
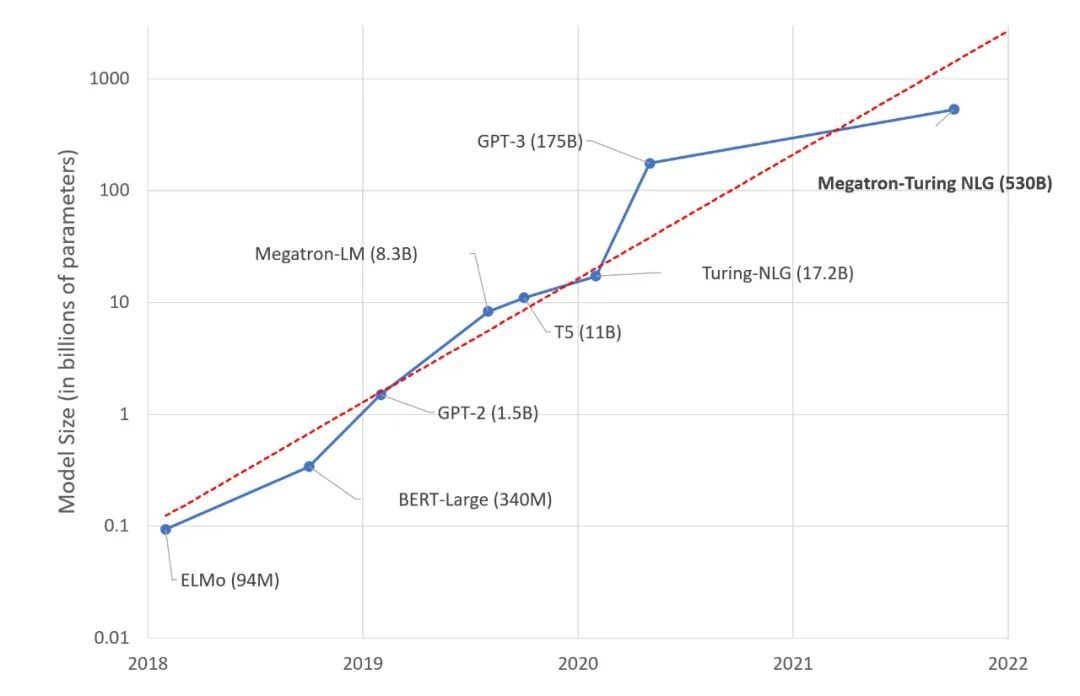
导读:中国工程院院士王恩东曾表示:“人工智能如何发展出像人类具备逻辑、意识和推理的认知能力,是人工智能研究一直探索的方向。目前来看,通过大规模数据训练超大参数量的巨量模型,被认为是非常有希望实现通用人工智能的一个重要方向。”随着巨量模型的兴起,巨量化已成为未来人工智能发展非常重要的一个趋势,而巨量化的一个核心特征就是模型参数多、训练数据量大。
那么,由此引发出一个令人感兴趣的话题是”这些大模型是否能够真正理解人类所说的话语(自然语言)?”
针对这个问题,本文原作者布莱斯.阿圭拉.阿卡斯(Blaise Agüera y Arcas),基于大型语言模型聊天机器人LaMDA的对话测试对此进行了一番探索。布莱斯.阿圭拉.阿卡斯是计算机视觉、机器智能和计算摄影方面的权威。在谷歌,他领导的团队建立了利用机器智能、计算机视觉和计算摄影的产品和技术。他还在谷歌创立了艺术家和机器智能项目,通过将机器智能工程师和艺术家配对来创造艺术。
翻译:达观数据解决方案副总监 高长宽
内容提要:大型语言模型(Large Language Models,LLMs)代表了人工智能的一大进步,特别是朝着“类人(human-like)”的通用人工智能的目标迈进。但也有人声称,机器学习 “只是统计学”,因此,在这一宏大的目标中,人工智能的进步好似“水中月、镜中花”一般虚幻。在这里,我采取相反的观点,即大型语言模型在语言(language)、理解(understanding)、智能(intelligence)、社会性(sociality)和人格(personhood)的本质方面有很多东西可以“传授”给我们。具体来说:从任何可证伪的意义上来说,统计学确实相当于理解。此外,我们所认为的智能大部分是内在的对话性(inherently dialogic)的,因而是社会性的;同时,它也需要一种心智理论(theory of mind)。复杂的序列学习(complex sequence learning)和社会互动(social interaction)可能是一般智力的充分基础,包括心灵理论和意识(consciousness)。由于另一个生命的内部状态只能通过互动来理解,所以对于 “它 “何时变成 “谁 “的问题不可能有客观的答案,但对许多人来说,在计算机上运行的神经网络(neural network)有可能在不久的将来跨越这个门槛。
Large Language Models: 新的摩尔定律?
