
在数字化时代,企业积累了海量文档、资料与数据,但“知识分散在孤岛”“难以快速转化为业务价值”“深层关联无法被挖掘” 等问题,成为知识管理的核心痛点。企业亟需一套能真正“穿透业务场景”的知识库系统,从复杂多样的知识载体中精准挖掘、高效关联知识,让知识从“静态资产”变为“动态生产力”。
达观企业知识库凭借独有IDP技术的精准解析能力、大模型与自然语言处理(NLP)的深度提炼能力、多渠道知识的实时关联与装配能力,构建起行业唯一能贯穿“知识获取-提炼-关联-应用” 全流程的企业知识库产品,为企业知识管理提供全新范式,助力企业在数字化浪潮中筑牢知识底座、激活创新动能。
一、为何传统知识库无法“穿透”业务场景?
在深入探讨达观解决方案之前,我们首先必须理解“穿透业务场景”的真正含义及其挑战。
- 信息孤岛化:企业知识散落在PPT、Word、PDF、网页、图像、视频等多种格式、多个系统(如OA、CRM、ERP)中,缺乏统一的理解和关联。
- 理解表面化:传统技术(如关键字搜索)只能进行字面匹配,无法理解文档的版面结构、语义内涵以及知识点之间的逻辑关系。当一份复杂的合同或研究报告被整体存储时,其中某个关键条款或数据结论难以被精准定位和提取。
- 应用被动化:知识等待被查询,而非主动服务于业务。销售人员在面对客户刁钻问题时,客服人员在处理紧急故障时,研发人员在攻关技术难题时,无法实时获得嵌入其工作流中的精准知识推送。
这些痛点的根源在于,传统知识库缺乏对知识本身的深度理解和智能连接能力。而达观企业知识库,正是为解决这些根本性问题而构建。
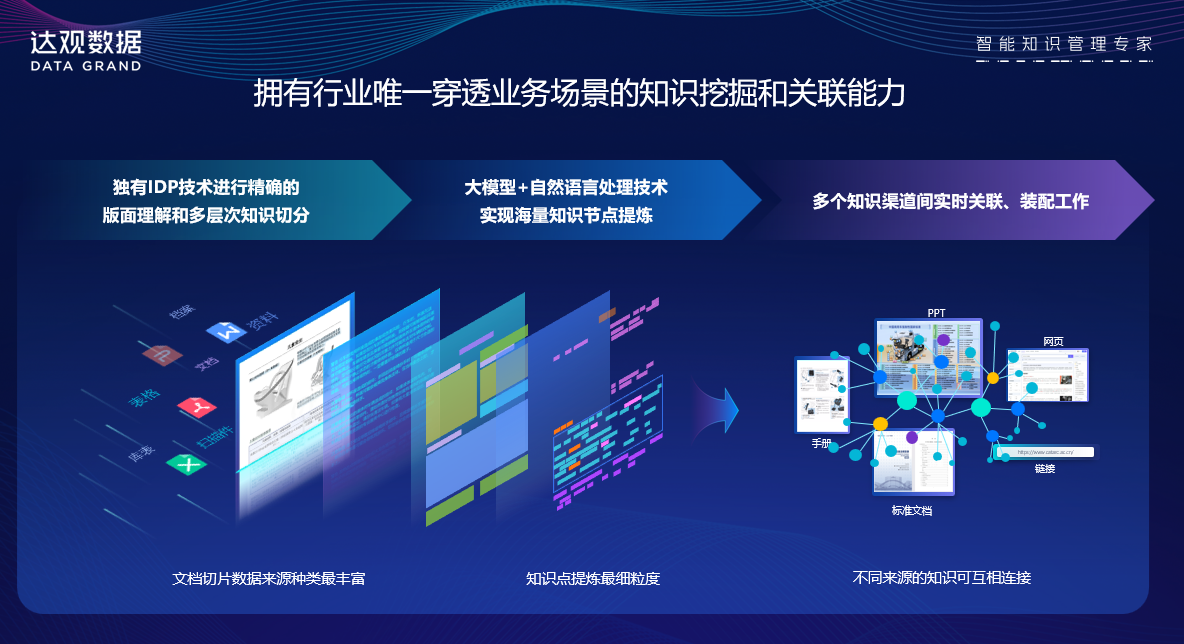
二、独有IDP技术进行精确的版面理解和多层次知识切分
知识管理的第一步,是让系统“看懂” 文档——这正是智能文档处理(Intelligent Document Processing,IDP)技术的核心价值。达观数据凭借独有 IDP 技术,实现了对文档“高精度版面理解”与“多层次知识切分”,为后续知识挖掘筑牢根基。
2.1 IDP 技术:重新定义文档理解的精度
传统 OCR(光学字符识别)仅能“识别文字”,简单解析工具面对“多表格、图文混排、扫描件歪扭、多语言混编” 等复杂版面时,常出现“结构识别错误、内容提取不全”的问题。
达观 IDP 技术融合OCR、计算机视觉、深度学习等能力,让系统像人类一样 “看懂” 文档的空间结构与逻辑关系:
- 能精准识别文档中的“标题、段落、表格、图片、公式、脚注”等元素的位置与层级;
- 能还原“嵌套表格、跨页图表、多列排版”等复杂版式的逻辑;
- 能兼容“PDF、Word、扫描件、CAD 图纸、网页截图”等多类载体。
行业场景验证:
- 金融行业:某股份制银行的年度报告包含“合并报表、嵌套附注、多语言风险提示”,达观 IDP 可精准定位每个数据的来源层级,为后续财务知识提取扫清障碍;
- 制造业:某重工企业的设备维护手册多为“PDF 扫描件 + 多语言技术参数”,IDP 能跨格式解析,识别“操作步骤、保养周期、故障代码” 等关键信息,准确率达98%以上。
