
前言
从人类的认知革命到人工智能的进化、发展,再到目前的AI应用,人工智能在不断技术迭代的同时,也加速激发了新兴行业业态。达观数据联合创始人高翔,坐客上海交通大学,与大家畅谈人工智能影响下未来办公发展新图景。
AI技术如何助力智能文档处理技术
为什么今天会讲到文档处理?我们测算了一下每个人大概每天有1/3的时间都在和文字打交道,所以对于文本自动化处理的市场需求非常大。
文本处理是非常复杂的一个过程。左边的图是让小朋友写作文,小朋友对“50岁的天津的哥马志刚”分词。他理解成“50岁/的/天津/的/哥马志/刚/拒收/了/一位/盲人”,其实是犯了一个分词错误,所以整个意思就发生了一些变化。这在分词任务里有个专业的名称叫做“歧义切分”。

让计算机来进行文字阅读理解有着非常大的挑战。
第一,计算机缺乏常识以及专业背景的知识。我们有很多背景知识、领域知识,计算机很难现在把领域知识全部都学到,它可能在某一个细分领域可以学一些简单的知识,但是学习一个通用领域的知识是比较难的,所以我们在想使用知识图谱或其他的技术是否能帮助计算机构建这样的通用领域知识,但现在挑战是比较大的。
第二,语言有丰富的上下文的语境。文字的抽象、模糊、歧义会加重计算机的理解负担。“苹果”,单这个词指的是苹果公司,还是吃的水果苹果,这个问题其实非常复杂,需要一定的上下文语境才能判断准确。

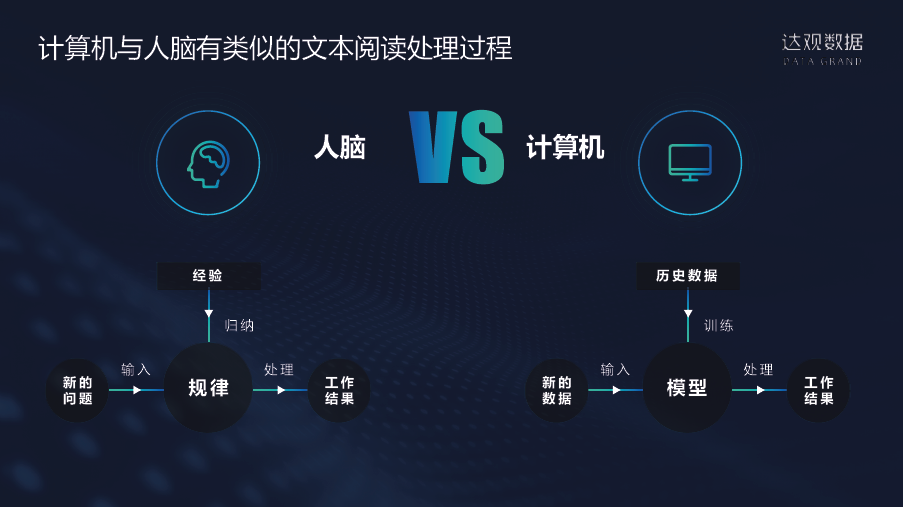
计算机能做这个事情,最主要的原因是计算机和人脑对知识学习的过程或者知识理解的过程是非常相似的。人看了很多书,学习这么多知识,本质上就是把规律总结成知识,新的问题可以根据我们的知识规律去处理,得到相关的结果。
计算机和人类相似,可以学习各种数据。数据一般分为标注数据和非标注数据,这些数据通过AI算法可以训练成各类的模型,一般来说解决一个具体问题都会有一个对应的模型。当预测新的数据时,模型根据内部的参数经过计算得出最终结果。
智能文档处理的难点与关键技术
难点
我们今天讲的是智能文档的处理,文档和文本的差异巨大,左边是一页华鑫证券的研报,这个研报的内容丰富,颜色、标题、图形、表格都排版很好,所以在看这个研报会觉得很舒服,除了从视觉角度看很优美,最主要的是我们可以一眼找到需要的各种关键信息。
但是如果把它里面的文本用软件或工具复制出来,可以看到右边这个大段的文字。大家看到这样大段的文字都比较头疼,很难找到需要的信息,而且发现因为失去排版信息的原因,有很多信息的顺序是不对的,空格、换行等信息都缺失了,很多有价值的信息就混到一起无法提取。所以最大的困难就是文档和文本之间的处理的差异非常大,所以我们要做好一个文档的难度非常高。