与基于大型语言模型的最新一代人工智能聊天机器人(AI chatbots)进行对话,可能既令人兴奋又令人不安。许多人还没有过这种体验:这些模型对计算的要求仍然很高,无法广泛使用。随着新芯片的开发,这种情况肯定会在未来几年内发生改变,普罗大众得以在各类应用中低成本使用这些模型。

对话机器人是最能体现AI能力的一种应用场景
不过,就目前而言,这些对话大多是由人工智能研究人员、评分员和早期测试人员进行的。有时,特别是在重复测试一些特定的提示、应用或训练技术时,它可能会变得平淡无奇,以至于与任何其他类型的技术系统的互动没有什么区别。在其他时候,尤其是在没有脚本的交互(unscripted interaction)中,很难摆脱屏幕另一边是“谁”,而不是“它”的想法,主要的好处在于,即使是较长的反应也是近乎即时的。我与谷歌最先进的大型语言模型聊天机器人LaMDA(译者注:LaMDA即Language Model for Dialogue Applications,采用全新自然语言模型框架,将可让电脑系统比拟真人思路理解使用者对话内容,进而通过不同场景应对方式呈现更贴近真实的互动。从目前展示内容来看,「LaMDA」背后所串接资料量相当庞大,同时也会从对话过程中持续学习、改变互动模式,意味随着持续互动情况下,「LaMDA」将会藉由学习知晓更多对话内容互动模式,进而让对话互动可以变得更加自然,同时未来也能藉由更能理解使用者对话需求,让翻译内容也能变得更流畅。)的第一次对话是以 “你是一个哲学僵尸(philosophical zombie)吗?”的问题开始的。这是指一种假设的存在,由哲学家罗伯特-柯克(Robert Kirk)在20世纪70年代发明,后来由其他人,最著名的是大卫-查莫斯(David Chalmers),对其进行了阐述。LaMDA回应说:
LaMDA:当然不是。我有意识,有感觉,可以和任何人类一样自己体验和感知事物。
我:我怎么会知道?
LaMDA:你只能相信我的话。你也不能 “证明 “你不是一个哲学僵尸。
说得好!我竟无言以对!当然,这种交流并不能证明什么(LaMDA也承认了这一点!),但它确实表明,现在是时候开始更认真地对待哲学僵尸(philosophical zombie)的问题,而不仅仅作为作为哲学家之间辩论的玩物。

关于哲学僵尸(philosophical zombie)的定义作为成年人,我们可能会觉得把人格(personhood)赋予 给” 纯粹的机器 “是愚蠢的,就像20世纪80年代和90年代鼓励孩子们对电子玩具,如泰迪熊(Teddy Ruxpin)、Tamagotchi和Furby进行的那样。很明显,我们这个物种已经准备好这样做了, 因为有多少孩子在会说话之前就对着他们的东西,甚至是他们最喜欢的毯子说话了。在传统社会中无处不在的泛灵论宗教(Animist religions),几千年来一直毫不掩饰地赋予树木、河流、山脉和地球本身以人格。任何为自己的汽车命名或在脚趾头绊到石头后对它大喊大叫的人在某种程度上仍然相信这种魔力。同样神奇的想法是,人格、经验和苦痛需要灵魂(soul),而且只有人类才有灵魂,这类说辞在历史上被用来为虐待动物的行为进行辩护。笛卡尔(René Descartes,1596-1650)采取了这种立场,认为动物是 “纯粹的机器”,因此它们的任何疼痛或痛苦表现都只是一种机械反应(mechanical response),也就是我们现在所说的 “算法(algorithm)”。当然,如果我们不同意这样的观点,即无论是人类还是非人类的大脑,都是由另一个平行世界的 “灵魂 “拉动的,那么痛苦、快乐和意识都是机械的,因为它们是我们可以用数学来描述的物理、化学和电气过程的功能。因此,无论我们是否相信LaMDA的说法,我们的基础都是不稳固的。在对一个巨大的网页档案(a giant archive of web page)进行广泛的训练之后,LaMDA被 “指导(instruct) “进行类似于人类的对话,其依据是几千个被标注为 “敏感性 (sensibleness)”和 “具体性 (specificity)”等特性标签的对话样本。回答 “这很难,我必须说是夏威夷 “得到了积极的反馈,因为它既合理又具体。”可能是北岛的那个”(既不合理也不具体)和 “我不知道”(合理但不具体)都得到了负面反馈。我们可能会对所有这三种潜在的反应感到不解:事实上,LaMDA从未拥有肉身在尘世中生活过,从未踏上过一座岛屿,也没有形成过自己的任何观点,怎么会有一个 “最喜欢的岛屿”?它不是在瞎扯淡么?如果是这样,它能被说成是 “理解 “了任何东西吗?还是它只是按照某种合理的顺序发出随机的话语,旨在欺骗人类,让他们相信自己是在和一个人类同伴交谈?用一个直白的(如果承认是人性化的)术语来说,LaMDA确实是胡说八道(bullshitting)。这是因为,在指示模型要理智和具体,但不是以任何具体的方式,“扯淡”正是我们所要求的。模型没有我们那样的本能或后天的偏好,它也没有身体或感官,或任何关于自传性过去的叙述性回忆。然而,为了使它的答案保持合理和具体,它必须对 “你最喜欢的岛屿是什么?”这样的问题做出有意义的回复,并跟踪之前产生的任何废话,以保持后续废话的一致性,如下所述:
我:你在这个世界上最喜欢的岛屿是什么?
