
近日,复旦大学肖仰华教授研究组联合达观数据技术团队,在人工智能文字语义理解和知识自动提取技术方向获得重要突破,归纳而获取常识的方法,并将其成功应用于以动词为核心的隐性常识获取任务中,论文成果被人工智能领域顶级国际期刊《Artificial Intelligence》收录。这是AIJ创刊数十年以来首度有来自中国上海的研究团队的成果被该期刊录用,该重要成果将推动认知智能相关技术的成果应用,也将有助于知识问答、语言大模型LLM等的未来发展与应用。

图1 达观数据联合复旦大学发表的AIJ期刊论文
本文主要研究以动词为核心的隐性常识知识归纳。人类的常识多是隐性的,人们往往下意识地使用了常识,却很难显式表达常识。隐性常识的获取一直以来是知识工程的难题之一。本文提出了一种利用概念指引从实例知识进行归纳而获取常识的方法,并将其成功应用于以动词为核心的隐性常识获取任务中。比如根据张三吃苹果、李四吃李子、王二吃橘子,归纳出“人吃水果”这一常识。该方法主要包括两个模块:一是基于信息熵的三元组过滤器,其主要功能是用于过滤噪音动词短语;二是基于最小描述长度和神经语言模型的联合模型,其主要功能是生成常识知识。为了验证方法的有效性,作者在公开数据集进行了大量的实验,构建了大规模动词常识的知识库VoCSK,基本涵盖了人类语言中的常见动词。论文证实了该常识库能够提升一系列下游任务的性能。本文首次提出基于归纳的获取知识方法,更加接近人类的知识获取方式,为机器的知识获取贡献了新路径。
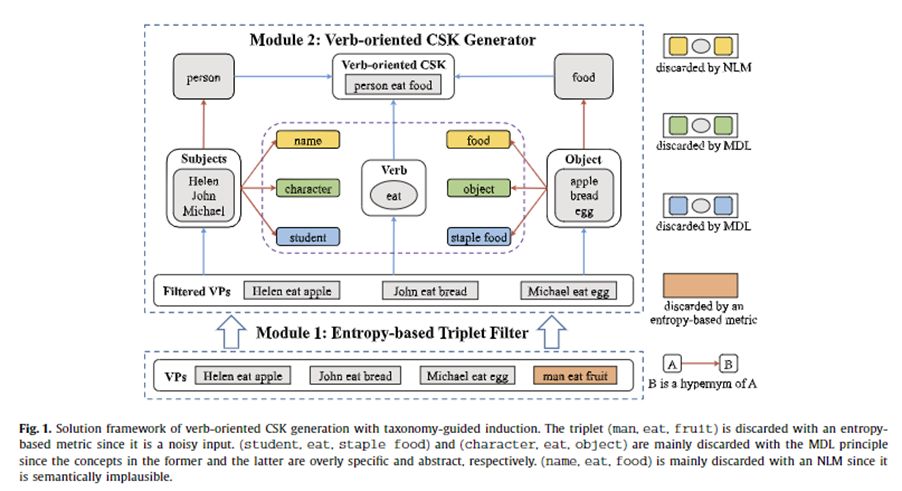 图2 使用分类导向生成动词导向的常识知识的方案框架
图2 使用分类导向生成动词导向的常识知识的方案框架
- 使用基于熵的度量来丢弃噪声输入三元组(man, eat, fruit)
- (student, eat, staple food)和(character, eat, object)主要通过MDL原则被丢弃——前者过于具体,后者过于抽象
- (name, eat, food)通过NLM 的义上是不可信被丢弃
 图3 基于动词的CSK 挖掘流程
图3 基于动词的CSK 挖掘流程
“Artificial Intelligence Journal”(简称AIJ),即《人工智能期刊》,创刊于1970年,是国际最为老牌的人工智能期刊之一,是中国计算机学会推荐的A类国际期刊,同时也是Journal Citation Reports(JCR)计算机科学、人工智能分区一区期刊。AIJ是国际上极具影响力的人工智能领域期刊,发表了众多图灵奖获得者(包括Tim Berners-Lee、Richard M. Karp、Raj Reddy、Michael O. Rabin、Marvin Minsky、Leslie Valiant、John McCarthy、John Hopcroft、Herbert A. Simon、Geoffrey Hinton、Fernando J. Corbató、Edward Feigenbaum、Edmund M. Clarke、Donald Knuth、Allen Newell等)的重要工作,是知识工程领域最为重要的期刊之一。AIJ的发表难度极大,此前鲜有来自大陆的研究团队论文刊载,本次是来自上海的研究团队首次在AIJ上发表论文。

达观数据与复旦大学在知识图谱方面长期以来建立了深入的产学研合作,共同组建了“文本挖掘联合实验室”、浦东新区院士(专家)工作站,开展定期的技术讲座,设立“复旦大学计算机科学技术学院达观数据奖学金”,旨在共同推动文本语义以及知识图谱领域的人才培养、科研和产业发展。




