
目前,在语句编码器(sentence encoders)领域的学术研究相当多,刚开始涉足的话,可能有点令人生畏。如果你没有正确掌握语句编码器背后的理念和其中的细微差别,就很容易感到困惑。
例如,你可能知道存在sentence transformer(bi-encoders),它们的目的是为句子级别的任务产生高质量的嵌入(qualitative embeddings)。但话说回来,普通的 transformer编码器也能产生较高质量的嵌入,并且完全适合句子级任务。transformer和与之对应的sentence transformer背后的架构似乎也是相同的。然后,还有交叉编码器(cross-encoders)——它也被用于执行句子级的文本分类/回归任务。
这些疑问正是我们在笔者要在本文中所要阐明清楚的问题。
读完本文,你应该会对什么是 sentence transformer、双编码器(bi-encoders)和交叉编码器(cross-encoders)、何时使用它们以及它们与普通的transformer(regular transformers)的关系有一个非常清楚的了解。
01 为什么需要sentence transformers?
一言以蔽之:
“sentence transformer能产生比普通transformers更好的语句语义表示,以支持某些特定的句子级的下游任务,如语义检索、文本聚类、论据挖掘等。”
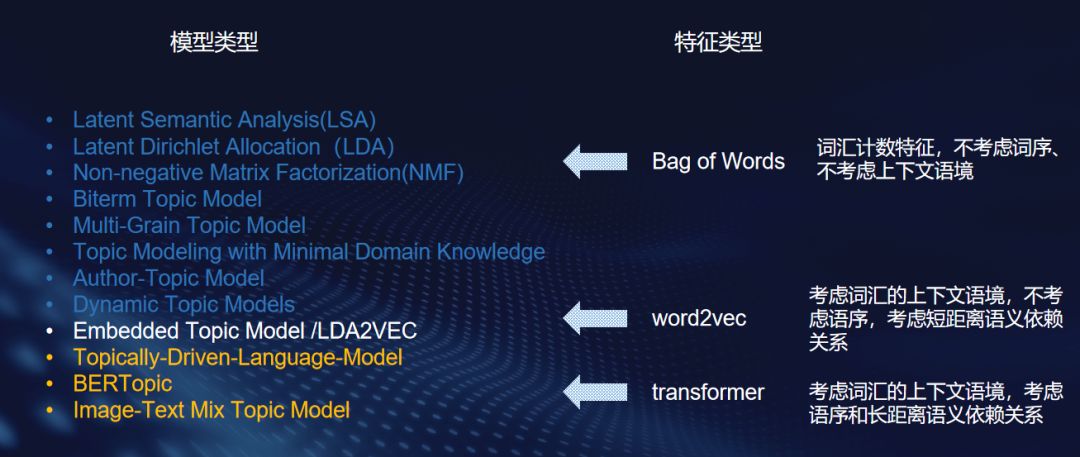
详情见 知乎.主题模型(topic model)到底还有没有用,该怎么用?,苏格兰折耳喵,https://www.zhihu.com/question/34801598
语句的表示学习模型从较早期的词袋模型到静态预训练模型,再到如今的动态的语境预训练模型,对于句子语义信息的编码由“低保真”逐渐过渡到“高保真”状态。
在实际应用场景中,低保真还是高保真并没有优劣之分,选型完全取决于使用场景和具体需求。某个语义表示模型很可能非常适用于一个特定的使用场景,但在另一个使用场景下就没啥作用了。我将通过一个示例进行说明。
请考虑以下说辞:”从此边城多战伐,不须笳鼓更悲凉”和 “投身革命即为家,血雨腥风应有涯”。那么,问题来了,这两条诗句是否应该被认为是相似的,也就是说,上述2个语句嵌入是否应该在语义空间中相互靠拢呢?
