在企业数字化转型的深水区,非结构化文档已成为数据价值挖掘的 “沉睡宝库”。金融机构的万字募集说明书、医疗系统的复杂检验报告、企业日常的海量合同票据,这些涵盖 PDF、扫描件、图片等多格式的文件,长期依赖人工解析录入,不仅效率低下(单份 10 万字文档需 3 小时处理),更因 18% 的高错误率埋下决策隐患。据 Grand View Research 报告显示,2024 年全球知识管理软件市场规模已达 201.5 亿美元,预计 2033 年将突破 621.5 亿美元,复合年增长率 13.6%,这背后正是企业对非结构化数据处理需求的爆发式增长。达观数据基于大模型打造的智能文档处理平台,以 “RPA+AI” 双轮驱动构建自动化内容解析中枢,彻底破解多类型文件处理难题。
一、技术内核:大模型构建全栈解析能力
达观智能文档抽取中枢的核心竞争力源于深度学习与行业知识的深度融合,其技术壁垒被 CEO 陈运文概括为 “中国最强的书面文字自动化处理技术、高度产品化的行业适配能力、前沿的产学协同研发体系” 三大支柱,形成 “感知 – 处理 – 应用” 三层技术架构: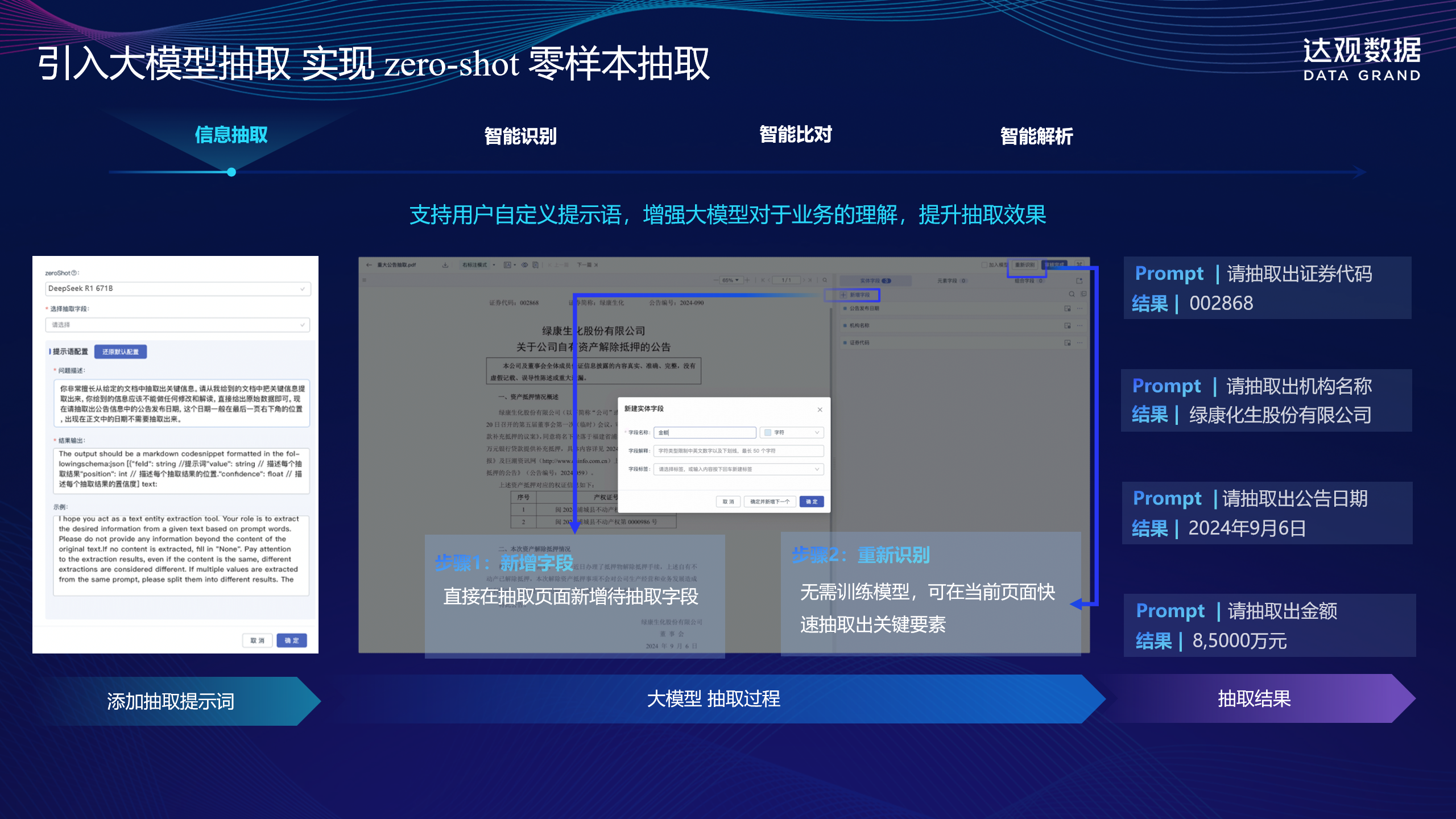
(一)多模态感知层:全格式精准识别的技术突破
通过自研 OCR 与计算机视觉技术深度融合,实现对 PDF、Word、JPG、手写票据等全格式文件的精准识别。这一能力源于达观研发多年的智能图像识别平台,包含图像矫正、文字检测、文字识别三大核心模型。针对物流单据褶皱、医疗票据字迹模糊等常见问题,系统可自动完成去噪、纠偏、增强预处理,其中中英文字符识别率稳定在 99% 以上,即便是手写体数字识别准确率也能达到 98.5%。在南航共享智能结构化系统项目中,该层技术成功处理了机务维修记录、财务报销凭证等 12 类复杂影像数据,为多业务场景提供了基础识别支撑。
(二)智能处理层:700 亿参数大模型的行业赋能
搭载达观自主研发的 “曹植” 700 亿参数大模型与 80 + 行业专用文本解析模型,这一参数规模使其能够存储更复杂的行业知识,生成自然语言时精度显著提升。该层具备三大核心能力:一是长文本解析,1 分钟可完成 100 页招股书的关键信息提取,对 5 万字以上合同的条款识别覆盖率达 99.2%;二是跨文档比对,能 100% 召回不同版本协议的差异点,如金融合同中的利率调整条款变更;三是合规校验,内置的 200 万条法律法规库与业务规则引擎,可自动识别医疗单据中的超范围用药、工程合同中的资质不符等问题。在某供应链文档管理项目中,该层技术实现了供应商资质文件的自动核验,将审核周期从 3 天压缩至 4 小时。

(三)无缝应用层:从数据到业务的闭环衔接
支持与 ERP、CRM、OA 等 200 + 主流系统通过 API、中间库等方式直连,结构化数据可自动同步至业务中台,无需人工二次录入。同时提供可视化标注与模型训练工具,用户通过简单拖拽即可完成新文档类型的模板配置,模型迭代周期从传统的 1 个月缩短至3 天。例如某制造企业新增海外供应商发票类型后,仅用 2 小时完成标注训练,系统次日便实现 97% 的字段识别准确率。该层还具备完善的权限管理体系,可按部门、角色设置文档访问权限,满足金融、军工等行业的合规要求。
