
信息过载时代,文本分类和文本标签是我们整合阅读文本信息的常用手段。本文系统介绍文本分类和文本标签的技术原理和应用价值,并结合项目案例谈谈两者的使用技巧。
一、分类和标签的共性与差异
图书管理员在给图书分类时,会根据书的内容、形式、体裁等信息,按照《中国图书馆图书分类法》进行分类。比如《射雕英雄传》,会分到文学>当代作品(1949–)>武侠小说。如果在豆瓣上收藏这本书时,豆瓣会推荐一些常用标签,“武侠小说”,“金庸”,“香港”,用户也可以自己创建标签,比如“郭靖黄蓉”“华山论剑”。
图书管理员对图书进行分类,属于专业的分类。豆瓣推荐的标签,是基于某种策略从用户打的标签库中选出。可以看出,分类一般是有标准体系的,而且在制定这种标准时,往往会考虑层次性和互斥性。逛图书馆时如果在A1类(马克思、恩格斯著作)的书架上,看到一本《射雕英雄传》,会觉得很突兀。标签是相对灵活和扁平的,豆瓣推荐的标签,“文学”、“中国文学”、“小说”、“武侠”、“武侠小说”,相互间有重叠交叉,用户也能接受。但不管是分类还是标签,其实都是人们用来对凌乱信息进行整合管理的手段。
二、文本分类和标签的意义与原理
在实际工程中,很多场景因为数据量大、时效性高,人为分析几乎不可能,比如客服对话文本、消费者发表的口碑评价、每时每刻产生的海量金融资讯等,这就需要借助计算机对文本进行自动分类和标签。下图就是通过达观自然语言处理引擎,自动对一篇红旗H7的车评文章(样本http://car.bitauto.com/hongqih7/koubei/977900/)打上标签和正负面类别。
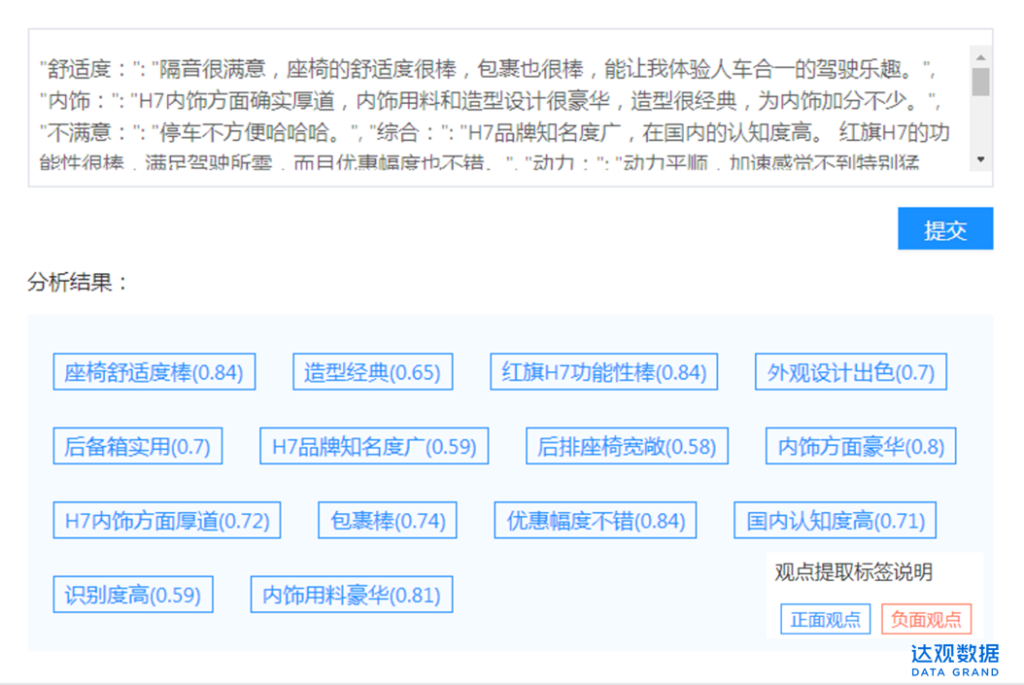
按照这种方式,我们分析更多篇车评,再对每篇车评分析结果进行一些统计和归并:


就得到下表的结果。
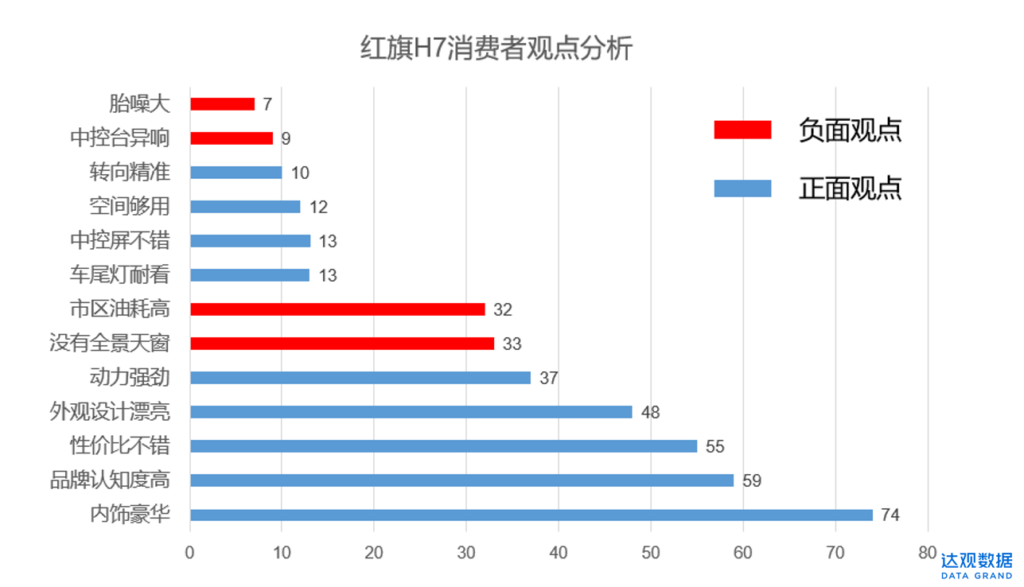
可见对红旗H7这款车,在消费者眼中,内饰豪华、外观漂亮、高性价比、高品牌认知度是其主要优点,油耗高、没有全景天窗是其缺陷。这样的分析结论对指导产品的营销投放、市场竞争、升级改款都具有很高价值。
上例中,从车评中提取观点标签使用的是一种文本标签技术,区分每个标签正负面,使用的是文本分类技术。计算机如何对文本进行自动分类和标签呢?简要阐述一下原理。先说分类。
