

近日复旦大学邱锡鹏教授等研究者提出新型分词方法,只有能 Cover 多个分词标准和最新 Transformer 的方法,才是好的中文分词方法。
从不同的角度看待中文句子,可能使中文分词任务(CWS)的标准完全不同。例如「总冠军」既可以看成独立的词,也能理解为「总」和「冠军」两个词。以前这种情况非常难解决,我们只能定一些字典或规则来加强这些词的划分。
但这些应该是分词模型应该要学的呀,我们不能只关注分词模型在单一标准中的表现,还需要关注不同分词标准中的共同特性。这些共同特性才是模型需要重点学习的,它们能构建更合理的分词结果。
鉴于这一点,复旦大学提出了一个简洁而有效的模型,它能适用于多种中文分词标准。这种模型使用共享的全连接自注意力机制,从而能根据不同的标准进行分词。
研究者已经在八个数据集上测试了这种基于 Transformer 的中文分词,它天然使用了多个分词评价标准。结果说明,与单一标准的学习不同,每个语料上的表现都得到了显著提升。
论文:Multi-Criteria Chinese Word Segmentation with Transformer
论文地址:https://arxiv.org/pdf/1906.12035.pdf
和英语不同,中文句子由连续的汉字构成,词语之间缺乏明显的分界线。由于词语被认为是最小的语义单位,因此中文分词任务十分重要。关于中英两种语言对自然语言处理的差异可参考达观数据创始人陈运文的文章《中文对比英文自然语言处理NLP的区别综述》。
