
本文整理自7月7日世界人工智能大会“AI生成与垂直大语言模型的无限魅力”论坛上达观数据董事长兼CEO陈运文博士《“曹植”大语言模型的创新与应用》的主题分享。
达观数据是一家2015年在上海浦东张江创立的人工智能企业,专注于文本智能处理技术,并以此在人工智能领域崭露头角。经过几年不断发展,达观已在行业中取得领先地位,并荣获国家级“专精特新”小巨人奖。
书面类长文本更具价值
从本质上来讲,大语言模型的核心价值是发展大语言模型,提炼出知识,并以知识为驱动形成智能的过程。文字是人类文明的起点,也是实现人工智能的关键要素。大语言模型,尤其是GPT(Generative Pre-Trained Transformer)生成式预训练模型,近年来越来越受到关注,因为它解决了从文字中提炼人类知识的重要任务。文字资料处理人类知识有两大应用场景,一是用来做沟通和交流等短文本;二是用于书面文字资料,如文档、书籍、报告、资料等长文本。尽管目前很多大模型如ChatGPT主要处理对话类的短文本,但书面类长文本更具价值。因为书面文字资料的知识密度高、专业化程度高,对于训练大语言模型有着重要价值。

过去几年,达观一直致力于优化长文本处理的各个环节,包括数据的积累、工程实践以及产品系列的打磨。在模型层出不穷的今天,我们认为,专业化、特长化、产品化的模型才是未来发展的关键。基于这种理念,达观开发了自己的独特大语言模型——“曹植”大语言模型。
他山之石可以攻玉,达观参考海外经验,如今年3月份推出的BloombergGPT,它是全球第一个专门用于金融领域的优秀大模型,为达观提供了宝贵的参考。BloombergGPT的效果出众,尤其在金融领域的专业任务上表现出色。
“曹植”大语言模型
为此,达观研发了自己的大语言模型技术架构,运用了通用无监督训练和领域有监督训练,以及大量的专业领域语料。最终成功开发出了自己的“曹植”大语言模型,这是一款垂直、专用、国产的大模型,具备长文本、多语言、垂直化三大特点。
“曹植”大语言模型,名字的灵感源自于曹植的“七步成诗”以及其作品《洛神赋》。前者展现了模型强大的写作能力,后者作为一篇超过1000字的长文本,彰显了“曹植”在处理长文本方面的专业性。在构建这一模型的过程中,我们结合了通用语料和专业垂直语料的混合训练数据方案,其中包括50%的混合语料和50%的垂直专用语料,以确保模型既具备通用处理能力,又能够专业应对特定行业领域的语言处理任务。

在研发过程中,我们充分利用了自身多年积累的专业文档资料报告等信息,使得模型在垂直领域的语言能力和写作能力都达到了优秀的水平。我们也采用了多模型并联(Ensemble)的创新方法,通过整合经典的知识图谱、搜索引擎等工具和大语言模型,实现了模型性能的优化和提升。并且,模型包括了不同参数规模的多种模型,如数十亿、数百亿等,未来还将研发数千亿的模型。同时,还可以与其他第三方的大模型进行对接,实现模型间的融会贯通,进一步提升模型的价值。

“曹植”特点1:长文本
“曹植”大语言模型也是针对处理长文本而特别研发的产品。长文本不仅包含文字信息,还包含许多复杂的结构,如表格、文档样式、签名、盖章等,甚至还有图片等多模态的内容。这些复杂的元素,需要大模型具备高级的理解和分析能力。对于长文本,我们进行了详尽的处理和优化。例如,我们进行了段落篇章的解析,表格的解析等工作,以应对表格复杂的形式和样式。此外,我们还进行了版面分析,以深入了解文本的组织结构和版面布局,这对于专业报告等文档尤为重要。

