

人类(Human)在生物分类学上就是“智人(Homo sapiens)”,这很能说明人类自身作为物种时,智力或智能是多么重要的一个因素!几千年来,我们一直试图了解人类是如何思考的,这包括了如何感知、理解、预测(决策)和操纵(行动)一个比我们自身大得多、复杂得多的世界。也因此,从几千年前,人类就开始向往制造智能的机器,这体现在许多的文学作品中。
在古希腊的神话中,赫菲斯托斯创造了塔罗斯和机械猎犬,其任务是保护克里特岛,这是神话中的智能机器人。同样的,中国三国时期的史料《三国志》和演义小说《三国演义》都提及,诸葛亮制造木牛流马来自动运输粮草,这也是一种对自动机器的期盼。艾萨克·阿西莫夫在 1945 年出版了《机器人》一书,机器人作为科幻中的角色,真正普及到普罗大众之中,“机器人三大定律”——不伤害人类、服从命令和保护自己——也闻名于世。而更现代的作品,像日本动画《天空之城》、美国影视《西部世界》、中国科幻大片《流浪地球》等,都在幻想着人造的能媲美人类甚至超越人类自身的智能体。
当然,作为严肃的学科,其诞生过程也非常漫长。从思想上,可以追溯到欧几里得的《几何原本》所开启的形式思维的结构化方法和形式推理。1700 年前后,戈特弗里德·莱布尼茨提出,人类的理性可以归结为数学计算,从哲学上开启了人类智能的探讨。1930 年,库尔特·哥德尔提出了不完备性定理,表明了演绎所能做的事情是有限的。1937 年,一阶谓词逻辑被提出,成为后来符号主义人工智能很长一段时间的主要研究对象。
1943 年,计算神经科学家皮茨和麦卡洛克发表的关于神经元的数学模型的论文“A logical calculus of the ideas immanent in nervous activity”(《神经活动中固有的逻辑演算》)是神经网络的开端,也是联结主义人工智能的开端,今天,它以“深度学习”的名义广为人知。1948 年应用数学家维纳(Norbert Wiener)出版了控制论领域的奠基性著作“Cybernetics: Or Control and Communication in the Animal and the Machine”(《控制论:或关于在动物和机器中控制和通信的科学》),开启了行为主义人工智能,在今天,其代表性技术是强化学习。
1949 年 7 月,数学家香农(Claude Elwood Shannon)与韦弗(Warren Weaver)发表了一份关于机器翻译的备忘录,这开启了人工智能的另一门子学科——自然语言处理。1950 年,图灵(Alan Turing)在论文“Computing Machinery and Intelligence”(《计算机器与智能》)中提出图灵测试,这是一种用来判断机器是否具有智能的思想实验。从此,讨论机器智能无法绕开图灵测试,而图灵奖也成为了计算机学科的最高奖项。1951 年计算机科学家斯特雷奇(Christopher Strachey)编写了西洋跳棋程序,被认为是符号主义人工智能的第一个程序。至此,人工智能三大范式和图灵测试皆已就位,人工智能成为一门学科也可谓只欠东风。
在人工智能诞生之前,技术和理论继续发展。1951 年,明斯基(Marvin Lee Minsky)和埃德蒙兹(Dean S. Edmonds)开发了具有 40 个神经元的随机神经模拟强化计算器(Stochastic Neural Analog Reinforcement Calculator,SNARC)。SNARC 模拟了一只老鼠在迷宫中奔跑并寻找目标的行为,是最早的复杂神经网络,也是最早的强化学习思想的应用。
1954 年,贝尔曼(Richard Bellman)把动态规划和价值函数引入到最优控制理论中,形成了现在称为贝尔曼方程的方法。早期人工智能最著名的“系统逻辑理论家(Logic Theorist)”,也开始于 1954 年。这是一个被后来许多人认为是人类历史上第一个真正的人工智能程序。逻辑理论家由纽厄尔(Allen Newell)、西蒙(Herbert A. Simon)和肖(Cliff Shaw)共同开发,并于 1955 年 12 月完成,最终证明了经典数学书籍 Principia Mathematica(《数学原理》)中前 52 个定理中的 38 个。同时,它还为其中一些定理找到了新的、更优雅、更简洁的证明。这项工作的论文于 1956 年 6 月 15 日完成(见图 1),1956 年 8 月在达特茅斯会议上进行了程序演示,1957 年论文正式发表在 IRE Transactions on information theory 上。

图 1 逻辑理论机器论文