目前中文分词效果最佳的方法是监督学习算法,它们将中文分词任务视为基于汉字的序列标注问题。在这个问题中,每个汉字都有对应的标签,用于表示词和词之间的分界信息。
然而,构建高质量的带标注中文分词语料面临两个挑战。首先,标注需要语言学专家,成本高昂。其次,现有几个相互冲突的、依据不同语言学角度的分词标准。
例如,对一个句子,不同语料的分词标准是不一样的,它们往往做不到一致性的分割。
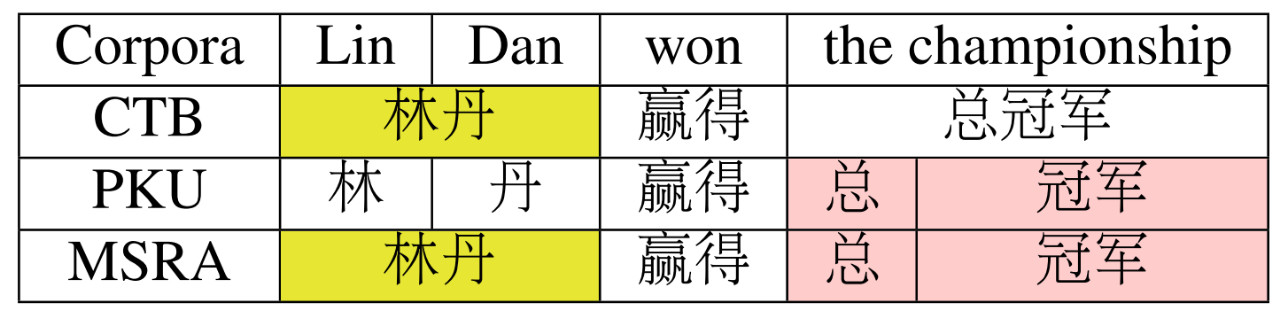
表 1:不同的分词标准对比。
如表 1 中所示,给定句子「林丹赢得总冠军」,在三个常用语料中,北大的人民日报语料(PKU)、宾州中文树库(CTB)和微软亚洲研究院(MSRA)使用的标注标准不同。
现在,大部分中文分词方法集中于提升单一分词标准的表现。如果不能完全弄清楚使用不同标准的语料特征,这种研究是浪费资源的。因此,如何高效利用这些(语料)资源依然是一个有挑战性的问题。
虽然很大程度上中文分词的难点在于标准不同,但幸运的是它们之间有一种共性知识。从一种分词标准学到的知识可以给其他语料带来收益。
在本论文之前的研究中,作者们考虑了一种多标准的中文分词学习框架。具体来说,它们将每个分词标准视为在多任务学习下的单独任务。在这个多任务学习框架使用一个共享层级,用于提取不同分词标准下都不变特征。同时有一个内部层级用于提取对应不同分词标准的特征,这个内部层也是共享的,因为不同标准经常有重叠的地方。
