
人工智能新基建
2020“新冠”疫情发生以来,“新基建”成为热议。2020年初,时任国家发展改革委高技术产业司、创新和高技术发展司司长伍浩曾介绍,新型基础设施是以新发展理念为引领,以技术创新为驱动,以信息网络为基础,面向高质量发展需要,提供数字转型、智能升级、融合创新等服务的基础设施体系。
21世纪计算机及互联网技术高度发展的今天,企业数字化、信息化、智能化已相对成熟,在此基础上如何再创新?再发展?再升级?成为难题。据统计,就计算机应用而言,用于数学计算的仅占 10%,用于过程控制的不到5%,其余85%左右都是用于语言文字的信息处理。文本数据的高效利用与科学管理,已经成为各行各业升级发展的核心驱动力,特别对文本数据密集的企业而言,其主要业务基于大规模文本数据展开,面临着更大的文本数据治理挑战。例如,企业和机构存在大量的用户、产品、市场、采购等文本数据,数据难以利用;大量文本数据中多为非结构化数据,需要处理大量WORD、PDF、图片等非结构化数据;人工进行分析、分类、提取文本的工作量大。
运用NLP技术处理文本数据在企业日常运营及业务拓展中的迫切应用需要可见一斑。
NLP技术发展
自然语言是人类学习、生活的重要工具,区别于程序设计的人工语言,在整 个人类历史上以语言文字形式记载和流传的知识占到知识总量的 80%以上。
20 世纪 50 年代到 70 年代自然语言处理主要采用基于规则的方法,基于规则的方法不可能覆盖所有语句,虽然这一阶段虽然解决了一些简单的问题,但是无法从根本上将自然语言理解实用化。70 年代以后随着互联网的高速发展,丰富的语料库成为现实以及硬件不断更新完善,基于统计的方法逐渐代替了基于规则的方法,自然语言处理基于数学模型和统计的方法取得了实质性的突破,从实验室走向实际应用。
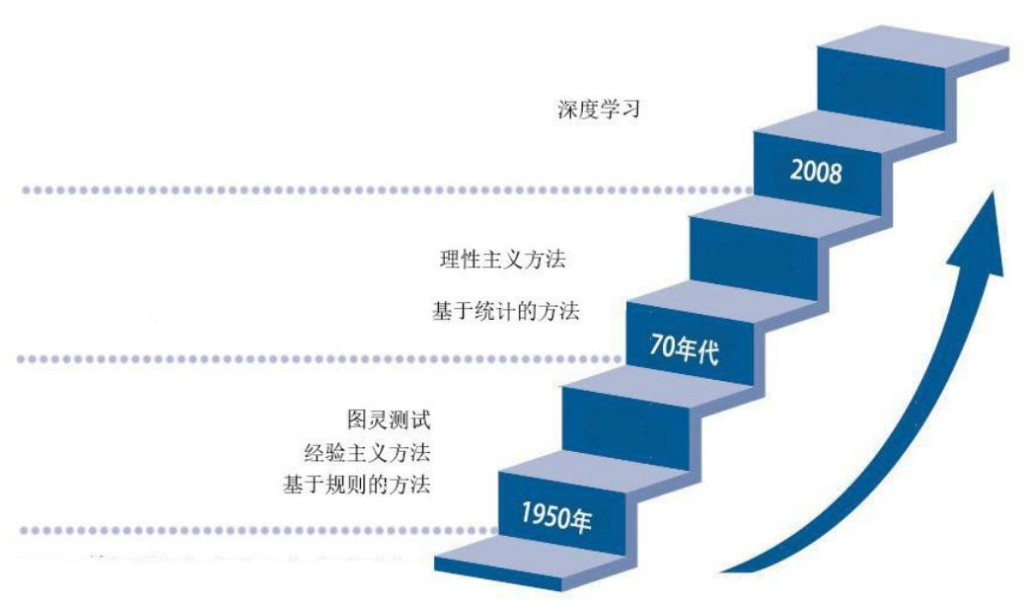
图片来源:2019人工智能发展报告
-
技术门槛高:缺乏AI专业人才,开发及应用部署门槛高; -
工具多且杂:数据采集、预处理、标注、训练、评估、预测等各个环节应用的工具不一,缺乏一站式AI平台支撑; -
操作复杂:模型开发及应用过程复杂,难以快速上手操作; -
数据泄露风险高:开发过程数据几经转换、传输,存在较大的数据泄露风险; -
模型持续优化难:模型训练、应用及优化闭环流程难以持续; -
开发成本高:开发速度慢、成本高、周期长。