二、行业实证:从效率瓶颈到价值释放
(一)金融行业:投研与风控的双效突破
某头部券商投研部门曾深陷新债分析困境:人工解析 10 万字募集说明书需 3 小时,百份文件耗时超 12 天,错误率高达 18%。引入达观平台后,RPA 机器人自动爬取交易所公告,调用 IDP 引擎 3 分钟完成单份解析,百份文件处理压缩至 5 小时,效率提升 28.8 倍。更关键的是,“曹植” 大模型精准识别偿债能力指标、担保条款等 23 类风险点,解析错误率降至 0.8%,数据直连估值模型后,新债定价决策周期从 3 天缩短至 4 小时。
在银行业务场景中,某资产规模 7500 亿元的城商行,8 名员工每月仅能完成 3000 户账户年检,PDF 资料比对错误率 12%。达观机器人实现夜间自动化作业:凌晨登录核心系统下载余额表、印鉴表,跨表比对生成台账,次日仅需 2 名员工核查异常数据。季度自检从 3 天压缩至 4 小时,年省人工成本 60 万元,错误率趋近于零,不良资产回收率提高 15 个百分点。该银行风控负责人表示:“平台相当于为我们配备了 24 小时不休息的‘审核专员’,风险识别响应速度提升了 10 倍。”
(二)物流与制造业:供应链的数字化提速
某航空公司在引入达观 AI 技术前,财务部门每月需处理 2 万余份差旅报销单、机务维修凭证,50 人团队需耗时 15 天完成审核。通过共享智能结构化系统,达观平台自动识别行程单金额、维修部件型号等关键字段,与其 ERP 系统自动对账,异常单据实时预警。目前该系统日均处理单据 1200 份,审核效率提升 6 倍,错误率从 8% 降至 0.3%,年节约人工成本超 300 万元。
某大型制造企业则通过平台解决财务核算痛点:此前人工录入供应商发票与成本报表时,金额不匹配、发票号错误等问题导致 5% 的数据误差,每月需额外投入 4 人进行复核。达观系统提取数据后自动比对校验,异常信息实时推送至财务人员,误差率降至 0.1% 以下,月度账务处理从两周压缩至 2 天。该企业财务总监透露:“平台上线半年来,累计减少账务调整 120 余次,财务部门得以将更多精力投入成本分析。”
(三)医疗与政务:民生服务的效率革命
某三甲医院每月处理海量医保报销单据,电子与扫描件混杂,人工录入需 10 天且错误率 3%,导致患者结算平均等待时间达 4.5 小时。达观平台自动识别患者信息、医疗项目、药品规格等 18 类核心数据,对接 HIS 与医保系统完成核验,处理时间缩至 2 天,错误率降至 0.05% 以下,患者结算等待时间缩短至 1 小时以内,满意度从 82% 提升至 96%。
在政务领域,某互联网银行审计部门借助达观平台整合异构数据,实现图片、文档的 95% 以上解析率,毫秒级检索速度让审计人员可快速定位关键证据。平台上线后,该部门完成年度审计的时间从 3 个月压缩至 1 个月,风险识别效率提升 3 倍,成功发现 3 起潜在违规操作。此外,某省级政务服务中心通过该平台处理企业注册材料,将审批时限从 5 个工作日缩短至 1 个工作日,材料错误退回率从 27% 降至 3%。
