为校正后的一个笔画序列。由于一个笔画序列可能对应多个字符,所以我们是通过特征匹配的方式完成这个最终字符的分类。
二、竖直中文文本识别方法
此外,李斌教授及其研究团队,还提出了一种朝向独立的中文文本识别方法,所谓的朝向独立,也就是说我们把朝向单独的特征给解耦出来,在识别的时候我们不考虑朝向的特征,只考虑汉字本身的特征,然后我们怎么来达到这个目的,我们就提出了这么一个训练的框架,是我们在训练阶段采用包含竖直和水平的这种文本图像,对于这个竖直文本图像,这个模型将其逆时针旋转90度后再送入识别器。
然后在这个特征提取之后,我们用提出的重构模块,先对竖直和水平字分别进行内容信息和朝向信息的解耦,所以这个核心其实就是要把这个内容和朝向进行解耦,然后接着利用这个字符图像重构模块重构具备相应朝向的印刷体字。最后我们仅将内容信息的特征表示送入到解码器中,以此来避免朝向信息对识别器的影响。所以我们是通过识别的监督信号,让它反作用于前面朝向信息的去除。

三、基于部件的中文文本识别方法
基于部件的中文文本识别方法是一种将文本识别任务分解为字符级或部件级别的方法。以下是一种基于部件的中文文本识别方法的简要步骤:
- 部件切割:首先,对输入图像进行字符或部件的切割。这可以通过传统的图像处理技术,如边缘检测、连通区域分析和轮廓提取等来实现。
- 部件分类:对于每个切割得到的字符或部件,使用机器学习或深度学习方法进行分类。传统的机器学习方法可以使用特征提取和分类算法,如支持向量机(SVM)或随机森林等。深度学习方法可以使用卷积神经网络(CNN)或循环神经网络(RNN)等进行训练和分类。
- 字符序列重组:根据部件的分类结果,将字符或部件按照正确的顺序重新组合成文本序列。这可以通过应用序列匹配算法或者使用语言模型来实现。
- 后处理:对于得到的文本序列,可以进行后处理步骤,如去除冗余字符、纠正错误或者使用语言模型进行更准确的推断。

基于部件的中文文本识别方法可以有效地处理中文字符的复杂结构和变体,并提供较高的识别准确度。然而,该方法的性能往往依赖于部件切割的准确性和对部件分类模型的训练质量。因此,在实际应用中,合适的数据集和有效的训练策略是关键要素。