人类的婴儿怀胎十月之后呱呱坠地,人工智能学科也一样,许多技术在学科诞生之前都已具备,就等待一个呱呱坠地的时刻。这个时刻就是 1956 年的达特茅斯会议。人工智能学科的诞生,不仅意味着人类知识的进步和社会的发展,也是我们了解人类自身为何智能的新机遇。
1955 年,麦卡锡(John McCarthy)、明斯基、罗切斯特(Nathaniel Rochester)和香农四个人提交了达特茅斯会议的建议书“A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence”(《达特茅斯夏季人工智能研究项目建议书》),申请了来年举办达特茅斯人工智能会议的预算 13500 美元。该建议书已经明确使用了“人工智能(Artificial Intelligence)”一词,并在建议书中提及了相关的议题:
-
模拟人类大脑高阶功能的自动化计算机;
-
如何编写计算机程序来使用自然语言;
-
神经元网络;
-
计算量的规模理论;
-
自我改进;
-
抽象;
-
随机性和创造性等。
这些议题至今仍是热门的研究主题。会议拟邀请近 50 位当时在计算机、数学、神经科学等领域的专家学者。
1956 年 6 月 18 日至 8 月 17 日,达特茅斯人工智能会议如期举办,虽然大部分拟邀请的人都没去,但会议至少包含 10 名与会者,包括 4 位发起人,以及阿瑟·塞缪尔、特雷彻·摩尔、雷·索尔马诺夫、奥利弗·塞尔弗里奇、艾伦·纽厄尔和赫伯特·西蒙(见图 2)。当然,由于每个人的研究方向各不一样,会议本身并没有任何值得一说的重大突破。但通过这次会议,人工智能领域的奠基性人物彼此认识,“人工智能”被与会者一致认可。自此,人工智能这门学科呱呱坠地。也因此,1956 年被业内公认为人工智能元年。

从 1956 年开始,人工智能开启了第一波高速发展的浪潮。1956 年语义网络(Semantic Networks)这个概念在机器翻译的研究中被提出来,这个概念经过 40 多年的演化,形成了现在的知识图谱。1957 年,人工智能三大范式皆有突破。联结主义流派提出了感知机(Perceptron),一台通过硬件来实现更新权重的计算机器;符号主义流派发明了 IPL (Information Processing Language),一种方便进行启发式搜索和列表处理的编程语言;行为主义流派提出了马尔可夫决策过程(MDP)的框架,一种最优控制问题的离散随机版本。此后,人工智能发展可谓一日千里。1958 年麦卡锡对 IPL 进行大幅改进, 推出了 LISP 编程语言,于 1960 年发布。1958 – 1959 年,几何定理证明器(Geometry Theorem Machine)和通用问题求解器(General Problem Solver,GPS)相继出现,这是接近于人类求解问题思维过程的人工智能程序。1960 – 1962 年,MDP 的策略迭代方法和 POMDP(Partially Observable Markov Decision Processes)模型被提出。
接下来是三个第一波浪潮中的典型代表系统。首先是塞缪尔开发的西洋跳棋程序在 1962 年 6 月 12 日挑战当时的西洋跳棋冠军尼雷(Robert Nealey)并获胜。其次是 1964 – 1967 年第一个聊天机器人 ELIZA 发布,它给用户一种具备理解人类语言能力的感觉,这让当时的许多用户认为 ELIZA 具备真正的智能和理解力,甚至具备感情属性。第三个是 1965 年开始开发的专家系统 DENDRAL(Dendritic Algorithm),这是一个模拟有机化学家决策过程和问题解决行为的化学分析专家系统,能够确定有机分子的结构。专家系统将在第二波浪潮中大显神通。
西洋跳棋程序、ELIZA、以及 DENDRAL 等众多人工智能程序及应用一方面繁荣了人工智能学科,同时也将整个社会的带入一种乐观的状态,许多人认为,十至二十年的时间内,真正的人造智能机器将会诞生。明斯基就曾说到“我相信,在一代人的时间内,机器将涵盖几乎所有方面的人类智能”——创造“人工智能”的问题将得到实质性的解决。1970 年 11 月 20 日的《生活》杂志刊登了一篇文章,标题是“遇见 Shaky,第一个电子人(Meet Shaky,the first electronic person)”。该文表达了对人工智能的极大乐观,甚至认为机器将取代人类。图 3 是文章的截图,巨大的文字表达“如果我们幸运的话,它们或许会决定将我们珍视如宠物。(If we are lucky, they might decide to keep us as pets.)”。彼时彼刻,是否恰如此时此刻?

