
在大模型技术快速演进的今天,文档智能处理正面临一个根本性挑战:如何在海量文档中实现真正意义上的深度理解与高效处理?达观数据IDP(智能文档处理)与DeepSeek-OCR的深度集成,展示一个全新的技术路径——通过视觉压缩与语义理解的深度融合,重构智能文档处理的底层架构。
智能文档处理架构的变革:从线性流程到认知图谱
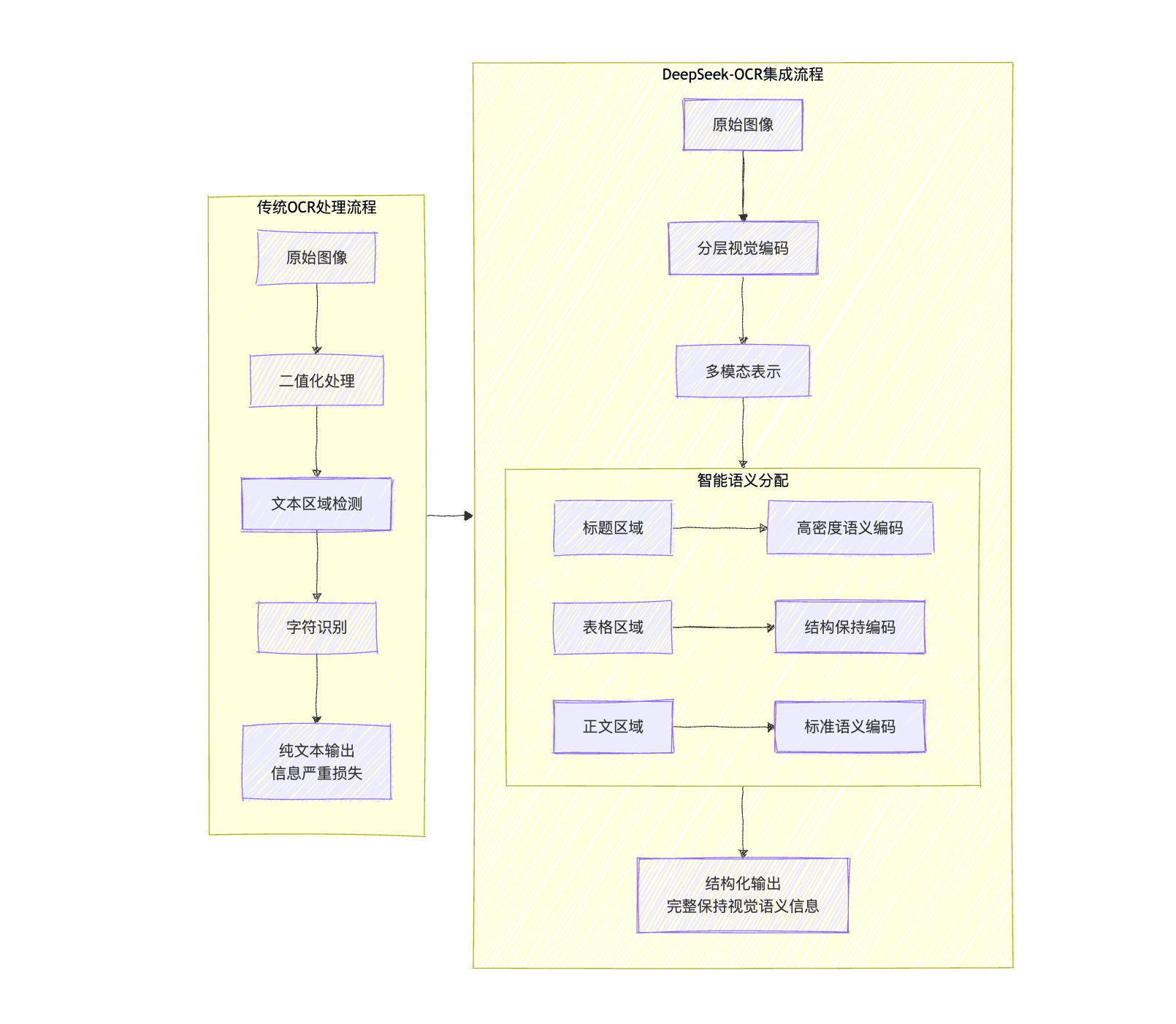
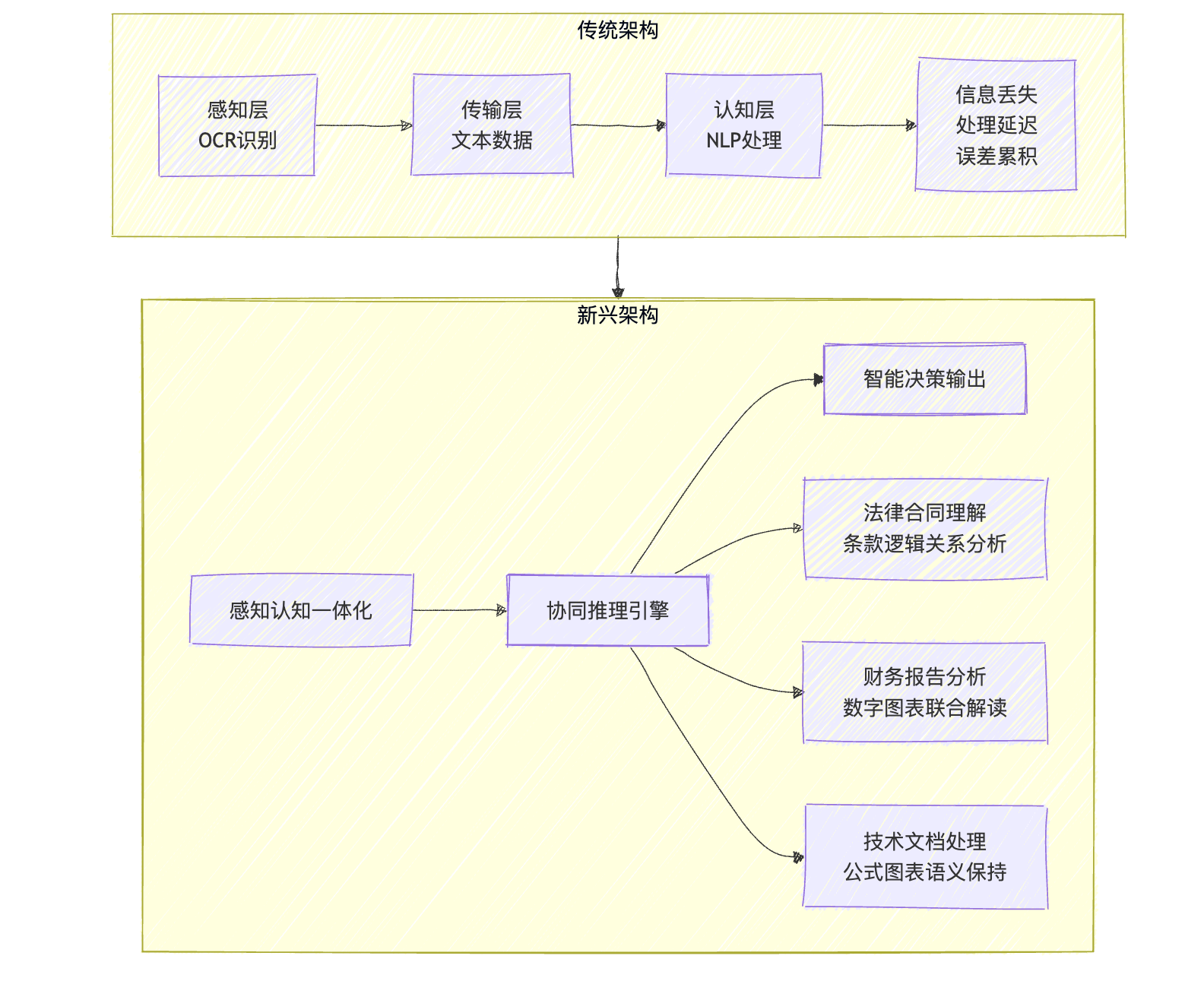
传统OCR架构的局限性
