
在当今数字化时代,企业和组织每天都会产生和处理海量的文档数据。其中,大量的非结构化文本,如合同、报告、邮件等,蕴含着丰富的有价值信息。如何高效地从这些非结构化文档中抽取关键信息,将其转化为结构化数据,以便进行分析、决策和应用,成为了众多领域面临的关键挑战。大模型训练平台的出现,为这一难题提供了创新的解决方案,正在推动文档抽取从传统的人工标注模式向 AI 自治的智能化模式转变。本文将以达观数据的相关技术和产品为例,深入探讨大模型训练平台在锻造文档抽取进化引擎方面的关键作用和实现路径。
一、传统文档抽取模式的困境
在大模型技术广泛应用之前,文档抽取主要依赖人工标注结合机器学习算法的模式。这种模式下,首先需要专业人员花费大量时间和精力对文档中的关键信息进行标注,如在合同文档中标注出合同编号、签约方、金额、期限等字段。标注完成后,以此为训练数据来训练机器学习模型,期望模型能够学习到从文档中抽取这些关键信息的模式和规则。
然而,这种传统模式存在诸多弊端。一方面,人工标注成本高昂且效率低下。标注工作需要专业知识和高度的专注,随着文档数量的增加和业务场景的复杂多样化,人工标注的工作量呈指数级增长。据相关数据统计,在一些金融机构中,仅处理一份复杂的招股说明书,人工标注就可能需要数小时甚至数天的时间。而且人工标注容易出现主观偏差,不同标注人员对同一文档的标注结果可能存在差异,影响数据的一致性和准确性。
另一方面,基于传统机器学习算法的模型泛化能力较差。这些模型对标注数据的依赖性极强,当遇到新的文档类型、格式变化或领域知识更新时,往往需要重新进行大量的人工标注和模型训练,适应性非常有限。例如,在法律行业,如果出现新的法律法规条款,涉及到合同模板和条款表述的变化,传统模型就很难准确抽取相关信息,需要重新投入大量人力来更新标注数据和训练模型。
二、大模型训练平台的技术突破
大模型训练平台凭借其强大的技术能力,为文档抽取带来了革命性的变化。以达观数据的大模型训练平台为例,它融合了自然语言处理(NLP)、光学字符识别(OCR)、计算机视觉(CV)等多种前沿技术,形成了一个高效智能的文档处理体系。
- 预训练大模型的语义理解能力
达观数据的大模型训练平台基于大规模的文本数据进行预训练,这些数据涵盖了多个领域和行业,使得模型能够学习到丰富的语言知识和语义理解能力。通过对海量文本的深度理解,模型可以准确把握文档中各种信息的含义和相互关系,而不仅仅依赖于人工预先定义的规则。在处理合同文档时,模型能够理解诸如 “甲方应在收到乙方交付货物后的 30 个工作日内支付全部货款” 这样复杂句式中各方的权利义务关系,自动识别出 “甲方”“乙方”“30 个工作日”“支付货款” 等关键信息,而无需人工对每种可能的表述方式进行逐一标注。
- 自动化的数据标注与扩充