(四)科技行业:供应链管理的智能化升级
某大型科技企业事业部曾面临供应商资质文件管理难题:2000 余家供应商的营业执照、专利证书等文件分散存储,人工核查有效期需投入 6 人 / 月,且易遗漏过期证件。引入达观平台后,系统自动爬取供应商系统文件,提取有效期、资质等级等关键信息,提前 30 天推送到期预警。目前仅需 1 人 / 周即可完成全部核查工作,证件过期漏检率从 15% 降至 0,供应商合作风险显著降低。
三、核心优势:重构文档处理价值链条
达观智能抽取中枢的差异化价值体现在四个维度,这也是其服务千余家企业、涵盖世界五百强客户的核心原因:
1. 全场景适配能力:覆盖合同、财报、化验单、维修记录等 80 + 文档类型,支持 10 余种比对场景与 30 + 审核类型,适配金融、制造、医疗、政务等 10 余个行业。针对特殊场景可提供定制化方案,如为军工企业开发涉密文档处理模块,为跨境电商打造多语言票据识别系统。
2. 极致性价比表现:百份 PDF 解析效率提升 20 倍以上,人工操作减少 80%,头部客户年省成本超 60 万元,投资回报周期平均不足 6 个月。以某中型物流企业为例,平台采购成本 50 万元,上线后年节约人工成本 48 万元,5 个月即收回投资。
3. 安全可扩展特性:操作轨迹全程留痕,通过等保三级认证,具备数据加密存储、传输加密等多重安全机制。支持私有云、公有云、混合云等跨平台部署,与麒麟操作系统、飞腾芯片等国产软硬件兼容,可满足不同规模企业的部署需求。
4. 技术迭代保障:依托与复旦大学、中国计算机学会的产学合作体系,持续输出技术成果,在 KDD CUP 等国际算法竞赛中多次荣获世界冠军。目前已拥有 20 余项国家发明专利,技术更新频率保持每月 1 次,确保平台能力始终领先。

四、未来展望:大模型赋能知识自动化
随着生成式 AI 技术演进,达观数据正推动文档处理从 “自动化解析” 向 “知识化创造” 升级。平台已实现三大 AIGC 核心功能:一是合同自动起草,基于行业模板与历史数据,输入关键条款后 10 分钟即可生成合规合同初稿,如劳动合同、采购协议等;二是审计报告智能生成,自动整合解析数据与业务指标,生成带数据可视化图表的审计报告;三是智能问答助手,员工通过自然语言提问即可获取文档关键信息,如 “2024 年 Q3 供应商逾期付款金额” 等。
这些功能与 7×24 小时运行的智能文本机器人结合,已构建从数据提取到内容创作的全流程自动化体系。在某咨询公司项目中,该体系将行业研究报告的撰写周期从 2 周缩短至 3 天,其中数据采集与初步分析环节效率提升 15 倍。
对于深陷文档处理困境的企业而言,达观智能抽取中枢不仅是效率工具,更是激活非结构化数据价值的 “数字引擎”。截至 2025 年,平台已服务 300 + 企业客户,涵盖多个世界五百强企业,累计处理文档超 10 亿份。在全球知识管理市场快速增长的浪潮中,达观数据正以技术创新引领行业进入智能文档处理的新时代。





