

桂洪冠:大家晚上好!我是达观数据的桂洪冠,负责达观的搜索技术团队。非常高兴今天晚上能给大家做一个分享,分享的主题是“知识图谱的关键技术和应用”。
达观数据是一家专注于文本智能处理的人工智能技术企业,我们为企业提供完善的文本挖掘、知识图谱、搜索引擎、个性化推荐的文本智能处理技术服务。

言归正传,进入今天的演讲环节。今天的演讲主题是“知识图谱关键技术与应用”。
分成几个环节:
一、知识图谱的相关概述;
二、知识图谱的基本概念;
三、知识图谱行业方面的应用和场景介绍,着重讲一下知识图谱构建的相关技术;
四、达观在知识图谱构建方面的经验、心得和相关案例,最后是与大家的Q&A互动环节。

一、知识图谱的概述
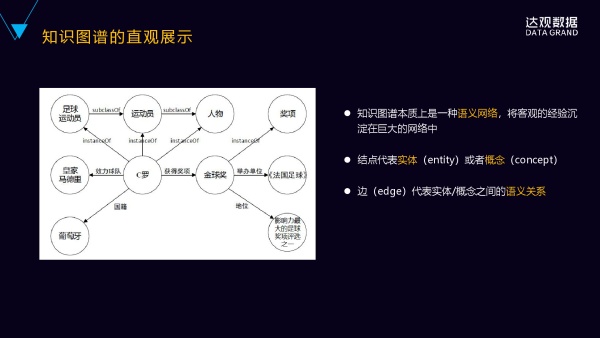
我们先直观的来看一下什么是知识图谱,下面有一张图,从这张图里可以看到,这个图里圆圈是节点,节点之间有一些带箭头的边来连成,这个节点实际上相当于知识图谱里的实体或者概念,边连线表示实体之间的关系。
知识图谱本质上是一种大型的语义网络,它旨在描述客观世界的概念实体事件以及及其之间的关系。以实体概念为节点,以关系为边,提供一种从关系的视角来看世界。
语义网络已经不是什么新鲜事,早在上个世纪就已经出现了,但为什么重新又提到知识图谱?
知识图谱本质上是一种语义网络,但是它最主要的特点是一个非常大规模的语义网络,之前的语义网络受限于我们处理的方法,更多是依赖于专家的经验规则去构建,在规模方面受限于特定领域的数据。
谷歌在2012年首先提出知识图谱的概念,在freebase的基础上扩展了大量来自互联网的实体数据和关系数据。据说目前实体的数据已经达到数十亿级,有达到千亿级的实例关系,规模是非常巨大的。
我们再看一下,知识图谱背后是怎么表示的,我们看到的是一个巨大的语义网,背后是怎么存储或者表示的呢?
首先,它是由三元组构成的,构成知识图谱的核心其实就是三元组,三元组是由实体、属性和关系组成的(由Entity、Attribute、Relation组成)。
具体表示方法为,实体1跟实体2之间有某种关系,或者是实体属性、属性词。
举个例子,“达观数据是一家人工智能公司”,其实就可以表示成这样的三元组:
<达观数据,is-a,人工智能公司>。
“人工智能公司是一种高科技公司”可以表示成:
<人工智能公司,subclass,高科技公司>。
“达观数据成立于2015年”,也可以把这个属性表示成一个三元组,就是:
<达观数据,start-time,2015年>。
基于已有的三元组,它可以推导出新的关系,这个对构建知识图谱来说是非常重要的。我们知道,知识图谱要有丰富的实体关系,才能真正达到它实用的价值。完全靠人工去做的话是不太现实的,所以内部一定有一个自动推理的机制,可以不断的去推理出新的关系数据出来,不断的丰富知识图谱。
来看一些具体的例子。
“人工智能公司是一种高科技公司”,subclass的关系。
还有一个三元组是谷歌是一家人工智能公司,<Google is-a人工智能公司>,可以由这两个三元组推导出谷歌是一家高科技公司,
<Google is-a高科技公司>。
因为subclass的实例之间是一种继承的关系。
<翅膀part-of鸟>,<麻雀kind-of鸟>,可以推导出<翅膀part-of麻雀>。
为什么要用三元组来描述知识图谱?
三元组是一个人和计算机都易于理解的结构,人是可以解读的,计算机也可以通过三元组去处理,所以它是一个既容易被人类解读,又容易被计算机来处理和加工的结构,而且它也足够的简单,如果说你扩充成四元组、五元组,它整个结构就会变得比较复杂,那是综合的一种复杂性和人的易理解性、和计算机的易出理性来综合的考虑,决定用三元组的结构来去作为它的一个存储。
那么,AI为什么需要知识图谱?