因此,达观的”曹植”大语言模型不仅具有优秀的长文本写作能力,更具备专业性的写作能力。用户只需提供标题,模型即可生成文章的提纲,并根据提纲生成专业报告。
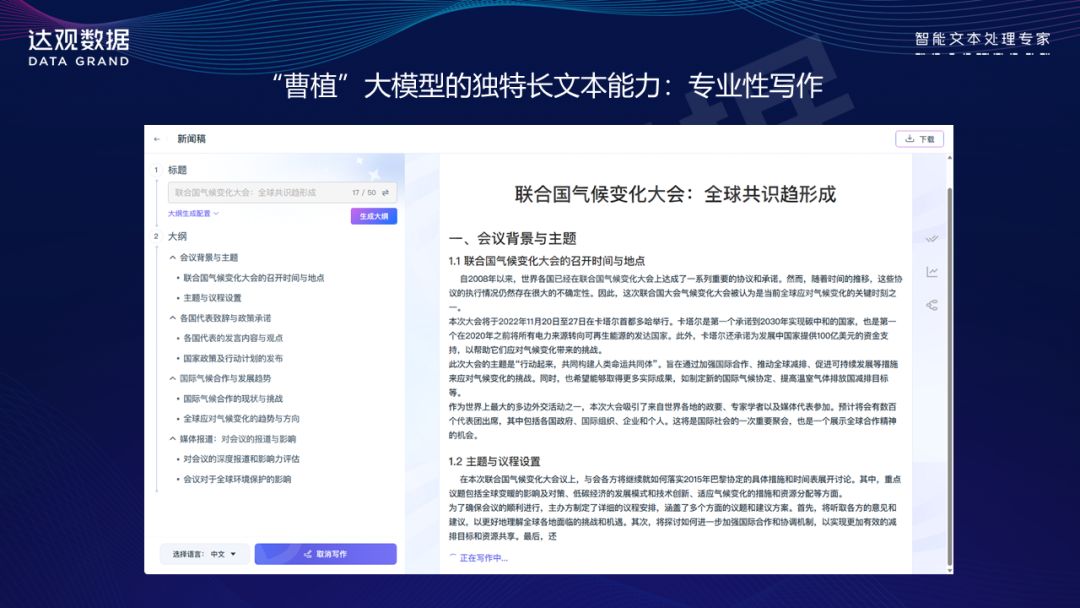
这一过程中,我们强大的AIGC多模态能力也会发挥作用,例如,可以根据用户的文字描述生成相应的图表,并将其插入到文档中。
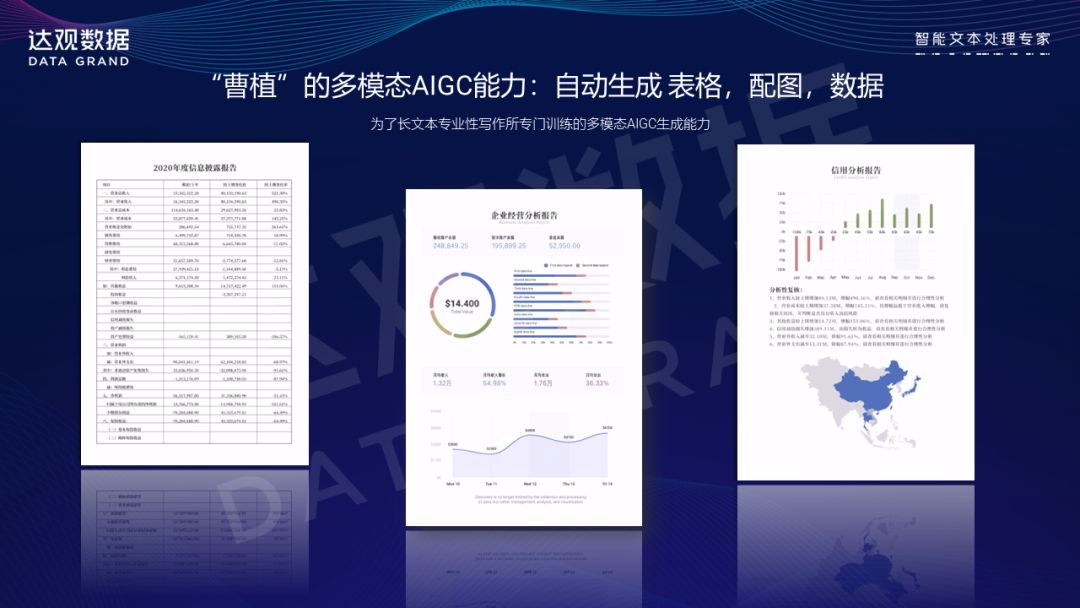
“曹植”特点2:多语言
此外,我们的大模型还具备多语言处理能力,可以根据用户的需求生成不同语种的专业报告。
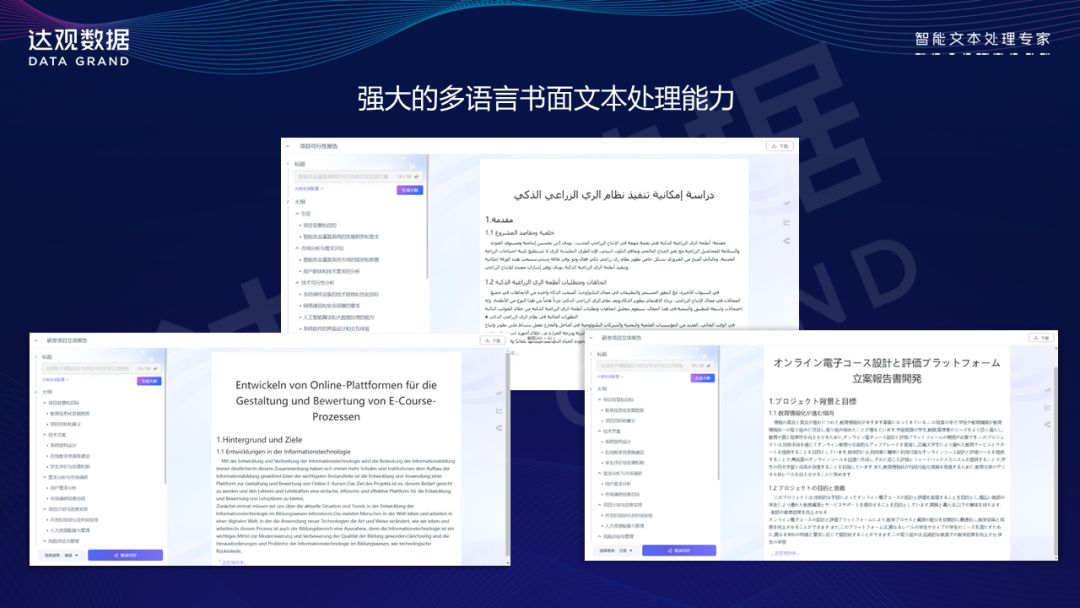
尤其是长文本的翻译能力,这一能力不仅包括语义翻译,还包括版面分析与版面还原。在翻译过程中,我们能够精确地提取原始报告的格式和版式,并在翻译完成后进行精确的还原,以确保报告的专业性和整洁性。