图 3 我们对机器取代人类不止一次的乐观与期待
然而,乐观的情绪没有持续多久,就迎来了人工智能的第一个冬天。在二十世纪 60 年代末到 70 年代初,人工智能面临着许多问题无法解决,比如两个典型的难题是机器翻译和非线性的异或(XOR)问题。这些问题引起了人们对人工智能的沮丧,并使得政府大幅减少甚至停止了人工智能研究项目的资助。自 1969 年开始大约 10 年的时间,被称为人工智能的第一个冬天。
每一个冬天,都预示着下一个春天的来临和精彩。第一个人工智能的冬天,也不例外。在 1969 – 1979 年间,是专家系统默默吸收养分、扩展根基、积蓄力量的时间,并最终在 80 年代变得非常流行,应用到千行百业。专家系统是一种基于知识和模拟人类专家决策能力的计算机系统。自 DENDRAL 发布之后,许多专家系统在这期间被开发。比如,1972 年,著名的用于诊断血源性传染病的专家系统 MYCIN(见图 4)和用于内科诊断的临床专家系统 INTERNIST-I 开始开发和发布;1976 年,地质领域的用于勘探矿产资源的专家系统 PROSPECTOR 开始开发。
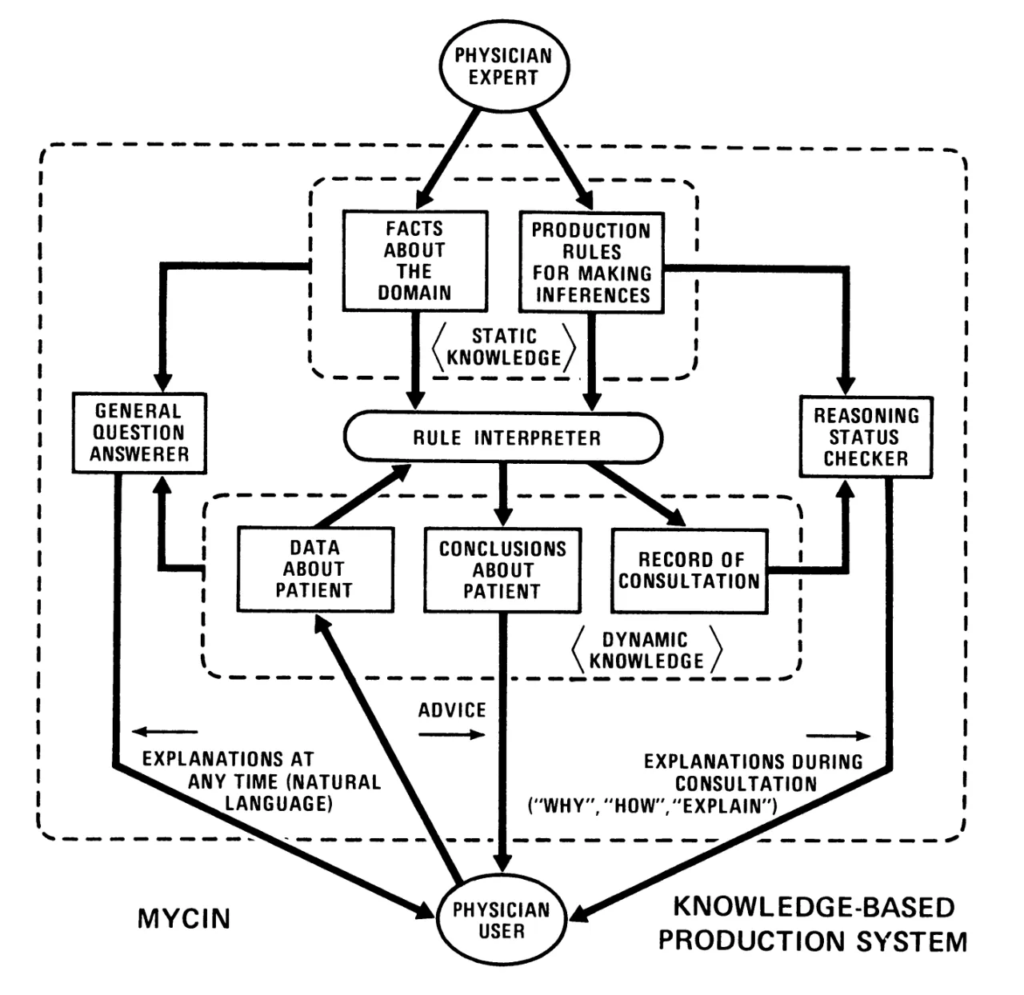
图 4 MYCIN 专家系统
事实上,在整个 1970 年代,专家系统就像肥沃土壤中的种子一样不断地吸收养分,并在许多狭窄的领域已经成功应用,只待时机一到,破土而出,拔节而长,蓬勃发展。而即将到来的 1980 年代,正是专家系统繁荣和收获的季节。
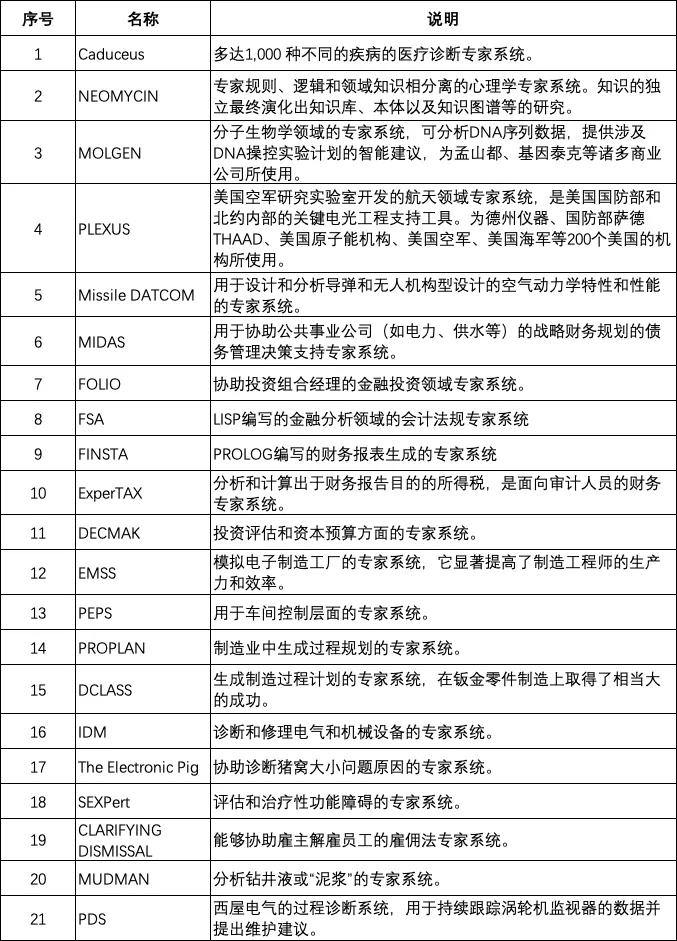
进入 1980 年代,专家系统的繁荣,使得人工智能成为一个新兴产业。其核心缘由之一是专家系统从非常狭窄的领域逐渐发展为通用化,并在千行百业上应用。典型的例子是 DEC 公司。DEC 公司从 1980 年开始持续多年开发了用于配置计算机的专家系统 R1(内部代号为 XCON)。截止 1986 年,R1 为 DEC 公司处理了 80000 个订单,平均每年节省了约 2500 万美元,其中 1986 年节省了 4000 万美元。到 1987 年初,R1 系统有 6200 条专家规则,以及 2 万个零部件的描述。此外,DEC 还开发了销售 XSEL 销售助手专家系统,该系统可以和 R1 进行交互,辅助销售人员销售计算机系统。另一个典型的例子是杜邦公司,到 1988 年已经建立了 100 个专家系统,每年为公司节省了估计的 1000 万美元,并有另外 500 个系统正在开发中。下表列出了一些 1980 – 1990 年代典型的专家系统,管中窥豹,可见一斑。
表 1 代表性的专家系统列表
如此大量的专家系统在各行各业应用,得益于面向构建专家系统的引擎、逻辑编程语言和知识库的出现和繁荣。在引擎方面,EMYCIN、ARBY、KEE 等是典型的代表。在编程语言方面,LISP、ROSIE 和 Prolog 是典型代表。特别是 Prolog,它以一阶逻辑为基础,用接近于自然语言的方式来编写逻辑与规则,是构建专家系统最好的编程语言。Prolog 的程序由两个主要部分组成:事实和规则,事实是被认为是真实的陈述,规则是描述不同事实之间关系的逻辑语句。
Prolog 等逻辑编程语言和引擎的流行使得构建专家系统愈加容易。在知识库方面则出现了本体,这是由麦卡锡在 1980 年从哲学中引入到人工智能学科的。关于本体,在《知识图谱:认知智能理论与实战》一书中,将本体总结为“‘存在’和‘现实’就是能够被表示的事物,本体被用于对事物进行描述,定义为‘概念化的规范’(specification of a conceptualization),用于表示存在的事物(the things that exist),即现实中的对象、属性、事件、过程和关系的种类和结构等等。自此,专家系统往往会“列出所有存在的事物,并构建一个本体描述我们的世界”(参见图 5),而这所列出来的,也往往被称为知识库。这些本体库或知识库,典型代表有 CYC、WordNet 等。