达观数据 NLP平台助推AI落地提速
企业落地一个AI应用最快需要多久?在达观NLP平台的答案是三天,一个系统平台即可实现数据的导入、标注、训练、评估、预测全流程,模型生产时间大大缩短。平台内即可进行多人数据标注,具备人性化的标注界面;内置当前最先进的BERT、LSTM、CNN等NLP算法进行模型训练;支持针对训练的模型进行评估,确认模型效果;支持模型一键上线、批量进行模型预测;并提供模型导出及模型应用API的服务。
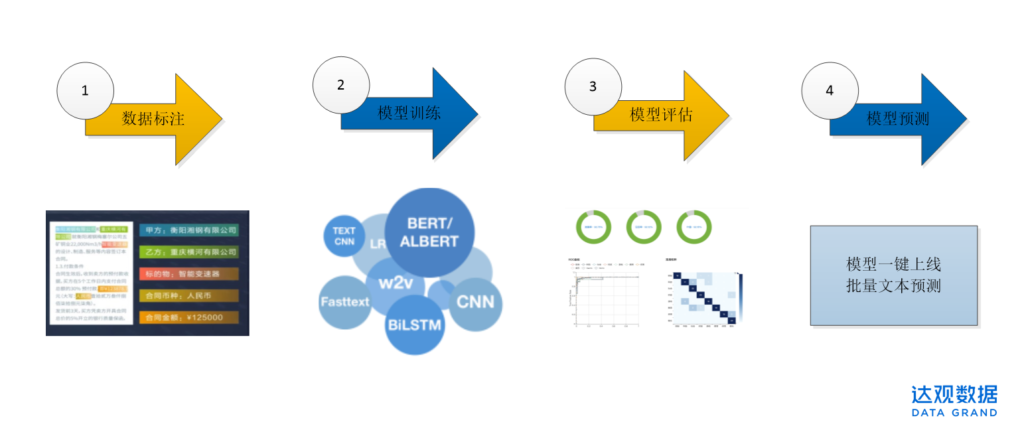
NLP平台之常见项目类型
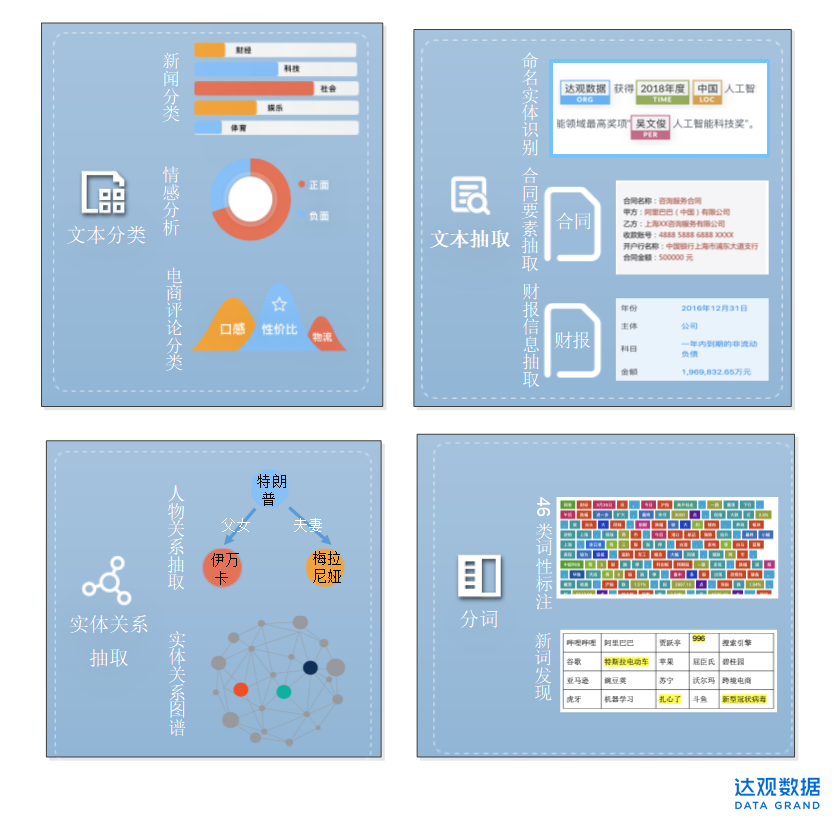
NLP平台之自定义模型
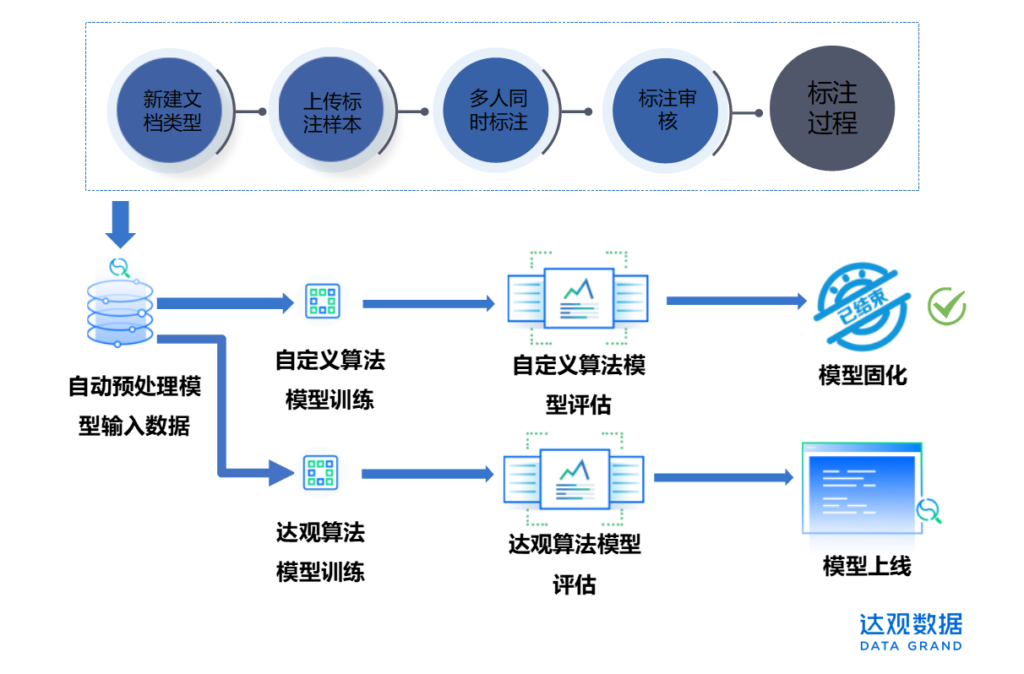
NLP平台之通用工具
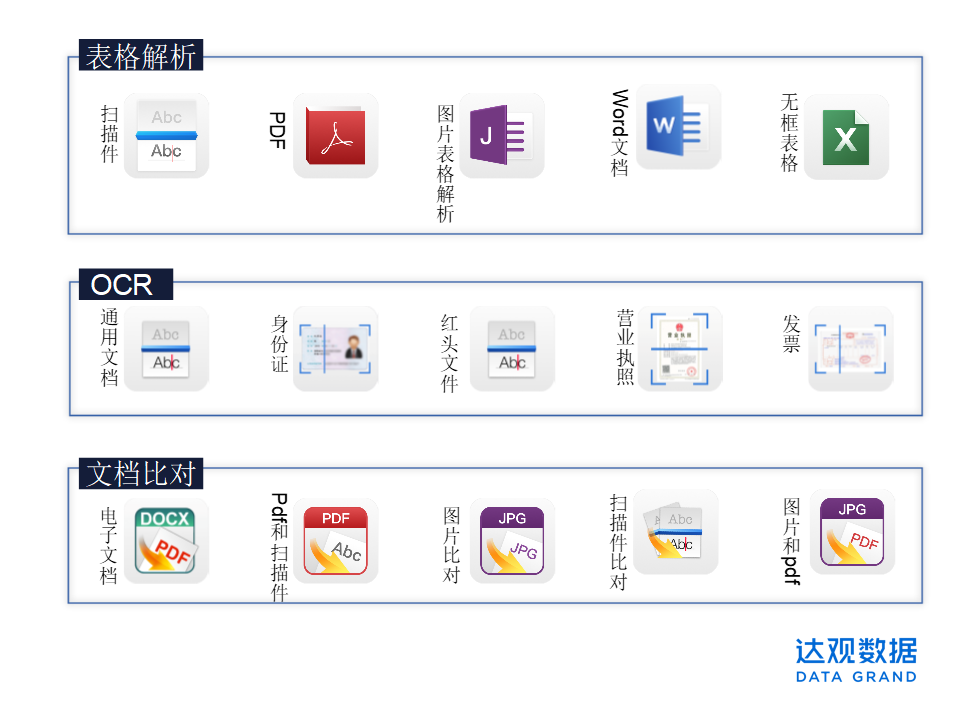
小结
2019年达观数据成功研发了基于Albert的深度神经网络算法模型,从根本上提升AI系统对语言文字的语义理解能力。目前达观数据自然语言处理平台已经成功服务深交所、时代地产等多家机构与企业。