例如,在表 1 中,CTB 和 MSRA 对词语「林丹」的分词标准是相同的,三个标准对「赢得」的分词是一致的。因此,不同分词标准间是有相同知识的,模型学习它们也是可能的。
论文提出了一个简单的模型,模型能够共享来自多个分词标准中的知识,可以应对多标准中文分词任务。由于 Transformer 的启发,研究人员设计了一种完全共享的结构。在模型中,共享编码器用于抽取对分词标准敏感的语境特征(criteria-aware contextual features),而共享解码器则用于预测针对标准而不同的标签(criteria-specific labels)。最终,他们在 8 个不同的分词标准上进行了测试,使用了 5 个简体和 3 个繁体中文的语料。实验说明,模型可以有效提升在多标准分词中文任务中的表现。
模型架构
在邱锡鹏等研究者的论文中,编码器和解码器可以共享所有的分词标准。唯一的不同之处在于他们会采用唯一的指示器作为输入,从而分辨不同的分词标准。如下图 1 展示了研究者提出的方法和以前模型的不同之处。
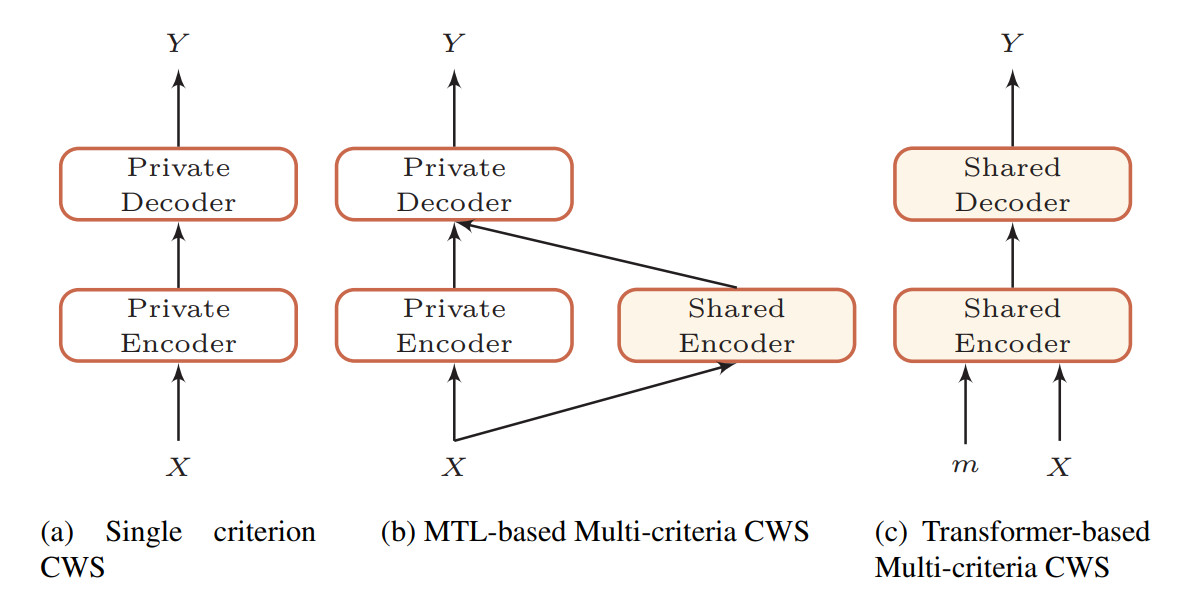
图 1:单分词标准和多分词标准所采用的架构,其中淡黄色的模块是不同标准所共享的部分。
如下图二展示了多标准中文分词模型的主要架构,其整体分为嵌入层、编码层和解码层。