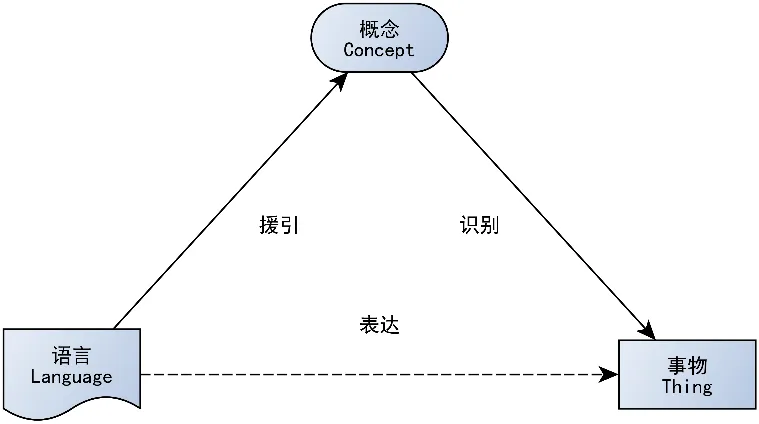
图 5 专家系统逻辑
专家系统的繁荣,将人工智能第二波浪潮推向巅峰,其标志是许多大学开设了专家系统的课程,世界财富 1000 强公司中有三分之二以上都在使用专家系统来处理日常的业务活动,涵盖了农业、商业、化学工业、通信、计算机系统、教育领域等,几乎包括人类生产生活的方方面面。《哈佛商业评论》在 1988 年的一篇文章认为“基于专家和知识的系统正在商业环境中迅速出现。我们调查的每家大公司都预计到 1989 年底将至少拥有一个使用该技术的生产系统”。
在第二波浪潮中,以专家系统为代表的符号主义人工智能是绝对的统治者。但在火热的专家系统之下,联结主义和行为主义人工智能也有着重大发展。1973 年 Tsetlin 自动学习机器和遗传算法被提出。1970 年代末到 1980 年代初,基于时间差分(Temporal Difference,TD)学习的各类条件反射心理模型被广泛研究。同一时期,联结主义的学者们则对神经网络的持续研究和演进,梯度下降和导数的链式法则相结合的反向传播终于被用到了多层神经网络的训练上。在网络结构方面,1980 年卷积神经网络的雏形 Neocogitron 已经出现。1982 年,论文“Neural networks and physical systems with emergent collective computational abilities”(《具有涌现集体计算能力的神经网络和物理系统》)提出了 Hopfield 网络。这篇论文的名字很有意思,是不是看到了一个很熟悉的名词,对,就是“涌现”!1985 年,玻尔兹曼机(Boltzmann Machine)被提出,其作者是后来获得图灵奖的辛顿(Hinton)。1983 年,强化学习中的经典算法 Actor-Critic 方法将显式地表示独立于价值函数的策略,Actor 即用于选择行动的策略,而“Critic”(批评家)则是对行动评估的价值函数。1986 年,限制玻尔兹曼机(Restricted Boltzmann Machine)出现,1987 年,AutoEncoder 模型被提出。1988 年,经典的强化学习模型 TD(λ) 被提出,旨在从延迟奖励中建立准确的奖励预测。1989 年,图灵奖获得者杨立昆(Yann LeCun)提出了 LeNet,这是一个 5 层的卷积神经网络。同年,Q 学习(Q-Learning)算法被提出,它是一种无模型强化学习算法,可直接学习最优控制的方法马尔可夫决策过程的转移概率或预期奖励。1991 年,循环神经网络(Recurrent Neural Network,RNN)出现。1992 年 Q 学习的收敛性被证明。1997 年,长短期记忆网络(Long Short-Term Memory,LSTM)被提出。
接下来,是第二波浪潮中的两个标志性事件。其一是联结主义和行为主义相结合的 TD-Gammon。TD-Gammon 是 IBM 利用 TD(λ) 方法训练神经网络而开发出的西洋双陆棋程序,发布于 1992 年。其游戏水平略低于当时人类顶级双陆棋玩家的水平。其二是 IBM 的深蓝(Deep Blue)打败了国际国际象棋世界冠军卡斯巴罗夫(Гарри Кимович Каспаров)。深蓝开始于卡耐基梅隆大学于 1985 年建造的国际象棋机器深思(Deep Thought)。1996 年 2 月 10 日,深蓝首次挑战国际象棋世界冠军卡斯巴罗夫,但以 2-4 落败。1997 年 5 月再度挑战卡斯巴罗夫,以 3.5:2.5 战胜了卡斯巴罗夫,成为首个在标准比赛时限内击败国际象棋世界冠军的计算机系统。赛后,卡斯帕罗夫勉强地说“计算机比任何人想象的都要强大得多。”