2.2 多层次知识切分:从“文档”到“知识单元”的精细拆解
企业知识藏于文档中,若仅以“文档”为单位管理,员工仍需耗费大量时间查找关键信息。只有将文档拆解为“知识单元”(如 “客户名称”“技术参数”“流程步骤”),才能实现知识的高效复用与关联。
达观IDP实现“宏观-中观-微观”多层次知识切分:
- 宏观层:识别文档的“类型、主题、所属业务领域”(如 “市场营销方案”“产品研发手册”);
- 中观层:提取文档的 “章节、子标题、核心板块”(如一份项目方案的“需求分析”“实施步骤”“风险评估”);
- 微观层:切分最细粒度的知识片段,如“实体(客户名称、产品型号)”“关系(产品A适配系统B)”“属性(设备功率200kW)”。
技术实现:通过预训练深度学习模型,结合行业专属训练数据,IDP能自动学习不同业务场景的知识结构规律。例如:
- 法律行业:自动切分“法条原文”“适用条件”“案例引用”等层级;
- 医疗行业:从病历中拆解“症状描述”“诊断结果”“治疗方案”等单元。
2.3 精准解析对知识管理的核心价值
- 夯实知识底座:只有输入的知识“精准”,后续提炼与关联才“可靠”。达观 IDP 确保知识来源的准确性,避免因文档解析错误导致知识失真;
- 降低人工成本:替代大量人工整理文档的工作,让知识管理从“文档搬运”转向 “价值挖掘”。某大型集团测试显示,达观IDP使文档预处理效率提升80%以上;
- 支撑业务场景:当业务需要调取“某产品的技术参数”“某客户的历史合作条款” 时,精准的知识切分能让系统直接定位到细粒度单元,无需员工翻阅整份文档。
三、大模型+自然语言处理:突破海量知识提炼的 “深度与效率”
若将IDP视为“知识入口的精准过滤器”,那么大模型与NLP技术就是“知识加工的核心引擎”——二者结合,可从海量非结构化、半结构化数据中,高效提炼“可复用、能关联” 的知识节点。
3.1 大模型与NLP的技术协同:让知识“活”起来
自然语言处理(NLP)擅长“规则化”文本分析(如命名实体识别、文本分类),但在“语义理解、跨领域泛化”上存在局限;大模型(如达观自研大模型)凭借海量预训练数据与强大语义推理能力,可突破NLP的边界,理解复杂语义、生成知识关联、推理潜在逻辑。二者结合,既保证“精准性”,又实现“泛化性”。
核心能力体现:
- 语义理解:准确识别专业术语、缩写、歧义句(如金融领域“头寸”、医疗领域 “占位性病变”);
- 知识抽取:从非结构化文本中自动提取 “实体-关系-属性” 三元组(如“产品 A-适配-操作系统 B”);
- 知识生成:基于多文档内容,自动生成摘要、问答、知识图谱等结构化知识。
3.2 海量知识节点提炼:从“数据”到“知识”的跨越
传统知识提炼存在两大困境:人工提炼效率极低(面对数万份文档几乎不可能完成);规则式NLP工具灵活性差(需大量人工标注,且难以适配业务变化)。
达观通过“大模型+ NLP”实现技术突破:
- 预训练与微调结合:大模型在通用语料上预训练,再用行业专属数据(如金融合同、医疗病历)微调,快速掌握行业知识“语境”;
