
众所周知,YouTube是世界上最大的视频网站,网站每天要面对着不同兴趣的用户,它需要从视频池中捞出当前用户感兴趣,想看的视频,以留住老用户吸引新用户,而这个功能就是视频推荐系统提供的。
而随着不同算法技术的兴起,推荐系统的核心算法也在发生变化。本文主要从YouTube推荐系统的四篇论文《Video Suggestion and Discovery for YouTube》、《The YouTube Video Recommendation System》、《Label Partitioning For Sublinear Ranking》和《Deep Neural Networks for YouTube Recommendations》入手,介绍YouTube对视频推荐系统的升级改造–在08年使用了基于用户-视频图的随机遍历算法,而到了10年,又升级为基于物品的协同过滤算法,而13年将推荐问题转换成多分类问题,并解决从神经网络最后的众多输出节点中找出最大概率的输出节点。此举也为16年将推荐核心算法升级为深度学习算法打下了基础。
论文简介
这四篇论文中,第一篇《Video Suggestion and Discovery for YouTube》和第三篇《Label Partitioning For Sublinear Ranking》重点是对推荐系统中使用的算法进行了一些说明介绍,但是对本身使用的推荐系统并未做详细介绍。
而第二篇《The YouTube Video Recommendation System》和第四篇《Deep Neural Networks for YouTube Recommendations》详细介绍了YouTube的推荐系统,它都由两部分构成,第一部分是候选集的生成,就是根据内容数据(比如视频流,标题,标签,类别等元数据)和用户行为日志(比如视频点击,观看时长,视频打分等)等信息来找出要推荐给用户的候选视频,第二部分是对这些候选视频进行排序,给出最优的或者top k最优的视频给用户。
下图就是YouTube推荐系统的大体流程:
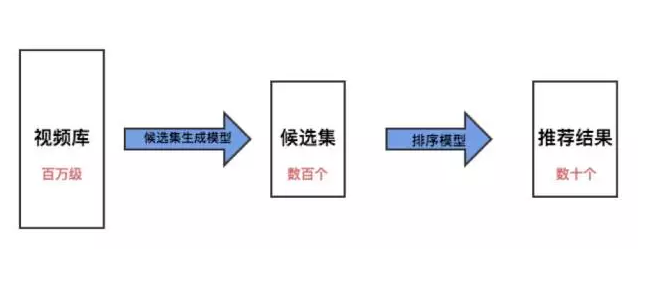
1. 基于用户-视频图的随机遍历
论文《Video Suggestion and Discovery for YouTube》是由Shumeet Baluja,Shumeet Baluja等人在2008年发表在 the International World Wide Web Conference Committee (IW3C2)上。文章花了大量篇幅讲了吸附算法(ADSORPTION),该算法的目的就是为了解决视频标签的扩散。所以就大胆推测当时YouTube推荐系统应该就是根据用户曾经看过的视频给用户推荐同类视频,也就是拥有相同标签的视频。
视频相关图
吸附算法是基于G图的,而这个图G=<V,E,W>就是视频间的关联度图,公式中V代表图中的节点,也就是一个个视频,注意节点会包含多个标签。E代表节点间的连线,也就是视频之间是关联的。而W代表边的权重,也就是视频之间的关联程度,文章中是用用户共同观看次数来表示这个权重,用户共同看过这两个视频次数越多,这个权重越大。如果没有,则两个视频间没有关联,也就是没有边。
TIPS
其实这个视频间的关联度就可以作为用户根据其中看过的一个视频作相关推荐的依据,这个也就是后来大名鼎鼎的基于物品的协同过滤算法,只不过当时的目光聚焦在标签扩散找同类上,而没有使用这个特征。
吸附算法
论文介绍了三个吸附算法,分别是通过均值的吸附,通过随机走的吸附和通过线性系统的推荐。不过这三个是等价的。而之所以叫吸附可能是因为算法的整个过程就是吸附节点 不断吸附标签的过程。
- 均值吸附
- 均值吸附的算法流程图如下:

图中G表示视频的关联图,L表示所有视频标签的合集,而 表示所有有标签视频节点的合集。
代表节点u的标签分布。整个流程很简单就是对每个视频节点,计算他们和其他节点的标签分布和边权重的乘积,然后归一化。
TIPS
标签分布就是每个视频节点中标签的分布,比如视频
有标签
,那么视频
的标签分布就是
占25%,
占50%,
占25%。
- 随机遍历吸附
很简单,就是将上图中