人工智能分为三个阶段,从机器智能到感知智能,再到认知智能。
机器智能更多强调这些机器的运算的能力,大规模的集群的处理能力,GPU的处理的能力。
在这个基础之上会有感知智能,感知智能就是语音识别、图像识别,从图片里面识别出一个猫,识别人脸,是感知智能。感知智能并非人类所特有,动物也会有这样的一些感知智能。
再往上一层的认知智能,是人类所特有的,是建立在思考的基础之上的,认知的建立是需要思考的能力,而思考是建立在知识的基础之上,必须有知识的基础、有一些常识,才能建立一些思考,形成一个推理机制。
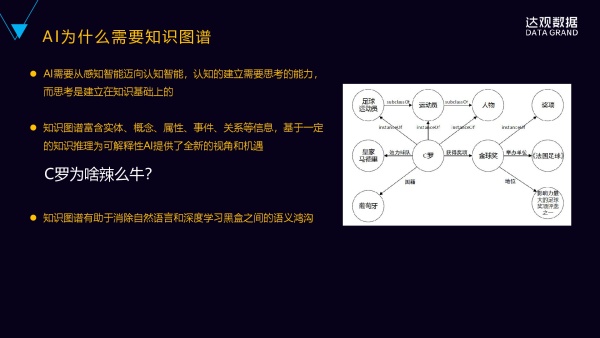
AI需要从感知智能迈向认知智能,本质上知识是一个基础,然后基于知识的推理,刚好知识图谱其实是具备这样的一个属性。
知识图谱其实是富含有实体、属性、概念、事件和关系等信息,它能够基于一定的推理。且比较关键的是,它能够基于一定的推理为AI的可解释性,带来全新的一个视角。
可解释性已被一些领域AI大规模使用。
医疗领域,AI进行癌症的诊断的结果,如果没有给出一个合理的一个理由,或者是给出一个解释的一个方法,医生是不敢贸然的用AI给出的癌症诊断的结果去给病人直接做下一步的措施。
金融领域也一样,AI如果给投资人推荐了一个投资的方案,但是没有给出任何的一个解释跟说明的话,也会存在巨大的一个风险。
同样,在司法领域也是一样,用AI进行判案,AI给一个案件判定一个结果,
但是没有给出任何的一个解释,也是不能作为结果来采用的,因为司法强调的就是一种可解释性,对法律的解释性、可推理性。
为什么说知识图谱可以做这样一个可解释性呢?
举个例子,我们问
“C罗为什么那么牛?”
这个是一个问题。
要解释回答这个问题,人通常是怎么样去回答这样的问题呢?
通过知识图谱的简单的推理,就可以回答这样一个问题。
因为C罗获得过金球奖,C罗跟金球奖之间的关系是获得奖项的一个关系,金球奖跟影响力最大的足球评选奖项之一有这样一个地位的关系,它具有非常高的地位,C罗又获得过这个奖项,所以可以得出,C罗是很牛的。
这是一种知识图谱来解释、来回答这样一个“为什么”的一个问题。
同样还有一些问题,比如
“鳄鱼为什么那么可怕?”
人类是有这样的常识,所有的大型的食肉动物都是很可怕,这是个常识。
鳄鱼是一种大型的食薄动物,鳄鱼跟大型食肉动物概念之间是一种instance的关系。通过这样的一个常识和概念之间的关系,可以推导出鳄鱼是很可怕的。
同样的,
“鸟儿为什么会飞?”
因为它有翅膀,鸟儿这个实体它的属性是有翅膀,利用一个实体跟属性之间的关系,可以做这样一个推理。
之前微博上关晓彤跟鹿晗非常的火,经常被刷屏,这是为什么?
因为关晓彤跟鹿晗之间是男女朋友这样的关系,明星之间的男女朋友的关系就最容易被大家追捧,也最容易被刷屏。
这个就是通过关系也好,通过实体的属性也好,通过实体的概念也好,可以去解释、去回答一些问题。
这些是知识图谱在AI在可解释性方面的一些具体的例子。
深度学习的可解释性非常差的,深度学习里面内部的语义表达、向量的表达都是一些浮点数,人类是非常难以理解的。深度学习出来的结果,它的可解释性也是非常少的。
尽管我们现在在研究可视化的技术,把中间的它的结果呈现出来、可视化出来,但是真正能达到对人有效的解释性进展还是比较缓慢的。
知识图谱实际上是有望能够消除人类的自然语言跟深度学习黑盒之间的语义鸿沟。也就是深度学习的底层的特征空间和上层的人的自然语言空间这种巨大的语义鸿沟,通过深度学习跟知识图谱结合起来,有望能够消除。
这也是为什么AI要结合知识图谱的一个原因。

来看具体的例子,通过知识图谱怎么样来理解自然语言?