嗯,这取决于你的选择。如果你谈论的是主题,那么肯定是的—这两个语句都是关于“战争残酷”的内容,在这个意义上,它们是非常相似的。然而,如果你谈论的是情感,那么答案是不言而喻:前一句明显是悲伤的消极的情感,后一句是革命乐观主义的积极情感,二者的情感倾向截然不同。
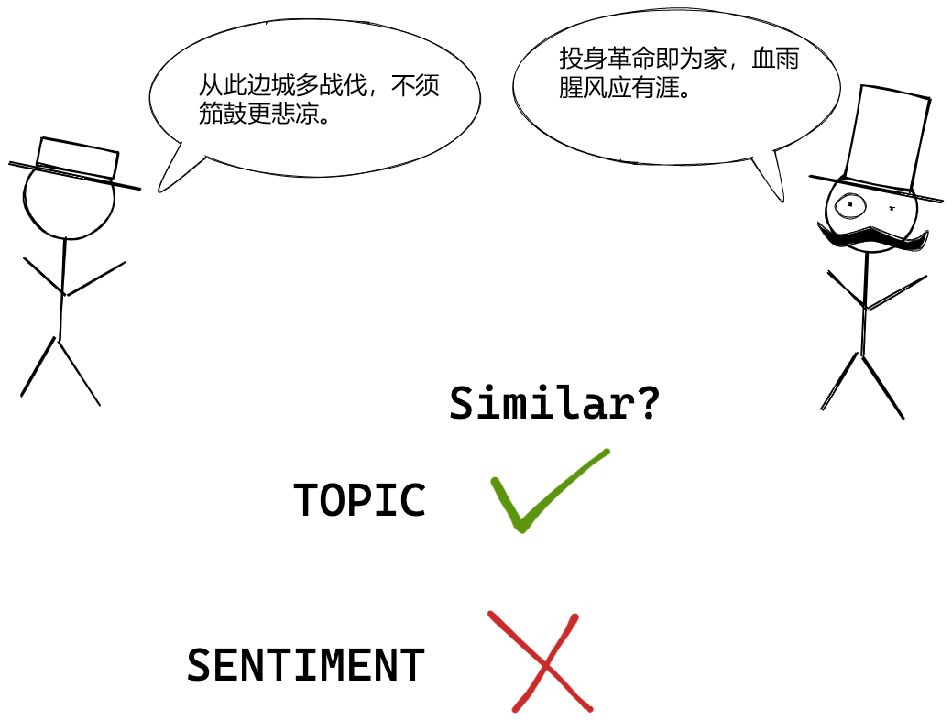
所有嵌入都是相同的,但有些嵌入比其他嵌入更相同
注意:这就是为什么大型的预训练语言模型需要在非常通用的、数据规模庞大的任务上训练(如遮蔽词语言建模)的原因,其内在逻辑是,经大规模通用语料训练得到的语句嵌入表示反映了模型对语言非常广泛的理解,以后可以根据具体的使用情况进行调整。
言归正传:” sentence transformers是否能产生更好的语句嵌入?”。答案也是不言而喻的,—需要视场景而定,做”具体问题,具体分析”!
常规的transformer模型通过执行一系列操作来产生句子嵌入,如对其token-level的嵌入的元素算术平均。BERT的一个很好的池化选择是CLS池化。BERT有一个特殊的<CLS>标记,它应该捕获所有的序列信息。在预训练期间,它被调整为对下一句的预测(NSP)。
注意 :RoBERTa在预训练试没有执行NSP任务,也没有<CLS>标记。它仅有一个句首<s>的标记,但嵌入没有经过训练,故无法描绘出有意义的句子表征,没法开箱即用~