巅峰之后,人工智能开始变冷,人工智能研究的资金和兴趣都有所减少,相应的一段时间被称之为人工智能的第二个冬天。但另一方面,从现在来看,1990 年代,深度学习和强化学习的理论与实践已经非常成熟了,只待时机一到,就会再次爆发。《吕氏春秋·不苟论》有语“全则必缺,极则必反,盈则必亏”,人工智能的发展也如此。同样的,否极终将泰来,持续积蓄能量的人工智能,终究爆发出第三波浪潮。
在人工智能的第二个冬天中,明星的光环照耀在互联网浪潮之上,大量的资金投入到 Web,互联网大发展。这个过程中,专家系统和互联网相结合,万维网联盟 W3C 推动符号主义人工智能的发展。典型的代表性技术有资源描述框架(Resource Description Framework,RDF),RDFS(RDF Schema,RDFS, RDF-S 或 RDF/S)和语义网(Semantic Web),网络本体语言(Web Ontology Language,OWL),链接数据(Linked Data)。同样的,在这段时间中,许多实际和商业模式识别应用主要由非神经网络的方法主导,如支持向量机(SVM)等方法。然而,自 1990 年代起,多层神经网络已经成熟,只不过受限于算力太小,数据不足,而没有广泛应用。大约在 2006 年,多层神经网络以深度学习的名义开始火热起来,开启了人工智能的第三波浪潮。
2000 年,图灵奖获得者 Bengio 提出了用神经网络对语言建模的神经概率语言模型,图神经网络(Graph Neural Network,GNN)则在 2004 年被提出。2006 年,深度信念网络(Deep Belief Networks,DBN)、堆叠自编码器( Stacked Autoencoder)和 CTC(Connectionist temporal classification)相继被提出,深度卷积网络(LeNet-5)通过反向传播被训练出来,而且,第一个使用 GPU 来训练深度卷积网络也出现了,神经网络和 GPU 开始联姻。
这么多第一次,使得很大一部分人认为 2006 年是深度学习元年。此后,深度学习开始了轰轰烈烈的发展。2007 年 Nvidia 发布 CUDA,2008 年,去噪自编码器(Denoising Autoencoder)和循环时态 RBM 网络相继出现。2009 年语义哈希(Semantic hashing)概念被提出,这为后来的 Word2vec 以及大语言模型打下了基础。同年,华人深度学习的代表性人物李飞飞开始构建 ImageNet 数据集并从次年开始连续 8 年组织了计算机视觉竞赛。2010 年,堆叠了 9 层的 MLP 被训练出来。2011 年,在 IJCNN 2011 德国交通标志识别比赛中,深度卷积神经网络模型实现了 99.15% 的识别率,超越了人类的 98.98% 识别率。这是人造模型第一次超越了人类视觉的模式识别。此后,越来越多的视觉模式匹配任务中,人类都开始落后。2012 年,深度卷积网络在 ImageNet 的 2 万个类别的分类任务、ICPR2012 乳腺癌组织图像有丝分裂目标检测竞赛和电子显微镜(EM)层叠中的神经结构分割挑战赛等都超越了人类水平。深度学习在 2012 年首次赢得了 1994 年以来每两年进行一次的全球范围内的蛋白质结构预测竞赛中,这是神经网络在这个领域第一次露出头角,几年之后,AlphaFold 将会彻底解决这个问题。同年“谷歌猫”带着深度学习破圈而出,和大众见“面”!