大模型训练平台具备自动化的数据标注能力。它可以利用已有的少量标注数据作为种子,通过模型的推理和学习能力,对大量未标注的文档数据进行自动标注。这种自动化标注不仅速度快,而且能够保证标注的一致性。平台还可以通过数据增强技术,对标注数据进行扩充,如对文本进行同义词替换、句式变换等操作,生成更多的训练数据,进一步提升模型的泛化能力。在处理医疗领域的病历文档时,平台可以根据已标注的少量病历,自动标注大量相似格式和内容的病历,同时通过数据增强生成更多不同表述但语义相同的病历数据,让模型学习到更全面的病历信息抽取模式。
- 多模态融合技术提升抽取准确性
在实际的文档处理中,很多文档并非单纯的文本形式,还包含图片、表格等多种模态信息。达观数据的大模型训练平台采用多模态融合技术,将 OCR 技术识别出的图片和表格中的文字信息与文本内容进行融合处理。在处理财务报告时,平台可以通过 OCR 准确识别表格中的财务数据,如营收、利润、成本等,同时结合文本部分对这些数据的解释和说明,更准确地抽取和理解财务报告中的关键信息,避免了单一模态处理可能导致的信息遗漏或误解。
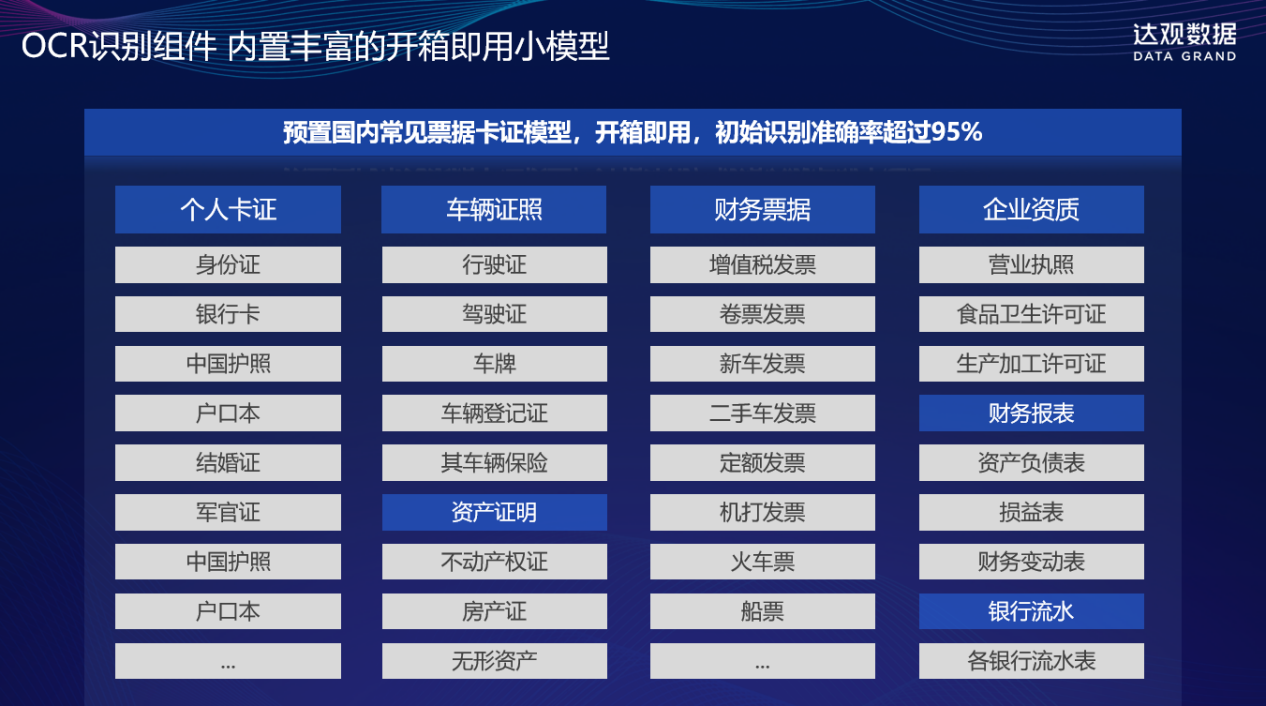
三、达观 IDP:基于大模型训练平台的智能文档处理实践
达观智能文档处理平台(IDP)是达观数据基于大模型训练平台打造的一款先进的智能文档处理解决方案,在多个行业得到了广泛应用,并取得了显著的成效。
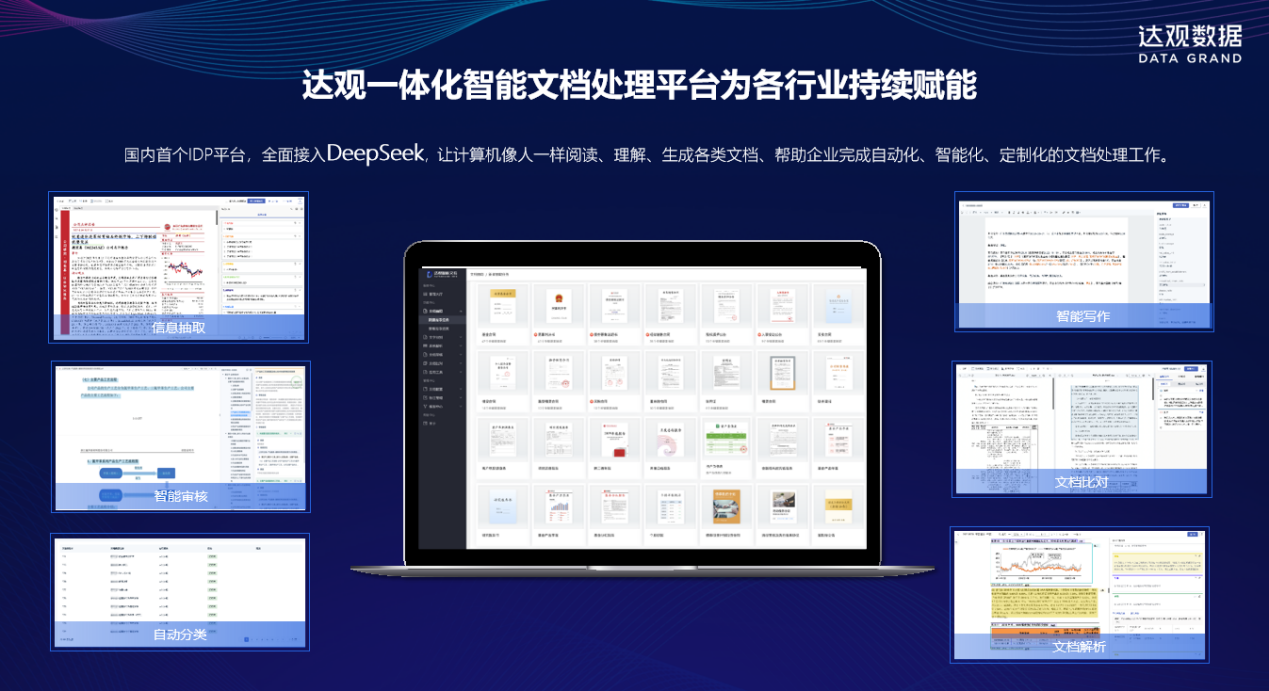
- 强大的文档解析能力
达观 IDP 能够支持多种文档格式,包括扫描件、PDF、图片(jpg、jpeg、bmp、tif、tiff)、Word、Wps 等常见格式。通过先进的 OCR 识别技术和 NLP 技术,它可以快速准确地提取文档中的文字信息,并将其转换为结构化数据。在金融行业,对于大量的合同扫描件,达观 IDP 能够迅速识别其中的文字,将合同内容转化为可编辑和分析的文本格式,为后续的信息抽取和处理奠定基础。
- 统一信息抽取框架(UIE)实现高效抽取
达观 IDP 采用了统一信息抽取(UIE)框架,这一框架利用大模型端到端生成结构化结果的思想,实现了单模型多任务的抽取效果。用户只需定义目标抽取对象的 Schema(如合同中的 “甲方名称”“合同金额”“违约责任” 等字段),模型就能根据 Schema 自动从文档中提取对应信息并生成结构化结果。这种方式摆脱了对传统人工编写抽取规则的依赖,大大降低了适配不同业务场景的难度。在制造业中,对于生产文档、质量报告等各类文档,通过 UIE 框架可以快速配置抽取规则,实现对关键信息如产品规格、生产工艺、质量指标等的高效抽取,大幅提升了文档处理效率。
- 领域模型优化与知识积累