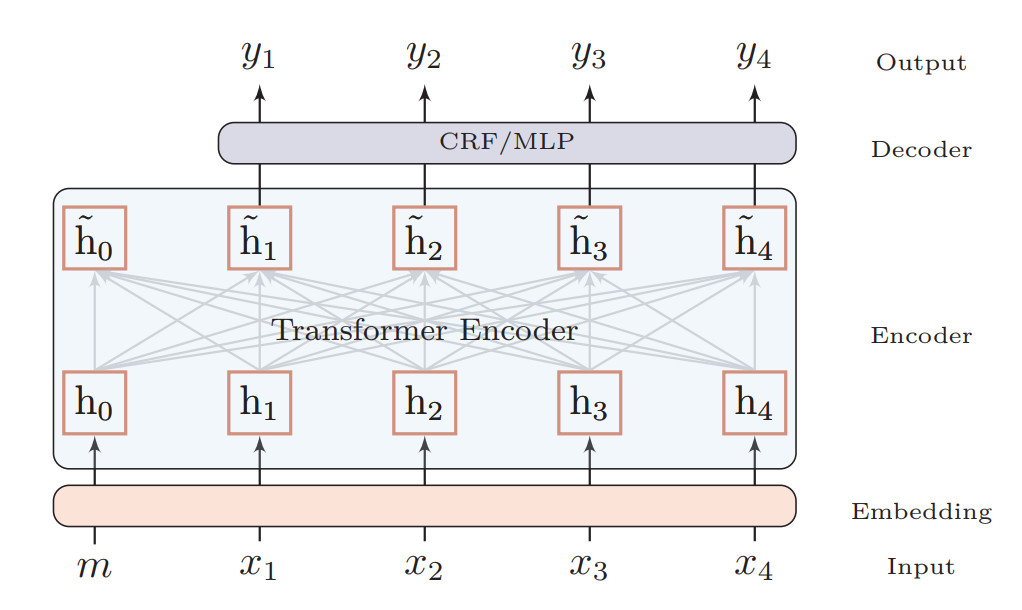
图 2:研究者提出用于多标准中文分词的模型。
嵌入层:嵌入层的目的即将词映射某个向量,除了标准的字符嵌入,研究者还引入了分词标准嵌入、位置嵌入、Bigram 嵌入三种额外信息。其中分词标准嵌入用来指定期望的输出标准;二元语法嵌入用于加强字符级嵌入的能力,从而实现更强的分词效果;最后的位置编码也就是 Transformer 所需要的位置信息了。
编码层:编码层就是一个 Transformer,主要会通过自注意力机制和 Multi-head Attention 模块抽取中文字的语义信息。
解码层:与标准多标准中文分词不同,新模型的解码层同样是共享的,这主要归功于嵌入层已经将分词标准的相关信息添加到字符上。研究者采用了条件随机场和多层感知机两种解码方式,并发现 CRF 效果要好一些,因此将其作为默认解码层。
从 SIGHAN200 到 SIGHAN2008,实验选择了 8 个中文分词数据集。在它们之中,AS、CITYU 和 CKIP 是繁体中文数据集,而 MSRA、PKU、CTB、NCC 和 SXU 是简体中文。除非另有说明,AS、CITYU 和 CKIP 都先从繁体转换成简体。
表 2 提供了 8 个数据集在预处理后的细节信息。整个实验使用标准的评价方法——评价精度、召回率和 F1 分数。