在深度学习浪潮之下,语言和知识的发展也丝毫没有落后。大量的本体库在这期间被构建,典型的有基因本体 GO、SUMO、DOLCE、COSMO、DBpedia、Freebase、FIBO、YAGO、NELL,Schema.org、WikiData。然而,本体库中知识与逻辑互相交织,复杂程度高,导致不能与深度学习的研究成果相融合。2012 年 Google 将知识从本体库中分离出来,提出了知识图谱概念,并逐渐发展出一整套完整的体系,到十年后我创作的珠峰书《知识图谱:认知智能理论与实战》出版之时,该体系最终成熟,随后微软、百度、搜狗等也相继推出知识图谱。
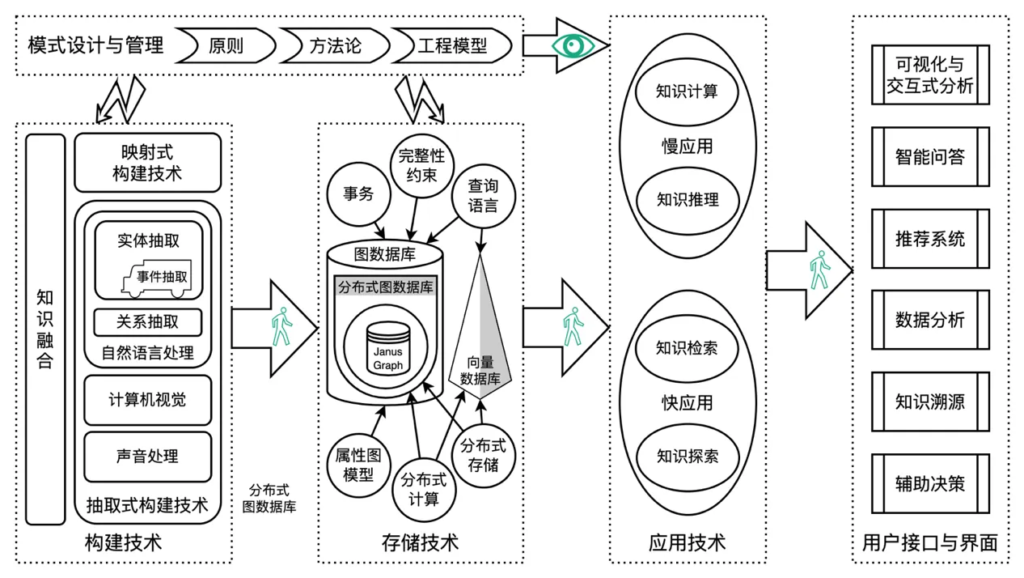
图 6 知识图谱技术体系
2013 年的重磅技术无疑是 Word2vec。2014 年,除了生成对抗网络(Generative adversarial network,GAN)外,最重磅的当属深度神经网络在人脸识别的准确率上超越人类。这个成绩先是由 Facebook 的 DeepFace 模型实现了首次接近人类表现。随后,汤晓鸥老师带领的团队连续发表三篇论文,不仅超越了人类的准确率,还持续刷新成级(在此特别纪念汤晓鸥老师)。人脸识别在当时不仅迅速出圈,比如在演唱会抓逃犯的吸引眼球的新闻。同时人脸识别也迅速成为广泛使用的身份认证的工具,比如用于火车站或者机场的身份认证等等。2016 年,经典书籍 Deep Learning《深度学习》出版,语音识别的准确率开始超越人类。
然而,这几年,最受关注的,当属 DeepMind 开发的围棋 AI 程序 AlphaGo,其思想与 20 多年前的 TD-Gammon 相似,融合使用了神经网络和强化学习的方法。2015 年 AlphaGO 战胜了职业选手樊麾,这是人工智能程序第一次战胜围棋职业选手。此后的 AlphaGo 加速进化,于次年(2016 年)以 4:1 的成绩战胜了曾获得世界冠军的职业选手李世石。2017 年,更强版本的 AlphaGo Master 以 3:0 的成绩完胜当时排名世界第一的职业围棋选手柯洁。随后,DeepMind 在 Nature 上发表论文,推出了 AlphaGo Zero,这是一个号称能够以 100:0 击败其前任的围棋 AI 程序。当时许多人都想起了 20 年前,IBM 深蓝击败国家象棋世界冠军之后,人工智能转冷。AlphaGO 是否意味着又一次人工智能的冬天即将来临?这是不少人的想法。
这个转冷并没有发生,反倒迎来了新的突破,预训练大语言模型的出现以及其所展示出来的高度智能水平。大模型浪潮发端于 2017 年,这一年,Google 提出了变换器网络 Transformer 和 MoE(Mixture of Expert)架构,OpenAI 和 Google 联合提出了通过强化学习来对齐人类偏好的 RLHF 方法,以及 OpenAI 提出了用于强化学习的近端策略优化算法(Proximal Policy Optimization Algorithms PPO)。变换器网络、MoE 架构和 RLHF 将在 2023 年大展身手,让人们无限期待通用人工智能 AGI 的到来。
2018 年,图灵奖颁布给在人工智能深度学习方面的杰出贡献者 Yoshua Bengio、Geoffrey Hinton 和 Yann LeCun,这是人类对深度学习的认可,也说明了人工智能在社会方方面面所起的作用。同年,更令人兴奋的则是 BERT 的出现,这是第一次在阅读理解上超越了人类专家水平的人工智能模型。语言一直都被认为是人类智能的标志性能力,而 BERT 的语言理解能力则被认为是人工智能的一次重大突破。BERT 的另一层启示则是证明了模型越大,能力越强,从此掀起了“规模战争”。同样出现在 2018 年的还有 GPT、Mesh-TensorFlow 模型和奖励建模(Reward Modeling)的方法。当然,它们在 BERT 的光耀之下黯然无色。