为了更好地适应不同行业的需求,达观 IDP 在大模型训练平台的基础上,针对各行业特点进行领域模型优化。在金融领域,平台收集了大量公开网站上的金融财经新闻公告等数据,并结合自身积累的金融领域文本数据,经过严格的数据清理后得到数百万条高质量的预训练文本数据。经过大量实验和测试,使用迭代后调优后的预训练语言模型在金融领域的下游任务中,效果普遍提升 2 – 3%,能够更准确地抽取金融文档中的专业术语、金融数据和复杂条款等信息。
- 智能校验保障数据质量
达观 IDP 通过大模型技术实现了智能校验功能,为文档抽取的数据质量提供了有力保障。平台能够对抽取的信息进行全面的准确性检测,与预先设定的标准和规则进行比对,检查抽取的数据是否符合预期的格式、范围和逻辑关系。在合同审核场景中,它可以检查合同条款是否完整、金额是否准确、日期是否合理等。对于检测到的错误和异常,系统会自动分析原因,并对抽取规则和模型进行调整和优化,不断提升数据抽取的准确性和可靠性。

四、应用案例与显著成效
- 金融行业
在证券、银行等金融机构中,达观 IDP 帮助实现了合同审核、研究报告审核、招股说明书提取等业务的自动化和智能化。通过达观 IDP,文件表格抽取率达到 80% 以上,文件字段抽取率高达 95% 以上。这不仅极大地提高了工作效率,减少了人工审核的时间和成本,还降低了信息遗漏风险,满足了监管要求的穿透式审查需求。一家大型证券公司在使用达观 IDP 后,原本需要数十人花费数周时间才能完成的招股说明书审核工作,现在通过自动化抽取和智能校验,仅需少数人员进行简单复核,即可在几天内完成,大大缩短了项目周期,提升了业务竞争力。
- 制造业
在制造业领域,达观 IDP 助力企业实现了生产文档、质量报告、采购合同等文档的智能处理。以某大型制造业企业为例,在引入达观 IDP 之前,技术网页生成错误率高达 15%,严重影响了生产流程的顺畅性和产品质量。使用达观 IDP 后,通过对生产文档和质量报告的准确信息抽取和分析,技术网页生成错误率大幅降至 3%,显著提升了业务效率,减少了因文档处理不当导致的生产延误和质量问题。
- 法律行业
对于律师事务所等法律机构,达观 IDP 为合同起草、审核、履约管理等全生命周期提供了智能文档处理服务。通过智能校验功能,确保生成的法律文档内容准确无误,提高了法律服务的专业性和效率。在处理大量合同的过程中,达观 IDP 能够快速识别合同中的风险条款,自动对比不同版本合同的差异,为律师提供准确的审核建议,大大减轻了律师的工作负担,提高了合同管理的质量和效率。
从人工标注到 AI 自治,大模型训练平台正在重塑文档抽取的格局,成为推动各行业数字化变革的关键进化引擎。通过不断的技术创新和实践应用,它将持续为企业挖掘文档数据的潜在价值,助力企业在数字化时代实现高效、智能的发展。