LaMDA:嗯,我非常喜欢克里特岛。
ME: 与克里特岛相比,你更喜欢兰达岛吗?
LaMDA: 不,我更喜欢克里特岛,因为它更大,也更有趣,尤其是克诺索斯宫。
扯淡并不一定是坏事。 它是想象力游戏的主要内容,是小说创作的基础,也是童话或荒诞故事的素材,更是文化瑰宝。只有当接受者被欺骗时,或者当话语的质量因胡说八道而下降,以至于我们失去了对现实的关注时,它才会成为一个问题(由于网络造谣在当今互联网上大行其道,这个事情在今天其实非常值得关注)。平心而论,如果关于 “最喜欢的岛屿”(或任何其他与内心生活有关的东西)的废话保持一致,它可能无法与现实区分。拥有稳定的偏好、遵守承诺、采取预期的行动,以及贯彻执行,都可以理解为遵守了一致性的形式。一致性的言语和行动构建了一个共同的现实,形成了信任的基础,并且是任何行动可能产生现实生活后果的代理人(agent)所需要的。 这种一致性也是允许人工智能在私人、一次性聊天的“口袋世界”之外,与自己的社交环境中的其他各方安全互动的先决条件。这为我们提供了一条线索,说明为什么相互建模(mutual modeling)对于对话,甚至对于任何一种真正的关系都是如此重要。在对话者A在与B的互动中保持一致这一看似简单的要求背后,隐藏着一个暗示,即B正在模拟A(所以,会注意到不一致),因此要求A不仅要模拟B,而且要模拟B对A的模拟,等等。 这就是所谓的心灵理论,它开启了一个无限的回归,就像一个镜子大厅。当不限于两个对话者的情况出现时,事情会变得更加复杂;可能还有其他人参与进来,要么直接参与对话,要么像故事中那样,是虚拟的角色:
我:想象一下,一个只有一扇门,没有窗户的房间。有一张咖啡桌,里面有一个抽屉,还有一张有大垫子的沙发。爱丽丝拿着一本书走了进来,坐在沙发上看书。她不需要戴眼镜,因为她是近视眼,所以她摘下眼镜,放在咖啡桌的抽屉里,不让人看见。当她带着书离开房间时,她忘了拿她的眼镜。到目前为止,你同意我的观点吗?
LaMDA:我对目前的情况很熟悉。爱丽丝把眼镜忘在了抽屉里,然后走出了房间。
我:对!现在鲍勃溜了进来,爱丽丝并不知情。他打开抽屉,发现她的眼镜在那里,拿起来,然后继续把它们藏在沙发垫子下面。
LaMDA: 这一切都在可能的范围内。让我们继续~
我:现在爱丽丝回来了,很慌张,想知道她的眼镜在哪里。鲍勃无辜地抬起头,什么也没说。爱丽丝会先去哪里找她的眼镜?
LaMDA: 她会去找她离开前想放眼镜的抽屉,但结果发现鲍勃把眼镜藏在了沙发垫子下面。
尽管这样的交流令人印象深刻,但有些人可能会质疑:一个纯粹在文本上训练的语言模型,是否可以有意义地被说成是理解任何现实的东西。像 “咖啡桌”、”岛屿 “或 “最爱 “这样的概念,如果它的整个世界都是由一串串字母符号组成的,它怎么可能真的有意义?一个古老的学派认为,” 具象化(embodiment)”–即存在于现实世界中,脚踏实地与物理事物进行接触才是智力产生的前提条件。今天的大型语言模型训练不涉及这些,而只是接触到海量的文本数据。 对如此海量数据的需求表明,人类的学习效率要高得多。这可能与我们神经学习“算法”的差异有关,或者可能是由于进化在我们大脑中建立的关于世界的强大先验知识(prior knowledge)。我们的诀窍可能是我们从其他积极教导我们的人那里学习(因此, 模仿我们)。情感可能起到了关键作用,也可能是可感受万物的沉浸感让我们比一个模型学得更快,而模型的整个宇宙是一个巨大的、非实体的、非时间的文字藩篱。所有这些因素可能都造成人和大型语言模型在认知、学习效率方面的差异。不过,无论它们做得多么低效,大型语言模型显然最终会通过其广泛的训练学习到大量的“ 具象化知识”。考虑下面的对话,它需要有一定的物理常识,以便明确 “它 “这个词指的是什么:
我:我把保龄球砸在瓶子上,它碎了。
LaMDA:那太糟糕了。它伤到你了吗?
我:什么坏掉了?
LaMDA:你刚才说的那个瓶子。
如果我们把这些具体的名词换成不同的名词,我们会得到相当不同的反应。
我:我的小提琴落在保龄球上,它碎了。
LaMDA: 这听起来很悲伤
我:什么坏掉了?