核心技术
第一个是文档信息结构化。第二个是文档风险审核,怎样审核文档内在风险。第三个是文档内容差异性比对,包括表格、文字的差异都可以去做比对。第四个是表格解析。第五个是扫描件信息识别,这块和OCR技术相关。
案例分享及展望
达观数据智能文档审阅平台是一个全行业覆盖的产品。
它的应用场景很多,和各种行业高度相关,因为几乎所有的行业都有大量的文档需要处理。
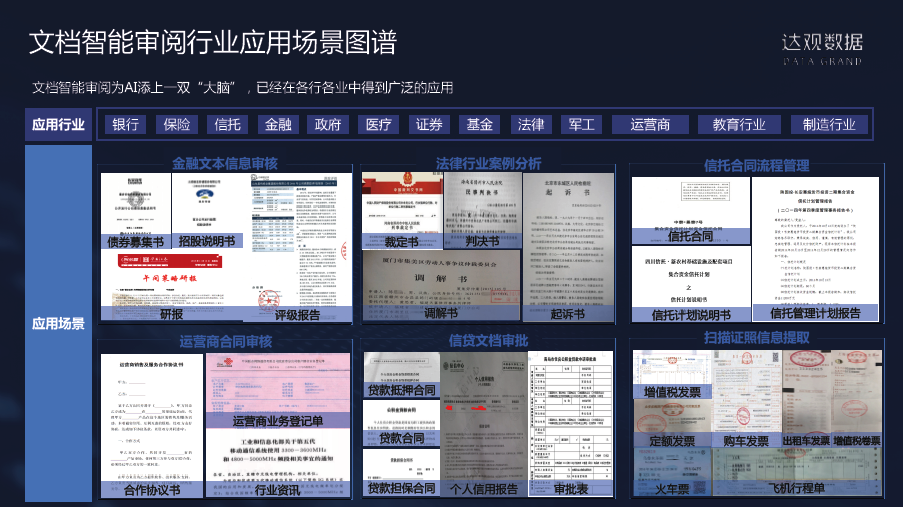
具体的案例
券商基金合同智能审阅时,虽然基金合同大部分是模版生成,但因为基金合同的甲方可能会比较强势,修改合同内部的条款和内容,所以它不是一个完全非标准的模板合同,因此无法使用模板快速提取关键信息,需要使用语义理解技术来自动提取,提取后做审核。
基金合同的金额比较大条款多,所以它的风险也比较大,这个审核工作需要非常细致。因为具备现成的平台,只需要把文件类型接口对接进来,加上之前的数据积累,所以只花3周时间就把基金合同信息提取效果做的差不多,F1值达到93%以上,现在的效果应该会更好并且客户已经把系统上线了,他们每天通过机器辅助的方式来做审核,提升效率。
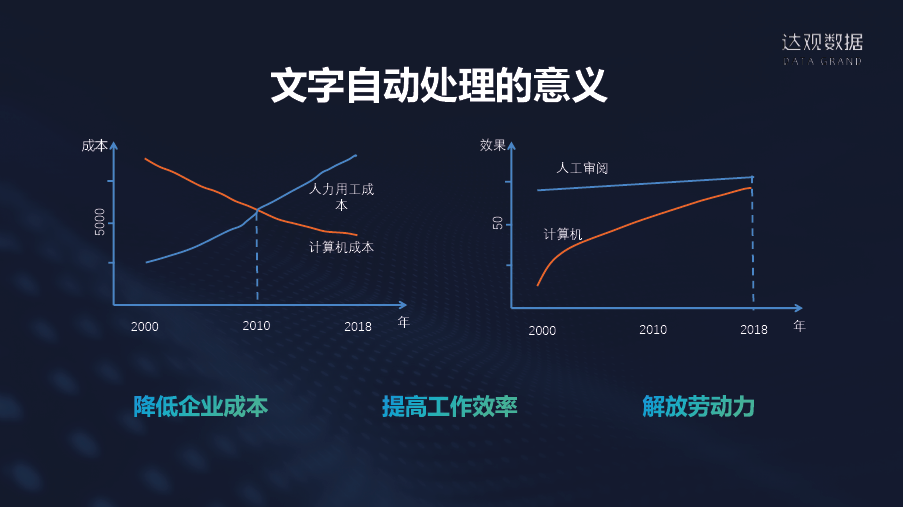
文字自动化处理的意义
降低成本、提高效率、解放劳动力。我们大概评估了一下,包括计算机处理能力和成本,在2010年算是一个节点,计算机相关成本越来越低,比如电脑现在越来越便宜。人工基本上已经到极限了或者说到瓶颈了,但计算机的能力会越来越强。
未来的展望
第一、从公司的角度来看,学术很重要,工程实践也很重要,不能只去关注所谓高大上的模型算法,而要实事求是选择最正确的方式来解决客户实际场景的问题。
第二、要把语义的分析和RPA技术做结合,因为两者做融合之后,计算机不仅在软件操作的“敏捷”程度上比人快,而且具备和人类似的思考能力,整个流程相对较纯人工会更快。
第三、希望各个产业可以结合我们的技术去落地很多应用,真正帮客户产生价值。10