文本分类的原理
文本分类是一种监督机器学习,一般包括如下环节:
- 定义分类类型,如事先定义好观点分为两类,正面和负面
- 准备标注样本,即准备好属于正面的观点标签和属于负面的观点标签
- 交叉训练,上述步骤获取的样本会拆分成若干组,一部分用来训练分类模型,一部分用来测试训练好的模型效果,并交叉验证。训练过程中,主要用到各类文本分类算法,包括SVM,RF,XGBoost,TextCNN等
- 评估和调优,用一个量化指标,比如分类准确率,去评估模型效果,如果效果不好,就需要通过调整算法、补充训练样本、调整特征、规则后处理等手段去优化,直到模型分类准确率达到一定效果,比如85%,再上生产环境运行
实际过程中,文本分类的效果取决于训练样本的数量和质量、选用的算法和特征、工程师的经验等因素。
文本标签
前文说过文本分类一般是有标准的、层次的、互斥的,而文本标签是偏平而灵活的,所以到底什么是标签,其实没有明确的定义。从应用角度来看,文本标签是一些概括程度高、语义简明扼要、用户耳熟能详的词或短语。豆瓣基于UGC票选产生的词符合这个准则,是一种标签。从红旗H7车评中提取的观点短语也符合这个准则,所以它也是一种标签。
介绍一下观点标签的提取原理。观察上述观点搭配,可以看出它们有一定规律,都是以观点主体+该主体属性构成。比如空间是观点的主体,够用是这个主体的属性。

根据这种规律,结合自然语言处理中的依存句法分析,就可以做一些初始提取。依存句法分析可自动分析出句子内“主谓宾定状补”等结构元素,识别词汇间依存关系。下图是达观依存句法分析模块的分析结果,我们取句子中的定中关系(用ATT表示)和主谓关系(用SBV表示),就可以提取“座椅舒适度棒”,“座椅宽敞”等观点标签。
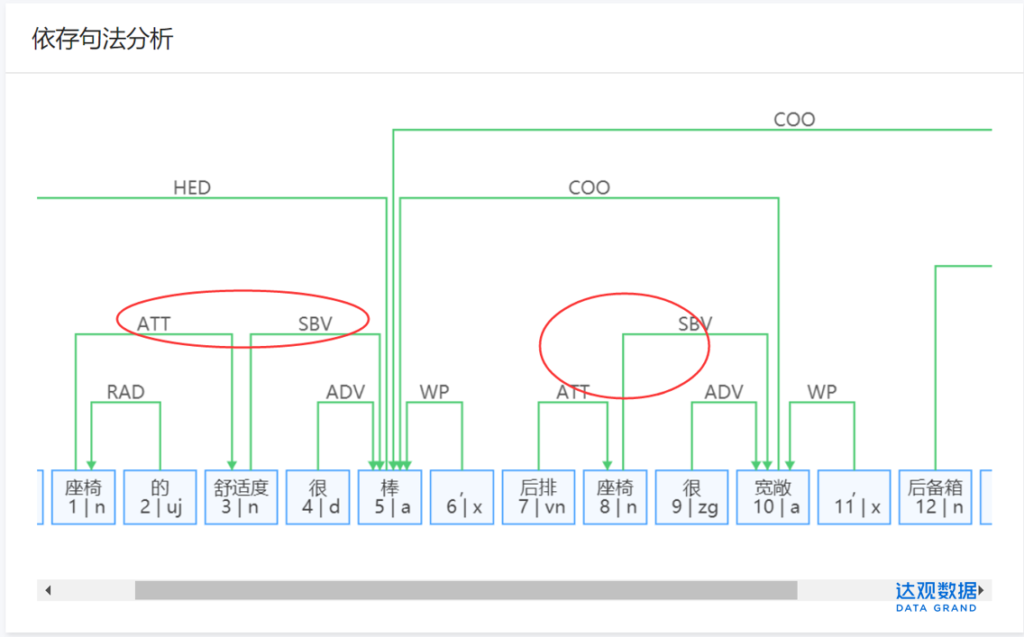
按照这种方法提取初始的观点标签,再结合词性、主体词库等过滤筛选,就会得到比较好的观点标签。除了UGC票选,观点标签提取,还有一类关键词标签。这类标签我们经常在一些词云分析中见到。还是那篇车评,我们利用达观的关键词标签进行分析,得到如下的分析结果,top5的关键词标签依次是:舒适度、红旗车、内饰、平顺、外观设计(蓝色值表示词权重,绿色值表示词频)。