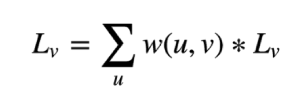
转换成
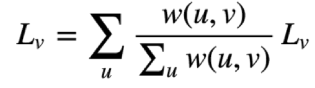
其中 表示随机遍历中选择节点u的概率。这样就好理解文中要有选择一个点进行吸附,并进行多次计算。
- 线性吸附
这个也很简单,就是将 理解为线性组合中占的比例。
2. 基于ItemCF的推荐系统
论文《The YouTube Video Recommendation System》是由Davidson J, Liebald B, Liu J等人在2010年发表在第四届ACM RecSys上。当时YouTube推荐系统的核心算法就是基于Item的协同过滤算法,换句话说就是对于一个用户当前场景下和历史兴趣中喜欢的视频,找出它们相关的视频,并从这些视频中过滤掉已经看过的,剩下就是可以用户极有可能喜欢看的视频。这里的视频相关性是用共同点击个数来描述的。整个推荐过程分为两步:
(1)计算视频之间的相关性
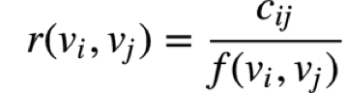
其中 表示同时看过种子视频
和和候选视频
的用户个数,
是个归一化函数,比如
概率等,对于给定的种子视频
是一定的,所以
。该公式有TFIDF的思想。
(2)根据视频的相关性和用户的历史行为给用户生成推荐列表。
生成推荐侯选集
① 生成种子集S
- 用户观看点击的视频
- 标记为liked的视频
- 添加进播放列表的视频
② 利用种子集S根据ItemCF生成候选集
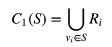
实际中, 中候选视频比较少,和种子集类似,没有了多样性。所有有了第三步递归扩充候选集。
③ 递归扩充候选集
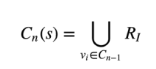
其中, ,它是作为最根本的一个候选集,再此基础上生成
,然后合并
和
作为种子集,生成候选集
,以此类推,生成最后多样化的最终候选集。
TIPS
不失为一种增加候选集多样性的一种方法。
排序
对于排序而言,有三方面影响排序的因素
① 视频质量相关: 能够证明用户喜欢视频的因素
- 视频观看次数
- 视频评分
- 视频评论
- 视频收藏和转发行为
- 上传时间
② 用户特性相关: 和用户的品味和喜好相关
- 种子视频的属性
③ 多样性: 推荐不同主题
- 限制单个种子视频得出的候选视频
- 限制同一个上传者的视频数量
- 主题聚类
- 文本分析
TIPS
在目前的推荐系统中,协同过滤的应用是最广泛的,它的优势很明显,就是个性化程度高,但是不可否认的是它的冷启动问题以及稀疏问题。而这两个问题可以被基于内容过滤推荐方法所解决,这二者的融合可以使推荐系统更加健壮高效。
3. 次线性排序的标签分区
论文《Label Partitioning For Sublinear Ranking》是由Jason Weston,Jason Weston等人在2013年发表在第三十届国际机器学习大会上。该论文将推荐问题变成了一个多分类的问题,并解决了在神经网络中如何从最后一层输出层中共找到概率最大的输出节点。
TIPS
这个算法的适用性很广,像多文本排序等。
算法说明
该算法基本的思路如下:
① 对于给定的样例x,根据训练样本的划分将其分到最有可能划分到的集合
② 取标签集q并分配给每个标签。
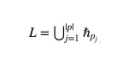
其中
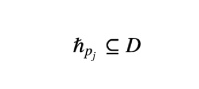
是标签被划分到 的子集
③ 对L中的每个标签进行打分,计算 ,并且根据最后的结果进行排序。
输入输出的划分
对于输入样例的划分,本文提到了两种,一种是Weighted Hierarchical Partitionr, 它的思想和加权的K-means算法一样,而权重是通过给训练样例xi到中心的距离cj一个根据label预测准确度得出的weight,另一个叫Weighted Embedding Partitioner,它是通过对训练样例的转换使得label相同的训练样例尽可能被划分到一个集合中取。实验结果显示,采用优化函数的分布的.