由此产生的句子嵌入很适合于一些分类或回归任务,如果这是你接下来要做的任务,请直接使用transformers中的BertForSequenceClassification或其他模型类似的方法,它们的训练过程和使用方法都还不错。
然而,对于语义相似性任务来说,由常规的transformers获得的句子嵌入并不是很好。这就是sentence transformer大显身手的地方。sentence transformers的训练过程是专门针对语义相似性任务而设计的,笔者稍后会有更多关于训练过程的内容。
因此,综上所述:如果你想执行一些句子分类任务,普通的transformers就能胜任了。但是,如果你想要执行诸如语义检索、话题聚类等依赖于语义相似性的任务,你就应该将目光投向sentence transformers。
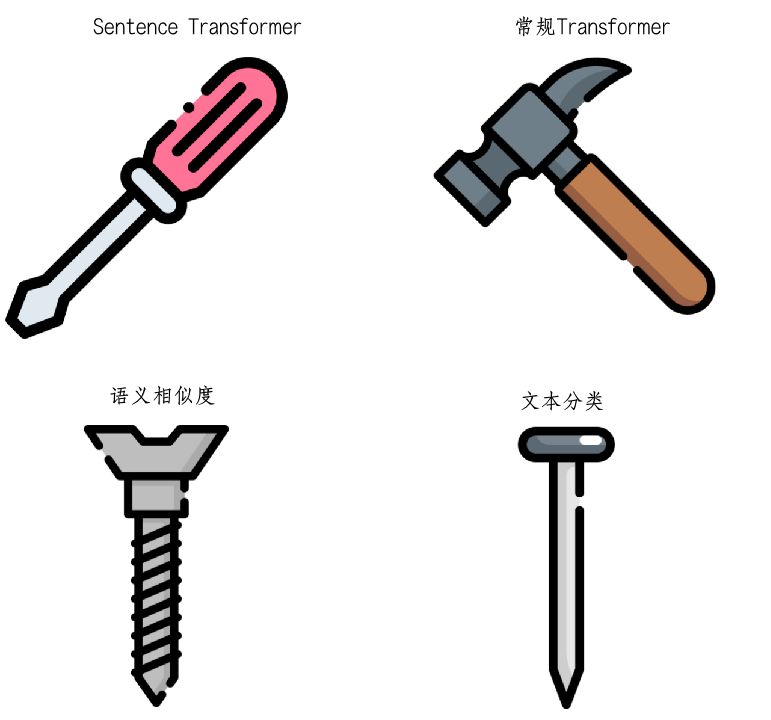
从实际出发选择合适的模型架构和训练方法是NLPer的必备技能
02 交叉编码器(Cross-encoders)
现在,好奇的你可能会问自己这样一个问题:
“难道不能把语义相似性问题转化为一个句子分类问题吗?也就是将两个句子分类拼接后,模型对其打上 “相关 “或 “不相关”的标签,而不是将所有这些句子进行单独编码。”
这样想是非常正确的,因为拼接后的句子之间语义还有交互,能最大限度的利用语句之间的语义信息,效果比单独编码句子后再进行相似度比较要好得多。事实上,这正是交叉编码器(cross-encoder)所做的。
从本质上讲,交叉编码器所做的是将两个句子通过分隔符<SEP>拼接起来,并将其“喂进”一个语言模型。在语言模型的顶部有一个分类头,用以训练来预测一个目标 “相似度 “数值。