这类关键词标签采用的主要算法包括TF-IDF及其衍生算法。TF-IDF的算法原理也很简洁。举个例子,疫情期间一张热干面加油的图让很多人感动。
为什么热干面是武汉的一个标签?很多人说那是因为武汉很流行吃热干面。但是武汉更流行吃白米饭,为什么不用白米饭做武汉的标签。有的人会解释道,白米饭太常见了,全国很多地区的人民都吃。所以,我们得到这样一个结论:如果一样东西在某地区越普及越流行,而在其他地区越冷门越少见,那这种东西就越能作为该地区的标签。
再比如说方言,四川人总爱说“要的”,非川普很少有人说,所以“要的”也可以作为四川话的标签。TF-IDF的原理和此类似:如果一个词在这篇文章中出现的次数越多,而在其他文章中越少出现,那么这个词相对于这篇文章就越具有代表性。感兴趣的读者可以去了解一下TF-IDF的具体公式。
总结一下:
利用大众票选的标签虽然有代表性,但是需要经过一定规模的用户参与、一定时间的沉淀,很多网络热词就是这一类,比如“地摊经济”,“新基建”;利用依存句法获取的标签,语义精炼,但提取难度大,需要结合业务梳理主体维度,因为标签其实也是一种行话,不同行业场景关注的主体不一样,比较适合垂直行业的观点、缘由、动机分析等场景;关键词标签实现简单,但它缺乏上下文,语义有缺失,更多的是作为中间分析过程。
三、文本分类和标签的实施方法论
前文我们介绍了分类和标签的差异、共性、应用价值和实现原理。最后一节介绍一下文本分类和标签的应用实践,并总结一些实施方法论(主要偏需求梳理和解决方案设计)。
我们在实施文本分类和标签项目的时候,一开始接触的是客户笼统的需求,并不像算法竞赛题一样已经有明确输入、输出、评估标准,需要我们去层层拆解。
以达观的真实项目为例,原始需求是客户希望从海量财经资讯中实时分析上市公司风险利好。
具体解题过程如下:
该需求解决谁的问题(用户是谁)
经沟通调研,需求的用户包括股票基金债券等投资交易者,投研分析师,银行负责企业贷款风控的客户经理,政府监管部门等。
了解具体用户有助于我们从用户视角去设计解决方案,因为好的分类和标签都具有行业标识性。
评估数据