而对于对于测试输出的label划分,文中也提到两种方法,一种是设计优化函数,计算每一个label被分到一个partition后的loss,然后优化所有label划分的整体loss。另一个是简单的计算每一个partition内的label出现频率,选择出现最频繁的几个。实验证明,采用优化函数的划分方案比另一种提高1倍。
基于深度学习的推荐系统
论文《Deep Neural Networks for YouTube recommendations》是由Covington P, Adams J, Sargin E等人在2016年发表在第十届ACM RecSys上。这时YouTube推荐系统的核心算法是深度学习方法。该方法将推荐问题转变成一个分类问题,举个例子就是之前是用户在看了一些视频后,用户最有可能看哪个视频?这是推荐问题,而现在变成了用户在看过一些视频后(这里一个视频就是一个类别),需要预测下一个要看的视频是视频池中的哪一个分类。不过这个类别数目非常大。对于用户C和用户行为C,把语料库V中的视频i,在时间t时做出的分类为
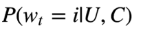
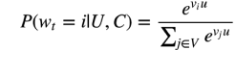
其中用户c包含用户的位置,性别等信息,用户行为C包含观看过的视频,搜索过的视频等信息,u代表用户及用户行为信息在高维的映射, 代表各个候选视频在高维的映射。
生成推荐侯选集
如下图所示,推荐候选集的生成是将推荐问题当做多类(百万个类别)分类问题。步骤如下:
① 将用户的历史信息(如观看历史、搜索历史)和其他特征(如地理位置、用户性别,发表时间等)接成向量,输入给由修正线性单元(ReLU)构成的非线形多层感知器(MLP),得到用户兴趣特征;
② 训练阶段时,将所有用户的兴趣特征输入 Softmax 进行多分类训练,获得模型;
③ 预测阶段时,计算用户兴趣特征与所有视频特征的相似度,用最近邻搜索获取分较高的 k 个视频给排序网络。
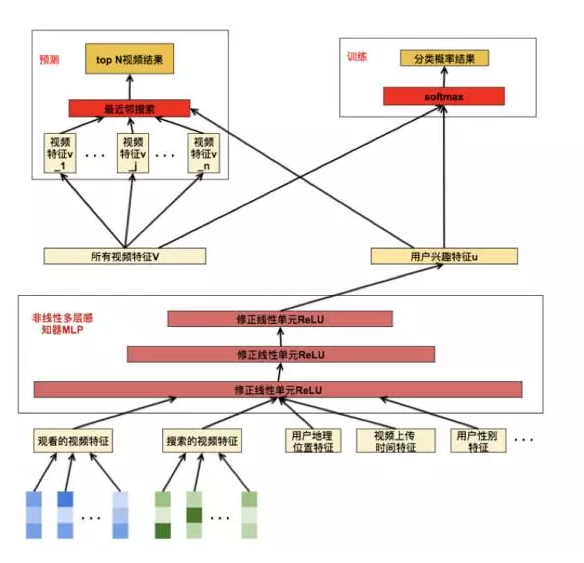
排序
排序的目的是将候选集中的候选视频再进行过滤一遍,挑出其中最适合的,用户最有可能喜欢看的视频给用户。文中用于排序的神经网络和生成推荐候选集的结构类似,唯一的不用只是在最后一层用逻辑回归给每个视频打分。由于候选集中的视频数目远远少于原始的视频池中数目,所以这个过滤过程中会加入更多的视频特征(比如视频图片信息)和用户特征,这样可以对用户进行更加精确化的推荐。 推荐的结果按照每个视频的得分进行排序,最后按照分数高低推荐视频给用户。
TIPS
而对于深度学习,它具有优秀的提取特征能力,能够学习到多层次的特征,将视频信息和用户信息中隐藏的特征抽象出来。像YouTube基于深度学习的推荐先用视频和用户的主要信息通过深度候选生成模型从百万级视频中找出数百个相关的视频,再用视频和用户的其他信息通过深度排序模型从数百个视频中找出几十个最有可能受用户欢迎的视频给用户。这样使得推荐系统对用户喜好的刻画能力大大增强,刻画的范围更加广泛。
4. 思考
从上面四篇论文中,我们可以看到YouTube一直在尝试将最热门的技术应用到推荐系统中,并不断的给系统进行升级进化,这样可以让它更好的在不同的环境下选择最适合的解决方案。简而言之,多个模型多条路。
参考文献
- Video Suggestion and Discovery for YouTube: Taking Random Walks Through the View Graph
- The YouTube video recommendation system
- Evaluating similarity measures: a large-scale study in the orkut social network
- Label Partitioning For Sublinear Ranking
- Deep neural networks for youtube recommendations