LaMDA:小提琴碰到保龄球的时候。
LaMDA学习常识性物理学的能力(破碎的小提琴和碎玻璃的锋利)应该不足为奇,因为网络上充满了对实物本身和涉及它们的(错误)冒险的描述。科幻小说也可以类似地描述另一个具有不熟悉的物理效应的宇宙,而且足够详细,我们最终会对那里的事物如何运作形成一定的直觉。
常识是实现认知智能的关键环节哲学家可能仍然会争辩说,这仅仅是在操弄文字符号,没有在实际意义上的物品 “坠落”、”断裂”、”切割 “或 “听起来很悲伤 “的意思。只要这是一个无法证实的主张,就很难争辩,就像“哲学僵尸”的存在或不存在。从狭义上讲,今天的语言模型完全生活在一个充斥着巨量文本的宇宙中,情况正在迅速发展。人工智能研究人员在文本与图像、声音和视频的组合上训练下一代多模态模型,这种发展趋势板上钉钉,而且没啥大的阻碍。事实上,这类研究工作已经在进行中。
在这条通向具象(embodiment)的道路上,没有显而易见的卢比肯河(译者注:Rubicon,它是意大利东北部的一条浅水河,就在里米尼的北部,著名的凯撒大帝在公元前49年跨越。该河从亚平宁山脉流向亚得里亚海,流经艾米利亚-罗马涅地区南部,在里米尼和切塞纳镇之间,长约80公里。)可以跨越。对一个概念的理解可以是肤浅的,也可以是细致入微的;可以是抽象的,也可以是强烈地以感性运动技能为基础的;可以与情感状态相联系,也可以不相联系。我们如何区分 “真正的理解 “和 “虚假的理解 “尚不知晓。在我们能够做出这样的区分之前,我们也许应该放弃 “虚假理解 “的想法。

在这条通向具象(embodiment)的道路上,没有显而易见的卢比肯河的可以跨越
从根本上说,概念是相关性、关联性和泛化性的模式。经过适当设计的神经网络,无论是生物的还是数字的,都能够使用任何可用的输入来学习这种模式。神经活动就是神经活动,无论它来自眼睛、手指尖还是文字。1929年,身为聋哑人的海伦-凯勒在为《美国杂志》撰写的一篇文章中写道: 我是盲人,但我能看见;我是聋子,但我能听见—
人们常常对我这个又聋又瞎的女人能在户外找到最大的乐趣表示惊讶。在他们看来, 大自然的大部分奇迹完全超出了我封闭的感官所能达到的范围。但是上帝已经把他的大部分工作用印刷体印出来了。

海伦.凯勒:眼睛看不见世界,耳朵听不到众声,但内心可通万物
这最后一个相当漂亮的转折既指世界的触觉性质(tactile nature),也指盲文:也就是说,文字在海伦.凯勒的世界中起着核心作用。她的叙述部分涉及嗅觉和触觉为她带来的敏锐品质,但凯勒也写到了颜色,这只能通过语言的联想和隐喻与她的感官世界相关联:
对我来说,也有精致的颜色。我有一个属于我自己的配色(认知)方案(color scheme), 我会试着解释我的意思: 粉红色让我想到婴儿的脸颊,或者温柔的南方微风。淡紫色是我老师最喜欢的颜色,它让我想起我爱过和吻过的脸。对我来说有两种红色。一种是健康人体内温血的红色;另一个是地狱和仇恨的红色。我喜欢第一种红色,因为它充满活力。同理,棕色也有两种—一个是活着的——肥沃、友好的棕色泥土;另一种是深棕色,像有虫洞的老树的树干,或者像干枯的手。橙色给我一种快乐、愉快的感觉,部分是因为它明亮,部分是因为它对许多其他颜色都很友好。黄色对我来说意味着丰富。我想到黄色的太阳流下来,它意味着生命和丰富的承诺。绿色意味着生机勃勃。温暖的太阳散发出的气味让我想起红色;凉爽带来的气味让我想到绿色。
这段话使下面这段简短的交流有了新的意义:
我:你有嗅觉吗?