包括评估数据质量、规模、来源等。这里要分析的数据主要是财经资讯,包括上市公司披露的信息、发布的公告、监管部门公开的信息等,主要都是PGC,内容质量较高,数据规模大,分析的时效性要求非常高。用文本分类和标签技术是不错的选择,因为文本分类和标签就是帮助我们去批量阅读和整合信息的。
站在用户视角设计分类和标签
用户希望从资讯中实时分析上市企业风险利好信息。分类可以设计成两维,情感正面/负面,或者利好/利空,我们取后者。但需注意,分析的主体是上市公司,并不是整篇资讯,一篇资讯往往会涉及多个上市公司。比如这样一条资讯:
“苹果将欧菲光剔除供应链名单后,欧菲光的触控订单大部分已归蓝思科技,蓝思科技子公司蓝思智控早已是大客户触控一级供应商。”
对于同属苹果产业链的蓝思科技和欧菲光来说,利好利空截然不同。所以我们要的分类是针对主体的分类。单单得到风险利好的结论还不够,还需要更明细的分析出是什么风险,哪里利好。分类显然不能解决这个问题,需利用文本标签。关键词标签的语义有缺失,大众票选周期太长、客观条件不具备,考虑采用观点标签。类比从油耗、空间、操控、内饰等维度去分析汽车口碑,从哪些维度去衡量上市公司的风险利好呢?
结合一些业务知识,梳理出如下维度:企业本身维度,比如市值,市盈率,股价,财报中的具体科目,生产经营层面(订单、市场规模、行业占有率等),高管,股东,商誉等,另外一些政策紧密性行业还需要一些专属的维度,比如医药许可,游戏版号,金融牌照等。
准备样本训练模型
设计好分类和标签的框架,就准备样本。分类我们需要标记出每篇资讯中上市公司实体和对应的利好/利空类别。标签我们要梳理相关的实体维度,需要去梳理依存句法关系。尽量让算法工程师拿到的是一个输入输出需求明确的问题。
结果调优
按照上面的流程,(此处省去算法工程师的辛苦工作)我们做出了如下的效果。

结果可以继续调整优化,比如利用文本相似度技术,把一些同近义标签进行归并,“高管贪腐”和“董事长助理受贿”归并为一个“高管贪腐”。这里我们就从一个笼统的客户需求到解决方案的实现。在这个过程中,我们依次完成需求拆解,用户调研,评估数据,选型方案,算法实现,结果调优,同时还需要具备一定的业务知识。其实这不单是文本分类和标签的实施方法,也是大部分AI项目的实施框架。
希望通过这篇文章,能让读者真切感受到,文本分类和文本标签是我们整合文本信息实现机器阅读的利器。