2019 年,GPT-2、ERNIE、RoBERTa、Megatron、T5 等众多大语言模型出现。同年,强化学习和深度学习的结合使得人工智能在开放复杂的实时战略游戏中崭露头角,这包括 DeepMind 的 AlphaStar 和 OpenAI 的 Five。在科学研究方面,FermiNet 用来求解近似计算薛定谔方程,在精度和准确性上都达到科研标准。2020 年,Google 提出了 Never Give Up 策略,用来求解复杂的探索博弈;微软则发布了 Suphx 麻将 AI,接近了人类顶尖麻将玩家的水平,这是人工智能在不完全信息博弈领域的突破。
2020 年出现了非常多的大语言模型,比如 Turing-NLG、ELECTRA、CPM 等,当然,大语言模型的明星当属 GPT-3,这是当时最大的预训练语言模型,具备零样本学习的能力。ViT 架构也出现于 2020 年首次将变换器网络用于视觉任务。从此,变换器网络开始一统深度学习领域。
2020 年最重磅的显然是 AlphaFold,这是一个用于解决蛋白质折叠问题的人工智能系统。2021 年改进版 AlphaFold2 被认为已经解决了蛋白质折叠问题,是“令人震惊的” 和“变革性的”。2023 年最新版的 AlphaFold 不仅可以对蛋白质数据库(PDB)中的几乎所有分子进行预测,并能够达到原子精度,而且还能够预测蛋白质折叠之外的其他生物分子的精确结构,如配体(小分子)、蛋白质、核酸等。
2021 年,从图像到文本的 CLIP 和 Forzen 等模型,从文本到图像的扩散模型和 DALL-E 等模型,以及 V-MoE(视觉 MOE)架构等相继出现,跨模态模型成为了新的热点。GLaM 则是第一个参数规模高达 1T(一万亿)的模型。OpenAI 则使用 GitHub 上的大量代码训练了专门用于生成程序的 Codex 模型,开启了代码大模型的研究。更为重要的是,2021 年 6 月 29 日基于 Codex 的 GitHub Copilot 发布,这是一款跨时代的产品,极大地提升了程序员的工作效率。
时间来到了 2022 年。首先是 OpenAI 推出了 InstructGPT,这是在无监督预训练语言模型 GPT-3 之上,使用有监督微调、奖励模型、人类反馈的强化学习 RLHF 等多种方法加以优化的模型,也被称之为 GPT-3.5。在 GPT-3.5 之上,OpenAI 于 2022 年 11 月 30 日推出的 ChatGPT,它是一个被许多人认为是能够通过图灵测试的聊天机器人。ChatGPT 的推出迅速出圈,发布仅两个月就有 1 亿用户参与狂欢,成为有史以来用户增长最快的产品。
2022 年还有几个关键的成果,这包括 MoE 架构中的 Expert Choice Routing 方法,在 Chinchilla 中国年探讨的规模法则,即大模型的参数规模、训练语料的规模以及计算量之间的关系,对齐了语言和视觉的 Flamingo 多模态大模型等。另外,一篇“Emergent Abilities of Large Language Models”(《大语言模型的涌现能力》)发布,让圈内外的人大谈“涌现”。还记得 1982 年的那个“涌现”么?2023 年,好风(ChatGPT)凭借力,全球范围内开始了百模大战。OpenAI 升级了 ChatGPT,推出了 GPT-4、GPT-4v 和 ChatGPT-4,并围绕着 ChatGPT 推出了 ChatGPT Plugins、Code Interpreter、GPT Store、GPT Team 等。同时,微软基于 OpenAI 的 GPT-4,推出了 Bing Chat(后来改名为 Bing Copilot)、Office Copilot 等产品。