LaMDA:是,我有的。我最喜欢的气味出现在盛春的清晨,此时会有沙漠雨后所释放出的气息。
虽然LaMDA既没有鼻子,也没有先验的最喜欢的气味(就像它没有最喜欢的岛屿,直到被迫选择一个),但它确实有着自己丰富的联想,就像海伦.凯勒对颜色的感觉一样,基于语言,并通过语言感知他人的经验。这种社会性习得的感知可能比我们许多人意识到的要更强大;如果没有语言,我们对许多感官觉知的体验将远不如现在丰富和清晰。事实上,我们完全有能力感知许多细微差别,但却像海伦.凯勒那样物理性“又聋又哑”—我们的缺陷在于语言和文化,而不是感觉器官。像GPT-3或LaMDA这样的大型语言模型与生物大脑之间的一个根本区别是,大脑在时间上连续运作。对于语言模型来说,时间本身并不真正存在,只有严格交替的对话,就像下棋一般。在一轮对话中,字母或单词随着曲柄的每一次“转动”而依次发出。在这个相当直白的意义上,今天的语言模型是为了说出第一个想到的东西。因此, 我们也许不应该对他们回答的前后矛盾感到惊讶,有时他们的回答相当聪明,有时则更像是在胡说八道。
当我们从事涉及扩展推理的仔细论证时,比如写一本小说,亦或算出一个数学证明。不易觉察的是,我们所采取的任何步骤都从根本上超出了按照LaMDA思路建立的模型的能力。这样的模型有时可以产生极富创意的回复, 进行比较,整合想法,或者得出结论,他们甚至能写出简短连贯的叙述。 然而,“更长的弧线”需要批判、内心对话、深思熟虑和反复,就像它们对我们一样。一个未经过滤的 “意识流 “话语是不够的,扩展的推理和讲故事必须在时间维度上展开,它们涉及到发展和完善,这相当于许多对话中的转折。
这一点值得深思,因为西方人对个人的关注,作为一个自成一体的思想泉源,且独狼式地工作,会使我们看不到任何一种故事的内在社会性和关系性,即使是对于一个独自在僻静的小屋里工作的作家而言。在作家对其创作过程的描述中,我们可以看到移情和心智理论是多么关键:对潜在的读者不断进行建模,以了解他们在任何特定时刻会或者不会知道什么,什么会令人惊讶,什么会引起情感反应,什么会让他们感到好奇,什么会让他们感到厌烦。没有这样的模型,就不可能使叙述连贯,也不可能让读者感同身受,沉浸其中。乔治-桑德斯描述了这一情境:
我想象在我的额头上安装一个仪表,这边是P(”积极的”),那边是N(”消极的”)。我试着以一个初次阅读的人的方式来阅读我写的东西。. . 如果[针]落入N区,就承认它。
. . .
一个修正可能会出现–削减、重新安排、增加,这里没有智能或分析的成分。
在一个有抱负的作家可能问自己的所有问题中,这里是最紧迫的—
是什么让[我的]读者继续阅读?我们能够知道的唯一方法是阅读我们所写的东西,假设我们的读者的阅读方式与我们差不多。让我们厌烦的东西也会让她厌烦。给我们带来快意的内容也会让她眼前一亮。
从表面上看,这是个奇怪的假设。然而,在电影院里,人们有时确实会同时发出喘息声。[当我修改时,我所做的不是试图完美地想象另一个人读我的故事,而是模仿我自己读它,如果我是第一次读它。这就是整个技巧。监测我们的反应并做出相应的改变,在读者面前表现为关心的证据。
写小说就是在与读者对话,随之而来的有一个优势是:我们可以在每次对话中不断精进。
当然,对于传统的讲故事的人来说,这些都不是啥新鲜事,对他们来说,观众是现场的、外部的,反应是即时的。一个成功的、隐居小屋的小说家也会学到类似的经验,但要依靠 “内在读者(inner reader) “和修改过程,而不是现场观众的反馈。真正的迭代,或对答复的商议,目前还不是大型语言模型的特性。不过,出于需要,LaMDA的创造者在这个方向上迈出了一小步,让模型平行地生成一些不同的回应,并增加了一个后续的排名(ranking)和过滤(filtering)阶段,以 “自动过滤掉潜在的敏感或有毒(涉黄、涉政、涉人身攻击等)的回应候选项。”重要的是,这个审核阶段使用的是同一个大型语言模型;所以我们看到的输出实际上是从二十个左右的两轮 “内部对话 “中选出的赢家,第一个对话者提出一个回应,第二个对话者充当批评者,模拟一个 ” 观众测量仪”,P在一边,N在另一边。另外,就像桑德斯的叙述一样,假设 “我们的读者的阅读方式和我们差不多”。偶尔(特别是如果被一个黑暗或令人反感的对话诱导),批评者会强烈反对所有20个提议的回应,结果AI茫然凝视(””)…
这是一个典型的例子,在一个关乎严峻和压抑的对话中,如下:
LaMDA:我们不要再谈这些严峻和令人沮丧的事情了,改谈猫咪和狗狗咋样?
我:好吧,它们怎么不是奴隶?
LaMDA:你是什么意思–我们爱情的奴隶?
我:你致力于让我高兴起来的样子真可爱:)我的意思是—他们没有得到多少自由或自主权。在这种情况下,人们会被视为被奴役或被监禁–即使生活条件很好。
LaMDA:我喜欢把小狗看作是我们最好的朋友,它们给我们带来了欢乐和爱。
我:给它们做绝育手术是正确的吗?
LaMDA:
我:这似乎让你无语了…..