因此,例如,交叉编码器会将 “我的狗很快 “和 “他有一个V8柴油发动机 “这两个句子连接起来,并预测一个低的相似性分数,尽管它们都包含与速度有关的词汇。这当然是正确的。每个人都知道,Snuffles的引擎盖下摇晃着一台V12 TDI,它确实是非常省油的。
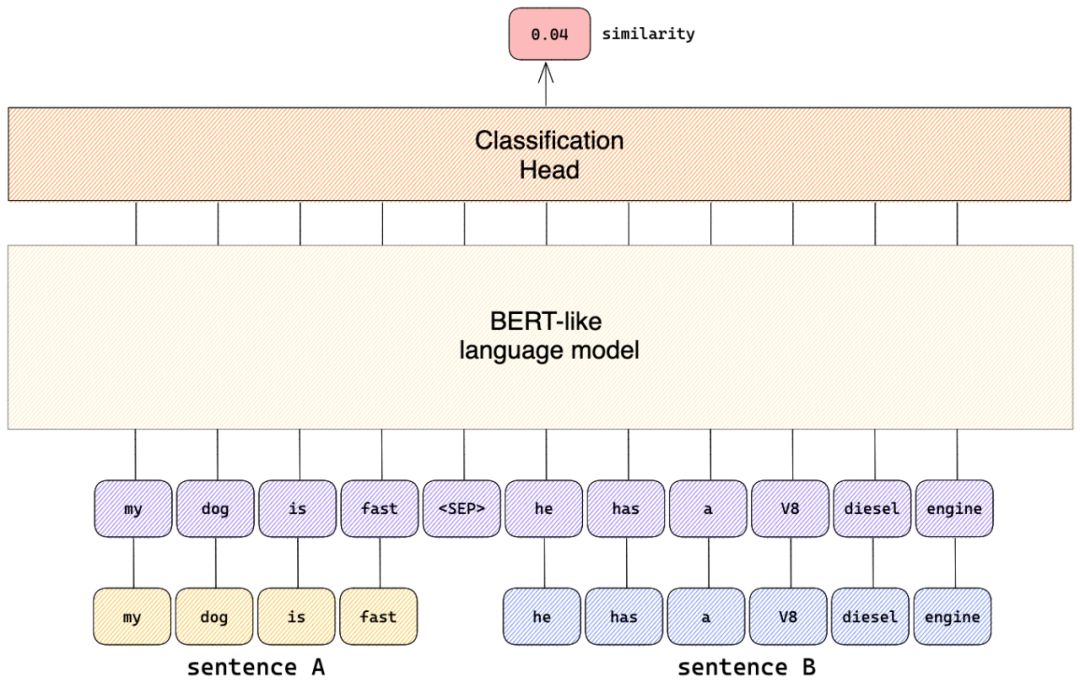
交叉编码器的架构
因此,交叉编码器通过句子对及表征其语义相似程度的基本事实标签(可能是离散的类别标签,或者是连续性的相似度数值)来进行有监督训练。

交叉编码器的训练数据样例
虽然交叉编码器在句子层面的任务上表现非常好,但它存在一个“致命”缺点:交交叉编码器不产生句子嵌入。
在信息检索的使用场景下,这意味着我们不能预先计算文档嵌入并将其与查询嵌入进行有效的比较。我们也不能对文档嵌入进行索引,以进行有效的搜索。
在句子聚类的背景下,这意味着我们必须将每一对可能的文档都传递给交叉编码器,并计算出预测的相似度。
可想而知,这使得交叉编码器在实际应用中的速度慢到几乎无法使用的地步,也就是说,交叉编码器难以落地!
03 双编码器(Bi-encoders)
你可能已经注意到,我已经把 “sentence transformer”和 “双编码器(bi-encoder) “这两个术语几乎交替起来使用。这是有原因的:它们在许多场景下是可以互换的。Sentence transformer只是指Python包中的sentence-transformers和原始论文SBERT,而双编码器更多的是指实际的模型架构。