“曹植”特点3:垂直化
我们认为,大模型的产品形态不应只限于一问一答,而应该和行业应用相结合,才能打造出真正优秀的产品。因此,我们的大模型已经与多个行业专业领域的产品相结合,能够处理各种报告,处理专业领域的应用场景。
我们还开发了专门的WPS和Office插件,让用户在专业写作工具中直接使用“曹植”的能力。用户在写作过程中,可以直接从企业的知识库中调取所需的数据和信息,大幅度提高工作效率。这一插件分为个人免费版本和企业专属版本,我们可以为每个企业定制内部的知识库,使其更加专业和垂直。
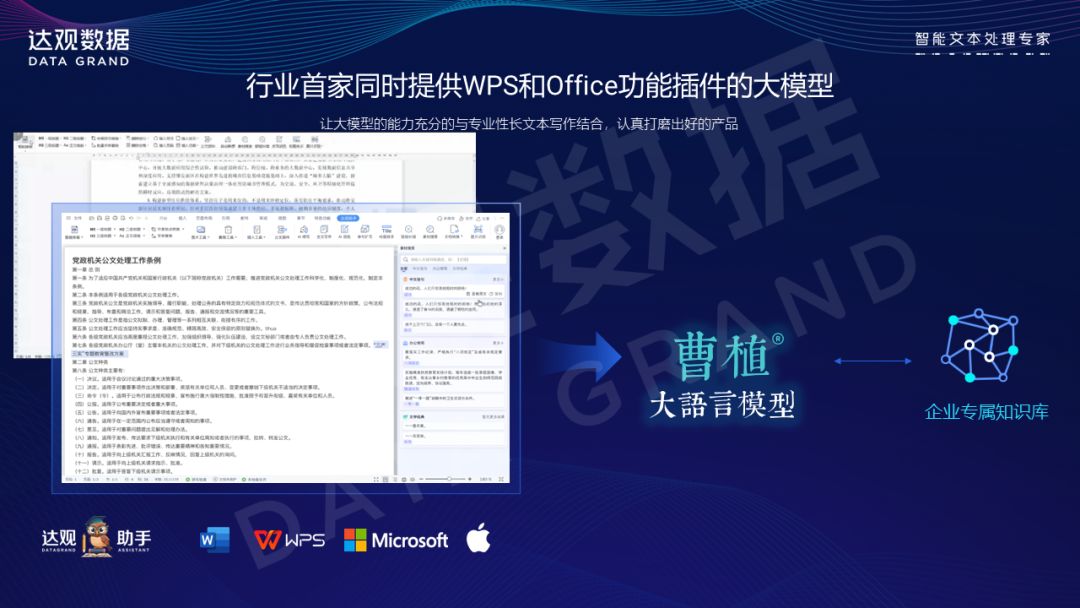
“曹植”大模型能力拓展
在过去的几年中,我们积极推动RPA产品的开发,并将其视为大模型能力拓展的重要组成部分。在当前的大语言模型时代,我们从企业的ERP、OA、知识库以及各种外部数据源中获取知识和数据,以提升大模型的能力。在这方面,我们深受GPT和复旦最新版本的MOSS插件库的设计理念的启发。同时,我们也看到,具有丰富插件功能的大语言模型,才能真正具有生命力,并发挥出巨大价值。

经过联调对接,“曹植”大模型已成功运行在燧原科技的GPU上,这是一次非常重要的里程碑事件。未来,我们有信心提供全国产化的解决方案,从算力到模型,为众多客户提供服务。
“曹植”大语言模型的应用开发仍在进行中,包括知识问答、智能写作、垂直搜索、文档审阅和机器翻译等。达观专注于垂直化、长文本、多语言的专业模型和专业应用的开发,“曹植”的强大性能也将体现在专业的长文本写作审核分析等方面。

未来,达观数据将持续积极研发升级“曹植”大语言模型,进一步夯实达观产业应用智能化基座,全面增强AI全产品矩阵能力。“曹植”大语言模型也是国内大规模语言模型中首批可落地的产业应用级模型,可持续赋能金融、政务、制造等多个垂直领域和通用场景人工智能的落地和发展,帮助企业实现数字化升级,降本增效。
作者介绍

陈运文
达观数据董事长兼CEO,复旦大学计算机博士,中国五四青年奖章,上海市十大青年科技杰出贡献奖获得者