在问答研究当中,理解自然语言来回答问题,是非常困难的。因为人对人的自然语言的表达方式丰富多样,然后同样的语义的问题的表达方式也是多样的。
比如,问上海有多少人口
“what is the population of shanghai?”
和图上是两种不同的问法,但实际上都是在问同样的问题。
看上去问法不一样,但表达的语义一样。
也有它的问法比较相近,但表达的语义完全不一样的。
比如
“狗咬人了吗?”
“人咬狗了吗?”
字仅仅颠倒的位置,语义就完全不同了。
当这个问题的答案来自知识库时,这一类的问题,我们通常称它为叫KBQA,叫“面向知识库的自然语言问答”。
KBQAI的核心步骤就是建立从自然语言的问答到知识图谱、知识库的三元组的位置映射的关系。
上面那两个人口的相关的问题,都可以映射到知识库当中的位置,叫“ population”。
通常比较简单的方法,就是记住这些所有的位置的映射的规则,记住这种句式,然后来套这样一个模板。但实际上这种做法是非常不灵活的,用同样的问法问北京、上海甚至其它任意一个城市的人口,这种方法就要去列举、去穷举,一种暴力式的记忆。
如果换一种方法,比如说我们有这样的叫
“How many people are there in City?”
我们做抽象,就是把上海、南京、北京上升到概念的程度,这个概念对应就是城市,城市有人口这样的属性,只要这个实例是属于城市的,实际上都可以去回答这个这样的问题。
因为“shanghai is_a city,beijing is_a city,nanjing is_a city”,它都是一个城市,所以它都可以依照上面的模概念模板,来回答它的城市对应的人口。
充分的利用知识图谱的概念和对实体的表示、概念的表示,然后再利用概念的属性,就可以比较好的能回答这一类的自然语言的语义问题。
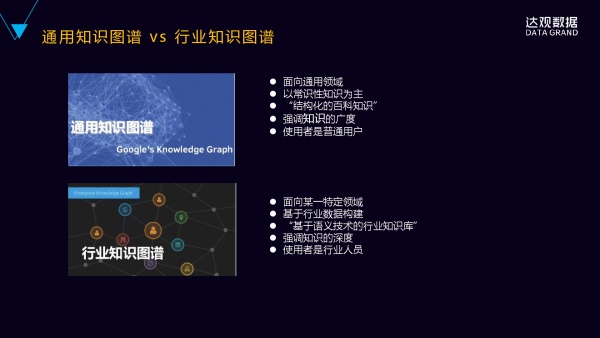
我们再来看一下通用知识图谱和行业知识图谱,它们这两个之间的区别。
通用知识图谱实际上是谷歌或者百度这样的大型的互联网公司在构建的,它主最主要是用于它的搜索引擎,它面向的是通用领域,它的用户是全部的互联网的用户,它构建是常识性的知识为主,包括结构化的百科知识,它强调的更多的是一种知识的广度,对知识的深度方面不做更多的要求,它的使用者也是普通的用户。
对于行业知识图谱来讲的话,它的整个定位就不一样,它首先是面向一个特定的领域,它的数据来源是来源于特定行业的语料,它是基于行业的数据来构建,而且要有一定的行业的深度,它强调的是更多的是深度,而不是广度,能够解决行业人员的问题,它的使用者也是这个行业内的从业人员,或者是这个领域里面的专业人员来使用。
通用知识图谱和行业知识图谱,个并不是说完全互相独立的,是具有互相互补性的关系。
一方面,通用知识图谱会不断的吸纳行业或者领域知识图谱的知识,来扩充它的知识面,然后增加它的知识的广度。
同时我们在构建一个行业知识图谱或者领域知识图谱的时候,实际上也并不是说只局限在这个领域的基本的数据,我们同时还要去通用知识图谱里面去吸纳更多的常识性的知识来作为补充,只有这样才能构成一个非常完整的行业知识图谱。
上面第一部分就讲完了,大概讲了一下知识图谱的概念,包括AI为什么需要知识图谱,以及举了相关的例子。第二部分我想更着重的讲一下知识图谱在行业里面的具体的应用。