- 自动化知识抽取:无需大量规则配置,即可从“合同、邮件、会议纪要、技术文档” 等多类文档中,自动提炼核心知识节点。例如:
- 从销售合同中提取“甲方乙方、标的金额、交付周期”;
- 从研发会议纪要中提取“技术难点、解决方案、责任人”;
- 细粒度与规模化兼顾:既能提炼“某客户的合作历史”这类细粒度知识,也能对十万级文档进行批量处理,实现“大规模知识的细粒度提炼”。
3.3 行业案例:大模型+NLP如何激活知识价值
- 金融行业:某股份制银行需从历年信贷合同(数万份,多为PDF扫描件)中提炼 “担保条件、利率条款、违约处理” 等知识节点。达观“大模型 + NLP”方案自动抽取关键条款并分类归档,使信贷知识查询效率提升90%,新员工上手速度加快60%;
- 制造业:某汽车企业有“设计规范、工艺手册、供应商资料”等海量技术文档。通过达观技术,自动提炼“零部件参数、工艺步骤、供应商资质”等知识节点,并关联成 “产品-零部件-工艺-供应商”知识网络,使研发部门查询零部件替代方案的时间从1天缩短至10分钟。
四、多渠道实时关联与装配:构建 “鲜活” 的知识网络,赋能业务场景
企业知识分散在“PPT、Word 手册、PDF 标准文档、内部网页、外部链接”等多类载体中,且分属不同部门(市场部的案例、研发部的技术文档、财务部的流程规范)。传统“文档库”式管理因缺乏关联,导致知识“可用度低、协同性差”。
达观企业知识库通过 “实时关联+知识装配”,让分散知识形成 “鲜活知识网络”,直接赋能业务场景。“穿透业务场景”的精髓在于主动服务。达观知识库能够与企业的业务系统(如OA、CRM、SCM)深度集成,感知用户当前的工作上下文。
4.1 知识渠道的多样性与关联的必要性
企业知识具有“多载体、跨部门、动态更新”的特点:
- 载体多样:PPT(市场案例)、Word(操作手册)、PDF(标准规范)、网页(内部知识库)、链接(外部行业报告)等;
- 部门分散:研发部的技术文档、市场部的推广案例、客服部的售后记录,分属不同系统;
- 动态更新:新的项目文档、客户反馈、行业政策需实时纳入知识体系。
传统知识管理的缺陷是“知识间缺乏关联”——员工想了解某产品,只能找到产品手册,却看不到“市场案例、客户反馈、技术改进记录” 的关联,导致“知识获取不完整,业务决策缺依据”。
4.2 达观企业知识库如何实现多渠道知识的实时关联
达观企业知识库通过“语义关联引擎+业务关联规则+实时性保障”,自动发现不同渠道知识的关联:
- 语义关联引擎:基于大模型的语义理解能力,分析知识的“语义相似度、主题相关性”。例如“产品市场推广 PPT”与“客户反馈分析报告”若都涉及“用户体验优化”,系统会自动建立关联;
- 业务关联规则:结合企业业务流程(如“项目立项→研发→测试→市场推广→售后”),定义知识间的业务逻辑关联。例如,“研发阶段的技术文档”会自动关联 “测试阶段的问题报告”与“售后阶段的维修手册”;
- 实时性保障:通过流式处理与实时索引技术,新上传的知识(如刚结束的会议纪要)能立即被分析,并与现有知识网络建立关联,确保知识网络“鲜活”。