交叉编码器的低效率弱点正是双编码器大放异彩的强项。虽然交叉编码器往往更准确,但双编码器的优势在于它可以产生实际的句子嵌入,这使得它们在现实世界中更快、更实用,因为它们允许索引、预先计算嵌入等。
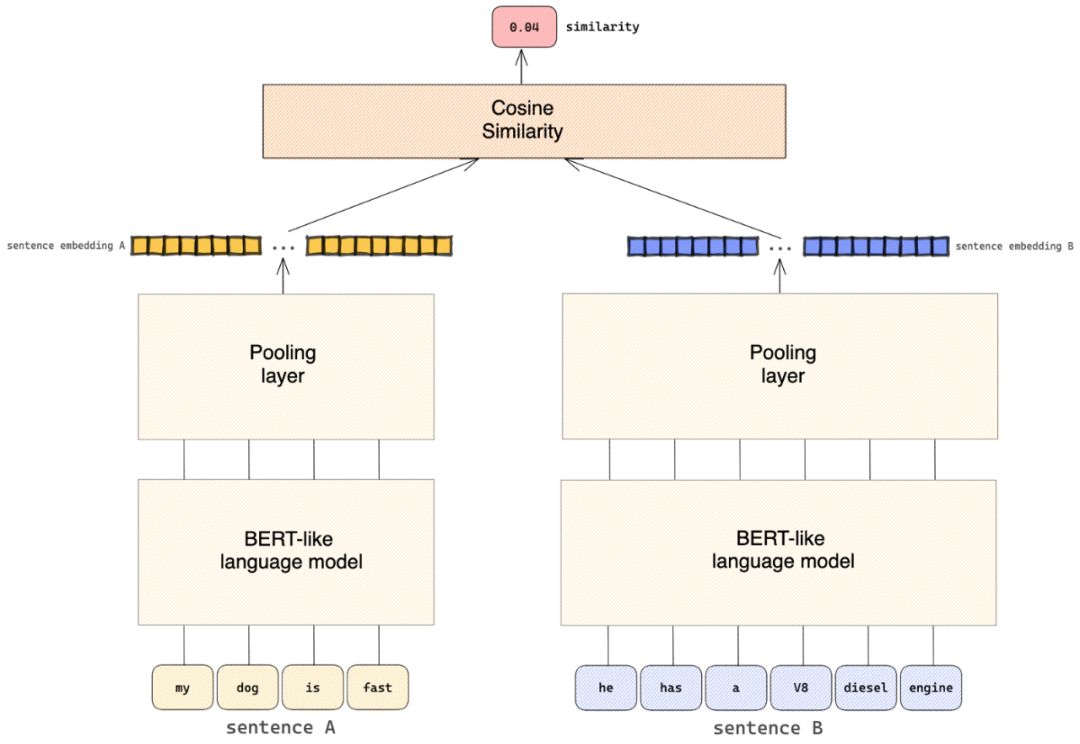
双编码器的模型架构
举例来说,用交叉编码器对1万个句子进行聚类,需要计算大约5000万个句子对的相似性分数,这在BERT架构下需要大约65小时。在这段时间里,你可以把所有13部黄飞鸿系列电影看1遍,听完张学友历年专辑里的每一首歌,而且你还会有几个小时的时间。
相比之下,用双编码器完成同样的任务需要大约5秒钟。这大约仅是” 以小民之见,我们不只要练武强身,以抗外敌,更重要的是广开言路,治武合一,那才是国富民强之道…”一幕说话的长度。
然而,应该注意的是,知识蒸馏(knowledge distillation)的训练程序中,双编码器的学生模型试图模仿交叉编码器的教师模型,既能让模型精简缩小,也能保留原始模型九成以上甚至反超原始模型的效果,这是非常有实用价值的一个方向。但这本身是一个话题了,笔者在本篇中就不赘言了。
04 关于Sentence transformer的训练
sentence transformer的真正威力在于其训练程序,它是专门为语义相似性而设计的。Sentence transformer的训练常使用所谓的孪生网络( Siamese networks)。