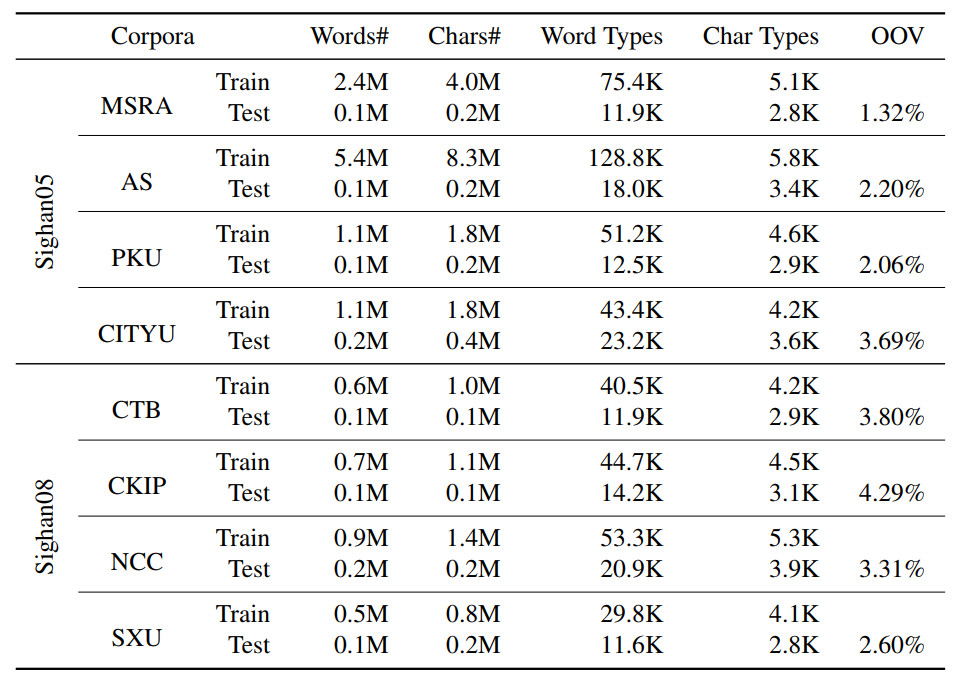
表 2:预处理后的 8 个数据集的具体信息。「Word Types」表示唯一词的数量,「Char Types」表示唯一字的数量。「OOV Rate」表示集外词所占的百分比。
表 5 展示了模型在 8 个测试集上的表现。
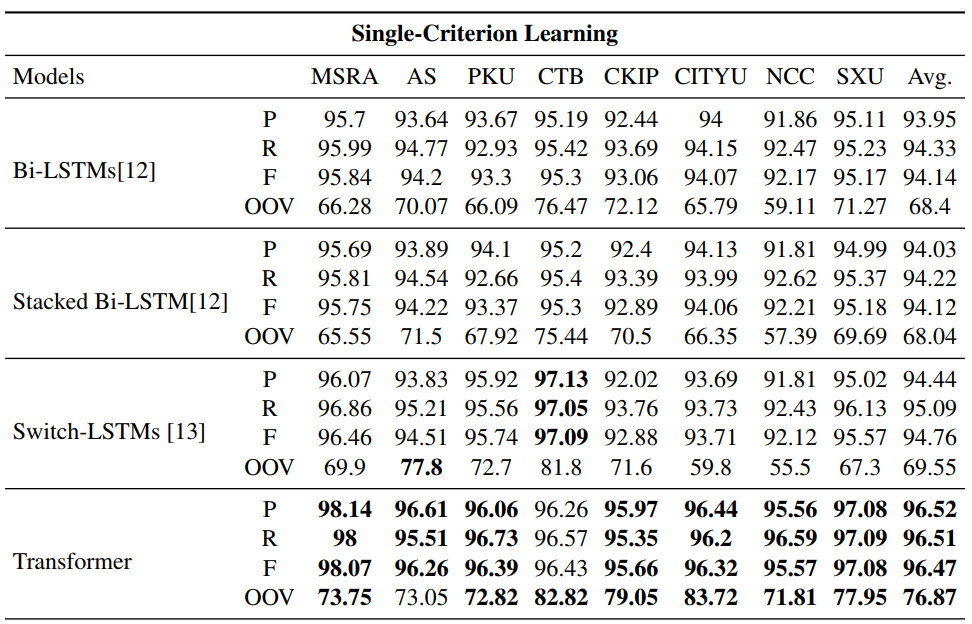
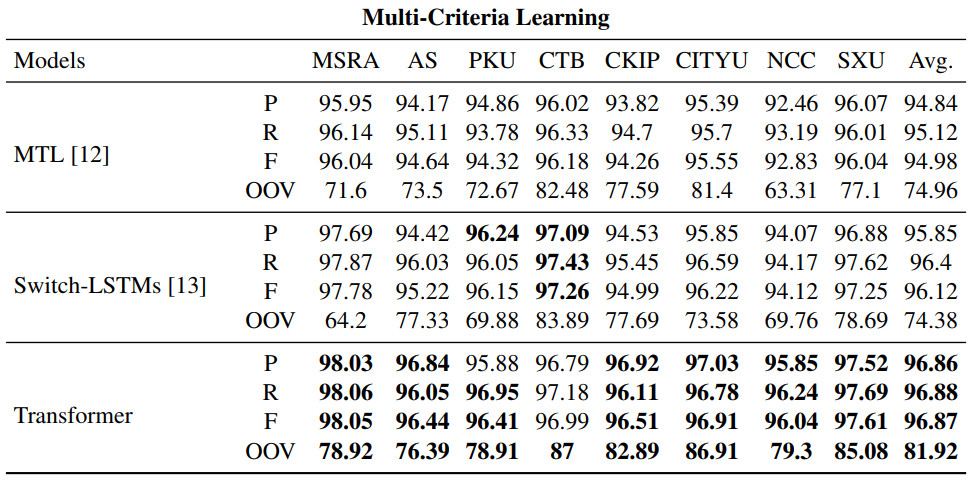
表 5:模型在测试集上的表现。P、R、F、OOV 分别表示精度、召回率、F1 分数和不在词表的词语的召回率值。每个数据集上最高的 F1 分数和 OOV 值已加粗。
下图 3 展示了 8 中不同分词标准的二维 PCA 降维结果,它们都是通过本论文的模型学习而来。我们可以看到,8 种分词标准在嵌入空间会映射到 8 个离散的点,这表明每一个分词标准都有所不同。其中 MSRA 与其它分词标准最为不同,可能的原因是 MSRA 将命名实体视为独立的词,这和其它分词标准有很大不同。
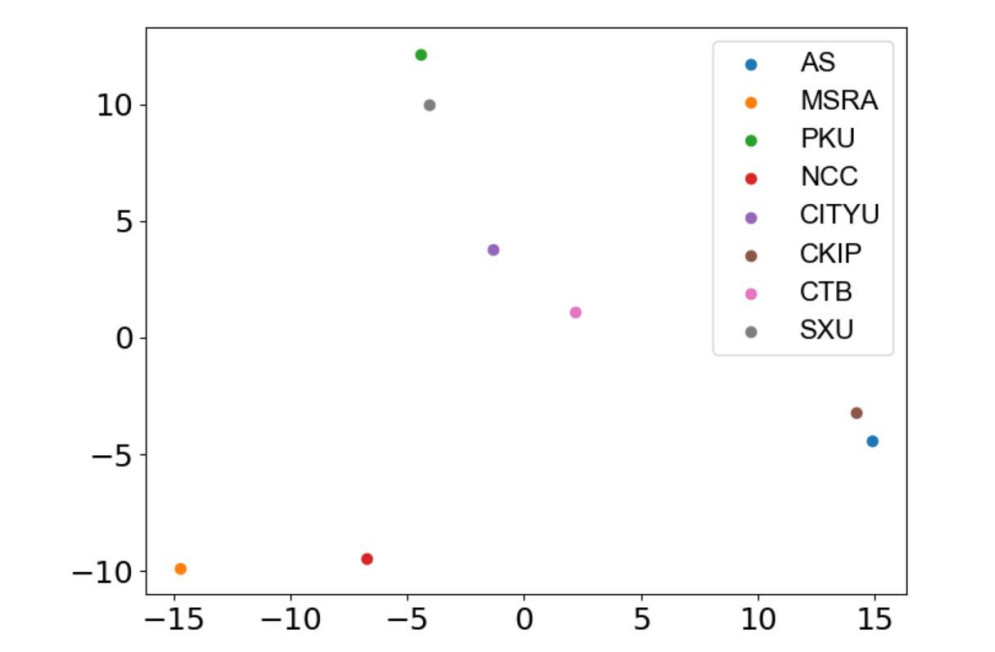
图 3:多标准中文分词学到的不同分词基准。
*本文转载自机器之心报道
第三届“达观杯”文本智能信息抽取挑战赛火热报名中
与全球小伙伴切磋交流
万元奖金,直通Offer等你来拿
扫码二维码或点击阅读原文直通比赛