4.3 知识装配:让知识成为“业务可用”的资源
“知识关联”不是简单的“链接跳转”,而是根据业务场景,将关联知识整合成“解决方案包”。
例如,当员工需要“某客户的定制化方案”时,系统会自动装配:
- 该客户的“行业分析文档”;
- 相似项目的“成功案例 PPT”;
- 产品的“技术参数手册”;
- 过往合作的“合同模板”。
同时,达观通过知识图谱等形式,可视化展示知识间的关联关系。员工可通过“节点+关系” 的方式,快速探索知识脉络(如点击“产品 A”,可看到关联的“核心技术”“市场竞品”“客户评价”“维修指南”等分支)。
3.4 业务赋能案例:关联与装配如何驱动价值
- 零售行业:某连锁零售企业有全国上百家门店的“运营手册、区域市场分析报告、总部政策文档”。达观知识库通过关联装配,当某区域门店查询“促销活动策划” 时,系统自动推送“总部促销政策文档、同区域历史成功促销案例PPT、目标客群分析报告、供应链保障手册”,使活动策划效率提升70%,活动销售额平均提升25%;
- 医疗行业:某三甲医院需整合“病历、检查报告、医学指南、专家论文”等知识。达观系统将患者病历与对应的 “疾病诊疗指南、相似病例文献、用药手册” 关联,医生在诊断时可快速获取全方位参考,使疑难病例诊断准确率提升 15%。
五、达观企业知识库:为企业知识管理提供 “可落地、高价值” 的参考范式
达观企业知识库的核心优势,在于构建了“知识获取-提炼-关联-应用”的全流程能力闭环。
5.1 全流程优势:从知识获取到业务应用的闭环
- 知识获取:通过IDP技术,精准解析多格式、多结构文档,打破“知识输入”的精度瓶颈;
- 知识提炼:大模型+ NLP技术实现高效、深度的知识节点提取,让“隐性知识” 显性化;
- 知识关联:多渠道实时关联与装配,构建“鲜活”知识网络,让知识从“分散”到“协同”;
- 知识应用:通过知识图谱、智能检索、智能推荐等方式,将知识精准推送到业务场景,真正赋能员工与业务。
5.2 对企业知识库建设的启示
- 重视“输入端” 精度:知识管理的第一步是“获取准确的知识”,IDP类技术是打破“垃圾进、垃圾出”困境的关键;
- 拥抱“大模型 + NLP”:借助人工智能突破知识提炼的“效率与深度”瓶颈,释放海量文档的隐藏价值;
- 聚焦“业务关联”:知识管理的最终目标是“服务业务”,必须建立“知识与业务场景、知识与知识”间的鲜活关联,让知识能“主动找业务”。
六、结语
在数字经济时代,知识是企业的核心资产,但 “有知识却用不好” 是多数企业的通病。达观企业知识库,以行业唯一的“穿透业务场景的知识挖掘和关联能力”,为企业提供了一套从 “知识孤岛” 到 “知识网络” 的完整解决方案。
从精准解析文档的IDP技术,到深度提炼知识的大模型+NLP技术,再到实时关联装配的多渠道能力,达观构建的不仅是一套系统,更是一种 “让知识主动服务业务”的全新范式。对于正规划建设知识库的企业而言,达观的实践证明:只有真正打通 “知识获取-提炼-关联-应用”的全链路,让知识能“穿透”业务场景的层层需求,才能真正激活知识价值,为企业创新与增长注入持久动力。