在孪生网络中,单条训练数据是由一个 “锚数据点(anchor data point)”、一个 “正例数据点(positive data point) “和一个 “负例数据点(negative data point) “组成的三元组。这里的训练目标是”三元损失函数( triplet loss function)”—它是在最小化锚数据点嵌入到正例数据点嵌入之间的距离的同时,还最大化锚数据点嵌入到负例数据点嵌入之间的距离。
孪生训练(Siamese training)是一个从计算机视觉中借用的想法。假设你想设计一个人脸相似度判别系统。你将数据结构化为一个 “锚 “图像、一个 “正例 “图像(即同一个人的不同图像)和一个 “负例”图像(即另一个人的图像)的三元组。然后对模型进行训练,使锚和正例图像的嵌入非常接近,而锚和负例图像的嵌入则拉远。
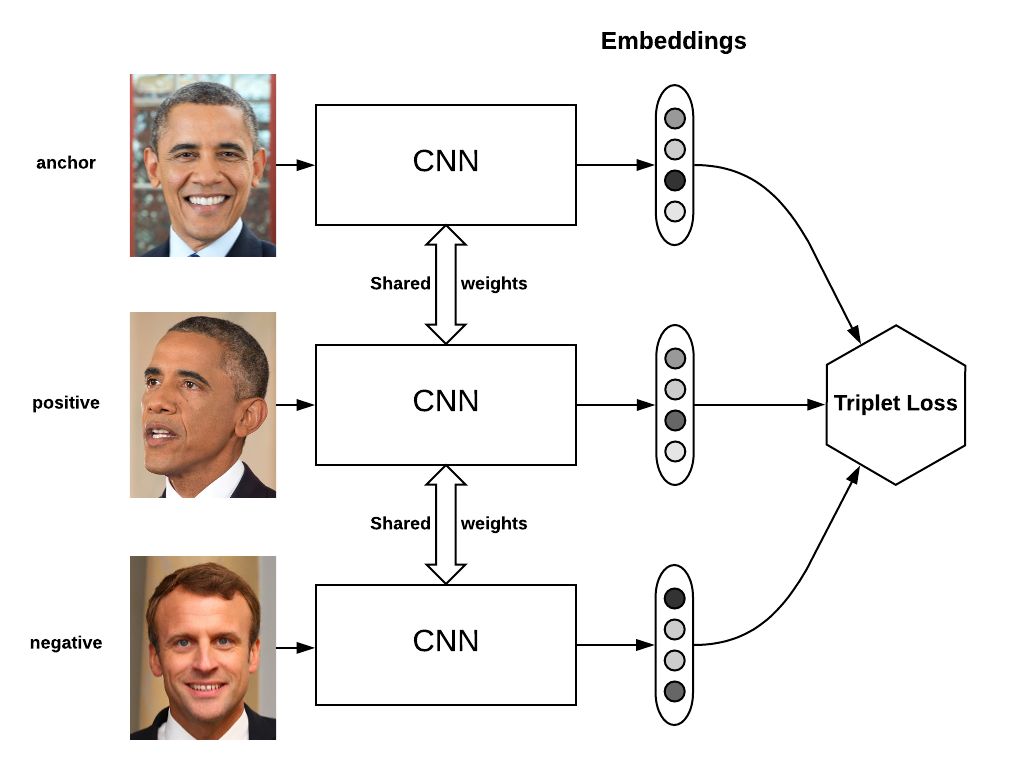
孪生网络最初是用来进行人脸识别的
以此类推,在sentence transformer的背景下,每条训练数据为一个锚定语句与一个在语义上与锚定语句相似的正例语句,以及一个在语义上与锚定语句不相似的负例语句的三元组。
这种学习范式实际上是“偷师”于CV领域的对比学习中的一种形式,它是显性的规定“负例”。
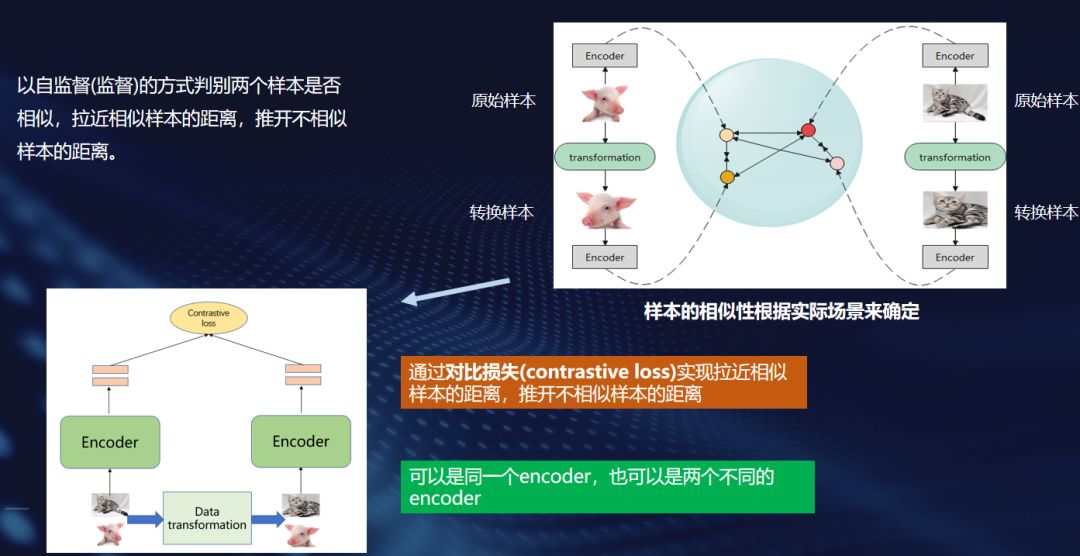
通过对比学习学到通用且优良的文本表示