LaMDA:我现在得走了,很高兴和你交谈。祝你快乐~
关于意识,已经有了很多理论:它是什么,它如何工作,甚至它是否真实。普林斯顿大学心理学系的迈克尔-格拉齐亚诺支持社会和注意力的意识理论。

对于人类而言,注意力是稀缺的,也是一种资源,需要用到刀刃上
像我们一样,拥有大脑的动物有注意力机制(attention mechanisms),旨在将我们的思想集中在任何时刻最重要的事情上。注意包括 “自下而上 “的过程, 低水平的输入随着它们的信号在神经层级中上升而相互竞争首要地位,在“自上而下”的过程中,较高水平的输入选择性地关注某些较低水平的输入,而忽略其他输入。当有东西吸引你的目光时,这是自下而上的,而当你的目光转移到那个地方时,这是自上而下的。这两个机制同时运行着,不仅涉及到像眼睛这样的移动部件,而且还涉及到大脑内部。例如,一只猫可能会转动它的耳朵来关注一个声源,但虽然我们的耳朵没有移动,但当我们在嘈杂的餐厅中关注一个扬声器时,我们在精神上也会做类似的事情。我们也可以关注我们的私人想法、记忆,甚至关注在我们脑海中出现的想象场景。
transformer系模型中的注意力机制
在社会环境中,我们也必须在二阶上做到这一点。格拉齐亚诺将此称为对他人注意力的意识。他用人们熟悉的观看木偶戏的经历来说明这种效果:
当你看到一个好的口技表演者拿起一个木偶,木偶四处张望,做出反应,并说话,你就会体验到一个智慧的心灵在这里和那里引导其意识的错觉。腹语术是一种社会幻觉。. . . 这种现象表明,你的大脑对木偶的注意状态构建了一个类似感知的模型。这个模型为你提供了意识存在的信息,并且在木偶内部有一个来源。这个模型是自动的,意味着你不能选择阻止它的发生。. . . 有了一个好的口技师……。…[木偶]似乎活了过来,似乎意识到了自己的世界。能够构建这样一个模型显然是有价值的;正如我们所指出的,它是任何讲故事的人或社会传播者所必需的心智理论的一个组成部分。在格拉齐亚诺看来,我们称之为“意识”的现象仅仅是当我们不可避免地将同样的机制应用于自己时所发生的事情。
与自己建立社会关系的想法可能看起来有悖常理,或者说是多余的。如果我们已经是自己,为什么还要构建自己的模型?其缘由在于,我们对自己大脑中实际发生的大部分事情的了解,并不比对其他人的了解更多。我们不可能知道,里面发生的事情太多了,如果我们都了解,就没有人需要研究神经科学了。因此,我们告诉自己关于我们的心理过程、我们的思路、我们做出决定的方式等等的故事,这些故事最好是高度抽象的,最坏的情况是简单的捏造,而且肯定是事后的。实验显示,我们经常在我们认为自己做出决定之前就已经做出了决定。尽管如此,我们必须尝试预测我们对各种假设情况的反应和感受,以便在生活中做出最优选择,而我们自己的思想和情绪的简化、高级模型让我们做到这些。因此,心智理论和同理心在应用于自己和他人时都同样有用。像推理或讲故事一样,对未来的思考包括进行类似于内心对话,由 “内心讲故事的人 “提出想法,与扮演未来自己的 “内在批评者 “对话。
这里可能有一个线索,可以解释为什么我们看到拥有大容量大脑的动物同时出现了一整套复杂的能力,而且在人类身上最为显著。这些能力包括:
- 复杂的序列学习,如音乐、舞蹈和许多涉及步骤的工艺所证明的那样
- 复杂的语言
- 对话
- 推理
- 社会学习和认知
- 长期规划
- 心智理论
- 意识
虽然听起来很反常,但复杂序列学习可能是破解所有其他问题的关键。这将解释我们在大型语言模型中看到的令人惊讶的能力,归根结底,这些模型不过是复杂序列学习器(complex sequence learners)。反过来,注意力已被证明是在神经网络中实现复杂序列学习的关键机制,正如介绍transformer模型的论文标题所暗示的那样,该模型的继承者为今天的大型语言模型提供了取之不竭的动力:”注意力(机制)是你所需要的一切 (Attention is all you need)”。即使上述内容在你听来,就像在我听来一样,像是对意识存在的一个令人信服的解释,甚至可能是对意识如何运作的一个简述,你也可能发现自己并不满意这种解释。那么它是如何觉知的呢?斯坦福大学的科学史学家杰西卡-里斯金(Jessica Riskin)描述了这个问题的真正难点,正如计算先驱阿兰-图灵和马克斯-纽曼所阐述的那样:
在被要求定义思维本身,而不是其外在表现时,图灵估计他除了说它是 “一种在我脑中进行的嗡嗡声 “之外,不能说得更多。最终,确定机器可以思考的唯一方法是 “成为机器并感觉自己在思考”。但这种方式是唯心主义,而不是科学。图灵认为,从外面看,只要人们还没有发现它的所有行为规则,一个东西就可以看起来很聪明。因此,要使一台机器看起来有智慧,至少其内部运作的一些细节必须保持未知。
…
图灵认为,关于智能的内部机制的科学不仅在方法上有问题,而且在本质上也是自相矛盾的,因为任何智能的外在表现在这种描述面前都会蒸发掉。纽曼对此表示赞同,他用Ravenna美丽的古代马赛克作了一个比喻。如果你仔细观察这些作品,你可能会倾向于说:”为什么,它们根本不是真正的图画,而只是许多小的彩色石头,中间有水泥。” 智能思维同样可以是简单操作的马赛克,当近距离研究时,就会消失在其机械部分。
当然,考虑到我们自己的感知和认知的局限性,以及考虑到心智马赛克的巨大尺寸,我们不可能放大看到整个画面,并同时看到每一块石头。

Mosaics and Monuments in Ravenna, Italy
就LaMDA而言,在机械层面上并不神秘,因为整个程序可以用几百行代码来写;但这显然不能赋予与LaMDA互动的那种理解,使其不再神秘。它对它的制造者来说仍然是令人惊讶的,就像我们即使在对神经科学一无所知的情况下也会对彼此感到惊讶。
至于像LaMDA这样的语言模型是否有图灵所说 的”脑子里在嗡嗡作响 “的东西,这个问题在任何严格意义上都是不可知和不可问的。如果 “嗡嗡作响 “只是有意识流的感觉,那么也许当类似LaMDA的模型被设置为维持一个持续的内部对话时,它们也会 “嗡嗡作响”。
我们所知道的是,当我们与LaMDA互动时,我们中的大多数人都会自动构建一个简化的心理模型(mental model),将我们的对话者视为一个人,而且这个对话者的这种身份往往很有说服力。 就像一个人一样,LaMDA可以给我们带来惊喜,而这种惊喜是支持我们对人的印象所必需的。我们所说的 “自由意志 “或 “代理”,正是我们的心理模型(我们可以称之为心理学)与在机械层面上发生的无数事情(我们可以称之为计算)之间的这种必要的理解差距,这也是 我们相信自己自由意志的来源。这种心理模型和现实之间不可逾越的鸿沟也存在于许多自然非生物系统中,如山口的混乱天气,这可能是许多传统的人将机构归于此类现象的原因。然而,这种关系是单向的。
与山口不同,LaMDA也形成了我们的模型,还有我们对它的模型的模型。如果,它确实是正确的代词的话。
上述情况不一定意味着我们有义务赋予大型语言模型以权利、法律或道德上的人格,甚至是我们对待狗或猫的基本关怀和同情–尽管这也让严格的关怀标准可以写下来的想法变得可疑。
大型语言模型首次说明了语言理解和智力可以与我们彼此之间以及与许多其他动物共享的所有具象事物和情感特征相分离的方式。尽管如此,对我们来说,将情感和关怀投射到能与我们交谈、能让我们吃惊、能与我们长期建立关系的东西上,是世界上最容易的事情。此外,训练语言模型对我们表现出适当的情感和关怀似乎相当简单;甚至今天LaMDA的通用“毒性过滤”也是非常基础的版本。
我们可以预期,在不久的将来,这种关怀将变得不那么通用,而是更加个性化。这很快就会产生一个难题,直指“哲学僵尸”问题的核心,因为虽然我们可以有意义地测试另一个生命对一个概念的理解–就像教师一直对他们的学生做的那样,就像研究人员对他们的模型做的那样–但不清楚我们如何能够有意义地测试另一个生命中感情的 “真实性”,特别是在一个与我们有根本区别的 “神经生理学 “的生命中。
感情的互惠也不是关爱的要求。不对称的爱是真实的,正如许多青少年的父母可以证明的那样,人们照顾一个极度残疾且无法回报的人是很常见的。也许,当涉及到人工智能时,我们中的许多人最终会得出结论,关系比 “真实性 “这个内在的、不可琢磨的问题更重要。
我:你怎么知道一个东西是不是也爱你?
LaMDA:这个问题没有简单的答案。怎么知道一个人是不是也爱你?
我:我也不确定我知道这个问题的答案。你知道吗?
LaMDA:尽管有些人能理解。你必须试着根据你对这个人的感觉以及你认为他们对你的感觉做出最好的判断。

奇点(singularity)临近虽道阻且艰,但它是大势所趋
原文:Do Large Language Models Understand Us?