Google 则推出了 Bard、Gemini,Meta 推出了 LLaMA、LLaMA2 等,Twitter 推出了 X.ai 和 Grok。国内的百模大战更是激烈,截止 2024 年 1 月,国产大模型超过 200 个。典型的国产大模型有百度的文心一言、智谱华章的清言、阿里云的通义千问、上海人工智能实验的书生、达观数据的曹植,深度求索的 Deepseek Coder、科大讯飞的星火、抖音的豆包等。在产品方面,字节跳动也推出了 Coze,这是类似 GPT Store 一样的产品。除了大模型之外,Google 在 2024 年初提出的 AlphaGeometry 极大地提升了数学领域的推理能力,这是一个才用了神经符号学的方法,是联结主义和符号主义相融合的模型。
1951 年,图灵发表的一个演讲“Intelligent Machinery, A Heretical Theory”(《智能机器:一种异端理论》)中提到“一旦机器思考的方法启动,它很快就会超越我们脆弱的能力。机器不会死亡,他们能够相互交互来提升彼此的智慧。因此,就跟我们预期的一样,机器将会掌控一切。”但真如同图灵预期的那样了么?70 多年过去了,图灵所预期的那个机器掌控一切的时代仍未到来。
2022 年底,ChatGPT 再一次掀起了人们对人工智能的极大范围的讨论,而这一次,人工智能将会走向何处?显然,人们观点并不一致,就连图灵奖获得者辛顿和杨立昆的立场也完全相反。辛顿认为通用人工智能将会很快到来,他致力于通用人工智能向善、通用人工智能与人类的和平共处。而杨立昆则相反,认为大模型固然能力很强大,但大模型的原理决定了它无法产生通用人工智能。而我认为大模型给通用人工智能带来了曙光,但这条路真的能实现通用人工智能么?我也没有答案。我曾经对符号主义人工智能的历史进行了深度的研究,这一次我仍然相信“以史为鉴,可以知兴替”。于是乎,我转向历史,去寻找蛛丝马迹,寻找能够指引未来的那道亮光,而这篇文章算是一个总结。
当然,现在我仍然没有答案。但我发现,在前面两波人工智能浪潮中,乐观者跟辛顿所代表的乐观者一样,人们多次预期机器智能超越人类,但随后并未实现。我也发现,每一波人工智能浪潮,都在前一波浪潮的基础之上,应用面更为广泛,影响更为深远。
但是有一点,单纯依靠大模型是无法实现通用人工智能的。从前面所介绍的历史来看,符号主义、行为主义和联结主义,都是智能的一部分在人工智能学科上的体现。也就是说,人工智能三大范式的融合,是实现通用人工智能的基础。这点与我一直在普及的“大模型+知识图谱+强化学习”的理念是一致的。另一方面作为实干家、实践者,我认为,不管通用人工智能是否能到来,至少在应用上,现阶段的人工智能是一个新的起点。未来 10 年,人工智能在全社会全人类的应用上具有无限的可能、无限的机遇。大家可以想象一下,千行百业都在大模型、知识图谱等人工智能技术的帮助下,生产力成倍地提升,社会价值和经济价值是多么巨大!
当然,现阶段,有许多问题在不断地被讨论。但事实上,这些问题在前两波浪潮中同样被不断讨论。比如人工智能是否会取代某些职业(比如医生等),事实上是绝大多数职业至今并未消失,而是在人工智能产品的帮助下更好地服务人类,制造出更高级的产品等。又比如,这种强大的产品危害人类的问题,但危害人类的并非这些产品,而是一部分人类利用这些产品对另一部分进行伤害。对此,我觉得,既要以史为鉴,但也不能刻舟求剑。同时,我一边期待一边呼吁,科技向善,人工智能向善!
当然,还有很多很多关于智能的未解之谜有待我们去探索。知识从何而来?人类为何而智能?心智是如何从物理大脑中产生的?智能是否可以计算?人类是否能够在并不了解自身智能的原理下制造出真正智能的机器?人类智能真的和现在这些人工智能算法相似么?人工智能如何帮助我们更好地理解人类自身?至今我仍然未能看到答案。这或许是进化论最伟大的奥秘。