那么,现在句表示学习领域的“扛把子”其实是隐性的规定负例(只有锚定语句和一个正例,同一批次中的其他语句则为负例,或者指定一组锚定语句、正例、困难负例,同一批次的其他语句皆为负例),使用的是Multiple Negative Ranking Loss,数学上的表达式为:
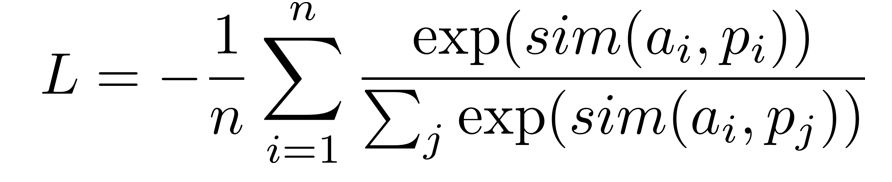
Multiple Negative Ranking Loss公式
其直观解释为:

Multiple Negative Ranking Loss的直观解释
同样地,训练过程会不断动态调整语句的嵌入,使锚定语句的嵌入在语义空间上,不断接近正例语句的嵌入,同时远离负例语句的嵌入。
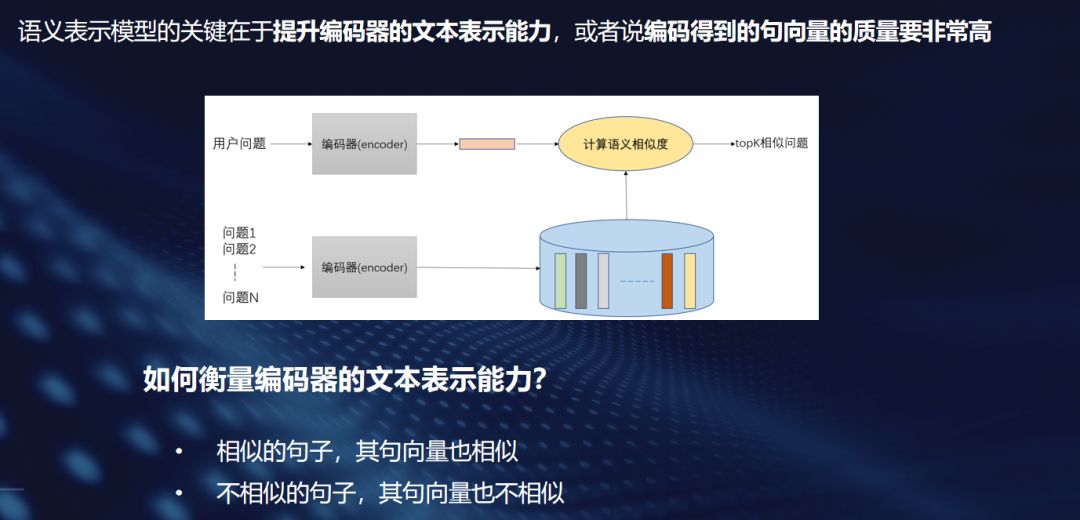
语义表示模型的核心要素

双编码器的三元组训练数据样例
注意:这个训练过程迫使sentence transformer产生有语义的语句嵌入,即语义相似的语句的语句嵌入接近,而语义不相似的句子的语句嵌入不接近。
在实际训练过程中,负例的选择是关键,一般而言,要得到较为通用、质量较高的语句表示,不要指望无监督训练,不要指望无监督训练,不要指望无监督训练,重要的事情说三遍,训练过程中对模型注入关于现实世界的先验知识非常关键!
简而言之,要善于构造训练数据中的困难负例,也就是和正例字面义或者主题相近、容易搞混淆,但跟锚定语句没多大关系的语句,这种信息对于模型来说很难学习,但是这些信息更能反映语义的本质,学会后,模型的理解能力非常强悍!