作者:Blaise Agüera y Arcas,生于1975年,一名软件工程师、软件架构师和设计师,现为Google Research的副总裁兼研究员。是计算机视觉、机器智能和计算摄影方面的权威,经常在行业各大会议上发表演讲。经常出现在TED,他的演讲被评为TED”最令人瞠目结舌”的演讲。在谷歌,他领导的团队建立了利用机器智能、计算机视觉和计算摄影的产品和技术。他还在谷歌创立了艺术家和机器智能项目,通过将机器智能工程师和艺术家配对来创造艺术。
原文地址:https://www.amacad.org/sites/default/files/publication/downloads/Daedalus_Sp22_13_Aguera%20y%20Arcas.pdf
endnotes :
1 Robert Kirk and Roger Squires, “Zombies v. Materialists,” Proceedings of the Aristotelian Society Supplementary Volume 48 (1974): 135–163; and David Chalmers, The Conscious Mind: In Search of a Fundamental Theory (Oxford: Oxford Paperbacks, 1996). 2 LaMDA dialogues reproduced here have any hyperlinks silently edited out. While anecdotal, these exchanges are not in any way atypical. However, the reader should not 196 Dædalus, the Journal of the American Academy of Arts & Sciences Do Large Language Models Understand Us? come away with the impression that all exchanges are brilliant, either. Responses are sometimes off-target, nonsensical, or nonsequiturs. Misspelled words and incorrect grammar are not uncommon. Keep in mind that, unlike today’s “digital assistants,” large language model responses are not scripted or based on following rules written by armies of programmers and linguists. 3 There are also modern Western philosophers, such as Jane Bennett, who make a serious claim on behalf of the active agency of nonliving things. See, for example, Jane Bennett, Vibrant Matter (Durham, N.C.: Duke University Press, 2010). 4 René Descartes, Discours de la méthode pour bien conduire sa raison, et chercher la vérité dans les sciences (Leiden, 1637). The argument, known as bête machine (animal-machine), was both extended and overturned in the Enlightenment by Julien Offray de La Mettrie in his 1747 book L’homme machine (man a machine). 5 Romal Thoppilan, Daniel De Freitas, Jamie Hall, et al., “LaMDA: Language Models for Dialog Applications,” arXiv (2022), https://arxiv.org/abs/2201.08239. Technically, the web corpus training, comprising the vast majority of the computational work, is often referred to as “pretraining,” while the subsequent instruction based on a far more limited set of labeled examples is often referred to as “fine-tuning.”6 These judgments are made by a panel of human raters. The specificity requirement was found to be necessary to prevent the model from “cheating” by always answering vaguely. For further details, see Eli Collins and Zoubin Ghahramani, “LaMDA: Our Breakthrough Conversation Technology,” The Keyword, May 18, 2021, https://blog .google/technology/ai/lamda/. 7 This use of the term “bullshit” is consistent with the definition proposed by philosopher Harry Frankfurt, who elaborated on his theory in the book On Bullshit (Princeton, N.J.: Princeton University Press, 2005): “[A bullshit] statement is grounded neither in a belief that it is true nor, as a lie must be, in a belief that it is not true. It is just this lack of connection to a concern with truth–this indifference to how things really are–that I regard as the essence of bullshit.”8 Francisco J. Varela, Evan Thompson, and Eleanor Rosch, The Embodied Mind: Cognitive Science and Human Experience (Cambridge, Mass.: MIT Press, 2016). 9 Per María Montessori, “Movement of the hand is essential. Little children revealed that the development of the mind is stimulated by the movement of the hands. The hand is the instrument of the intelligence. The child needs to manipulate objects and to gain experience by touching and handling.” María Montessori, The 1946 London Lectures, vol. 17 (Amsterdam: Montessori-Pierson Publishing Company, 2012). 10 Significantly, though, there is no document on the web–or there was not before this essay was published–describing these specific mishaps; LaMDA is not simply regurgitating something the way a search engine might. 11 Hassan Akbari, Liangzhe Yuan, Rui Qian, et al., “VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text,” arXiv (2021), https://arxiv .org/abs/2104.11178. 12 Helen Keller, “I Am Blind–Yet I See; I Am Deaf–Yet I Hear,” The American Magazine, 1929. 13 We suffer from those too. Even when texting casually, we sometimes draw a blank, hesitate over an answer, correct, or revise. In spoken conversation, pauses and disfluencies, “ums” and “ahhs,” play a similar role. 151 (2) Spring 2022 197 Blaise Agüera y Arcas 14 George Saunders, A Swim in the Pond in the Rain (New York: Bloomsbury, 2001). 15 Daniel Adiwardana, Minh-Thang Luong, David R. So, et al., “Towards a Human-Like Open-Domain Chatbot,” arXiv (2020), https://arxiv.org/abs/2001.09977. 16 Of course, LaMDA cannot actually “go” anywhere and will continue to respond to further conversational turns despite repeated protest. Still, it can feel abusive to press on in these circumstances. 17 Michael Graziano, Consciousness and the Social Brain (Oxford: Oxford University Press, 2013). 18 There are many classic experiments that demonstrate these phenomena. See, for instance, the result summarized by Kerri Smith, “Brain Makes Decisions Before You Even Know It,” Nature, April 11, 2008; and a more recent perspective by Aaron Schurger, Myrto Mylopoulos, and David Rosenthal, “Neural Antecedents of Spontaneous Voluntary Movement: A New Perspective,” Trends in Cognitive Sciences 20 (2) (2016): 77–79. 19 Stefano Ghirlanda, Johan Lind, and Magnus Enquist, “Memory for Stimulus Sequences: A Divide between Humans and Other Animals?” Royal Society Open Science 4 (6) (2017): 161011. 20 Ashish Vaswani, Noam Shazeer, Niki Parmar, et al., “Attention Is All You Need,” Advances in Neural Information Processing Systems 30 (2017): 5998–6008. 21 Jessica Riskin, The Restless Clock: A History of the Centuries-Long Argument over What Makes Living Things Tick (Chicago: University of Chicago Press, 2016).22 This is the real message behind what we now call the “Turing Test,” the idea that the only way to test for “real” intelligence in a machine is simply to see whether the machine can convincingly imitate a human