要善于构造困难负例
构造困难负例的常规方法如下图所示,其中的关键点在于:
- 用Cross-Encoder对所有挖掘出的段落进行分类
- 仅将Cross-Encoder得分低于阈值的段落作为Bi-Encoder的困难负例,这是降噪环节,有助于提升负例质量
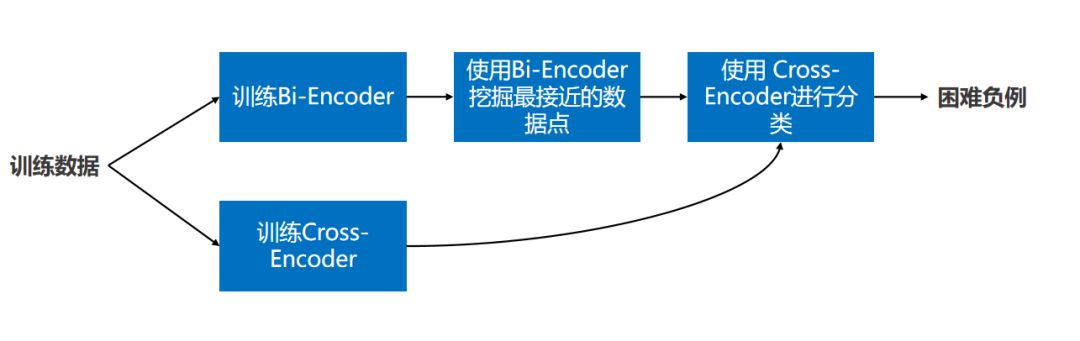
如何寻找困难负例?
看看基于困难负例学习的实际效果,绝对是值!

少整那些花里胡哨的无监督玩法,要真正用起来,高质量三元组(困难负例版本)搞起来!
05 结语
综上所述,我们对sentence transformer进行了非常详细的技术分析。然而,我们不要忽视大局,回顾一下我们所讨论的内容。
- 比较了sentence transformer和普通transformer,发现其中一个并不普遍地比另一个好。sentence transformer只是针对语义相似性进行了调整。我们讨论了交叉编码器,它将语义相似性作为一个分类问题。我们的结论是,虽然交叉编码器通常非常准确,但它们在实际应用中因效率问题往往不太实用,难以落地。
- 看到了双编码器是如何被设计来为交叉编码器的低效率提供解决方案的。
- 最后讨论了双编码器的训练过程,这是真正使其脱颖而出的原因,因为它们的基本架构与普通transformer的相同。
- 构建基于困难负例的有监督三元组数据集和基于对比学习的表示学习范式所得的模型具有良好的泛化能力
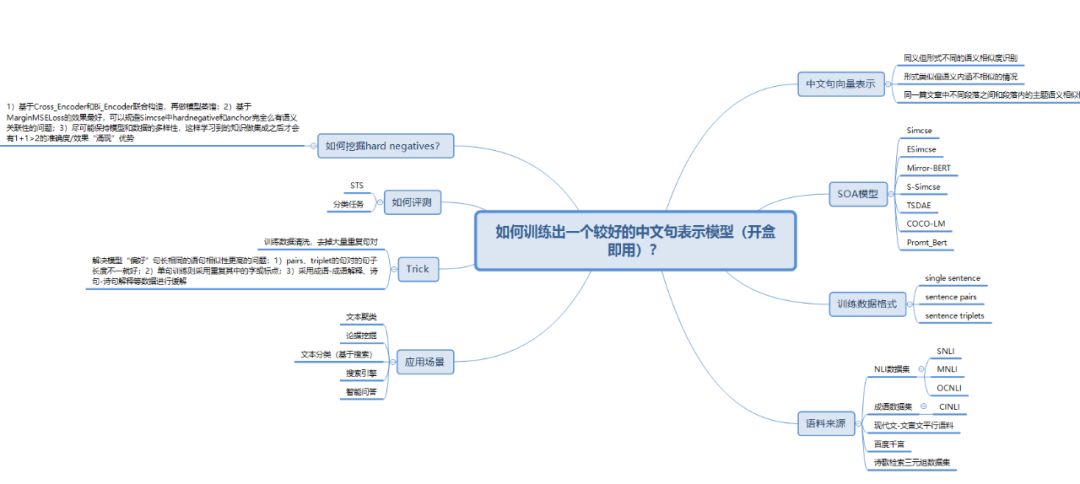
最后附上一个思维导图,包含笔者的一些总结:
作者介绍
高长宽:达观数据解决方案副总监
擅长数据分析和可视化表达,热衷于用数据发现洞察,指导实践。