传统OCR处理流程遵循严格的序列化处理范式,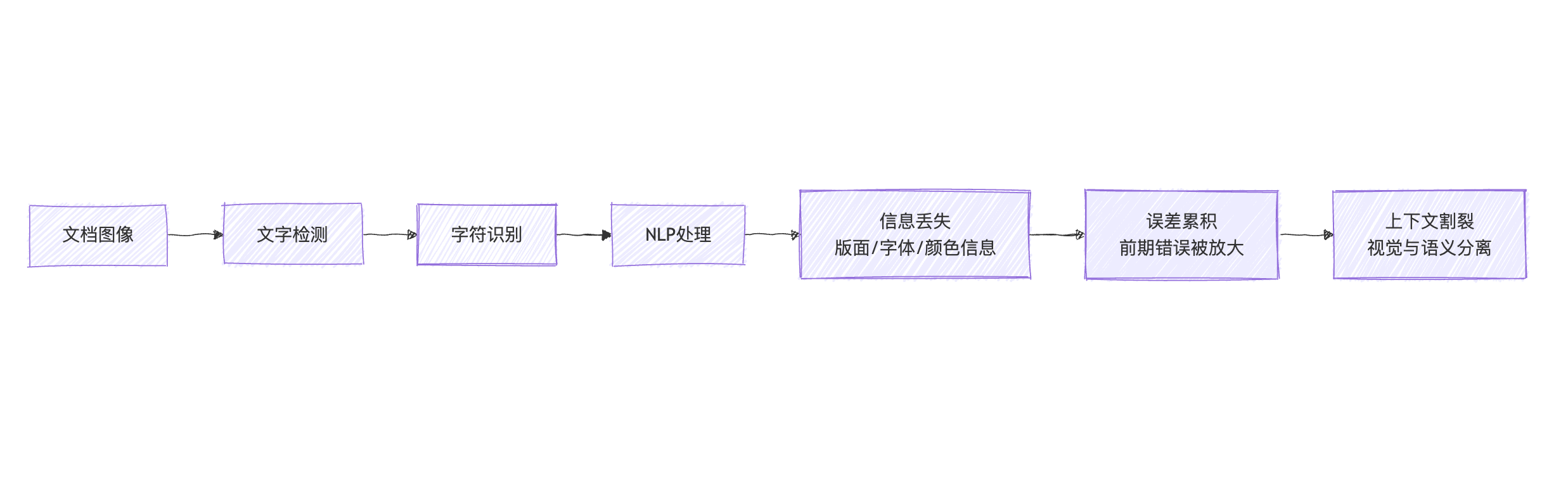
这种”感知-认知”的割裂架构,在三个维度暴露出根本性缺陷:
- 模态断层:视觉信息与语义表征的解耦导致上下文理解的断裂;
- 效率瓶颈:层级化处理的线性约束造成计算资源的指数级损耗;
- 认知盲区:孤立的文本分析无法捕捉文档的视觉语义共生关系;
这种技术路径在面对长文档、复杂排版及多模态信息时,暴露出认知能力的结构性缺陷,恰似用平面图纸丈量立体建筑的困局。
DeepSeek-OCR的架构创新设计
突破性范式源自对视觉与语义本质关系的重新诠释。DeepSeek-OCR架构通过跨模态对齐与联合表征学习,构建出三维认知空间:
- 视觉压缩引擎:采用分层注意力机制对图像特征进行语义蒸馏,实现像素级到概念级的语义升维
- 语义解码网络:基于Transformer架构的上下文感知模块,构建文档级语义图谱
- 动态交互层:通过可微分的视觉-语言对齐模块,在特征空间实现模态信息的量子纠缠
这种架构的颠覆性在于,将文档处理从”像素到字符”的线性映射,升维至”视觉模式到认知图谱”的拓扑建模。如同在神经科学中重构视觉皮层与语言中枢的协同机制,使机器具备了”边阅读边理解”的认知能力。
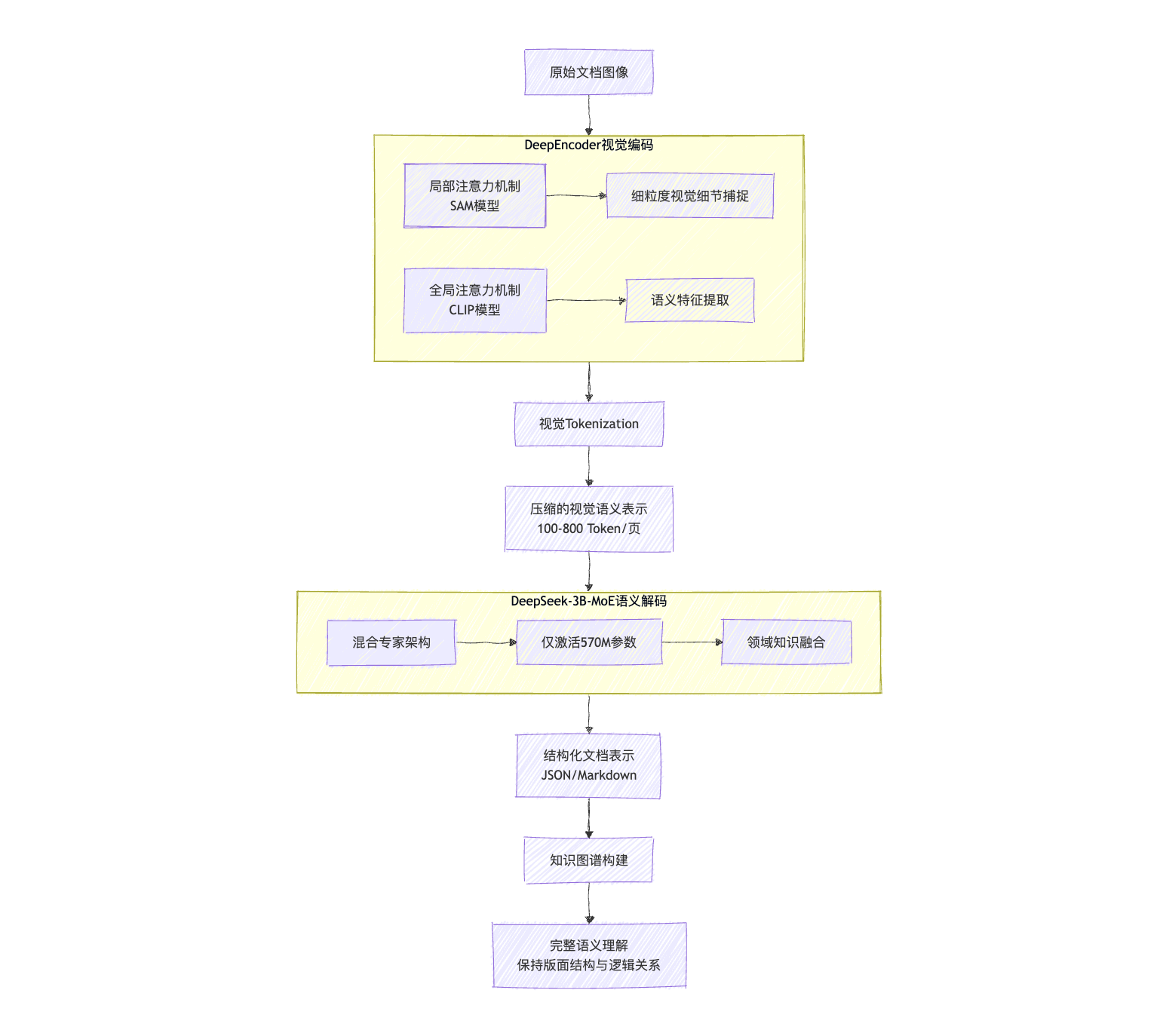
达观IDP与DeepSeek-OCR集成解析:多模态理解与适配
多模态文档理解引擎的重构
达观IDP通过深度集成,完成了从”文本中心主义”到”认知生态”的范式迁移。系统架构呈现出三重进化特征:
- 异构数据融合层:构建跨模态特征空间,实现文本、表格、图表、图像的语义对齐
- 认知图谱构建器:基于知识图谱的动态推理引擎,支持文档级语义推理与因果建模
- 自适应认知界面:通过元学习机制,实现领域知识的快速注入与迁移
这种架构的突破性在于,文档不再是需要肢解分析的静态对象,而是成为可交互的认知场域。系统如同拥有”文档感知智能”,能够自主构建语义网络并进行推理决策。
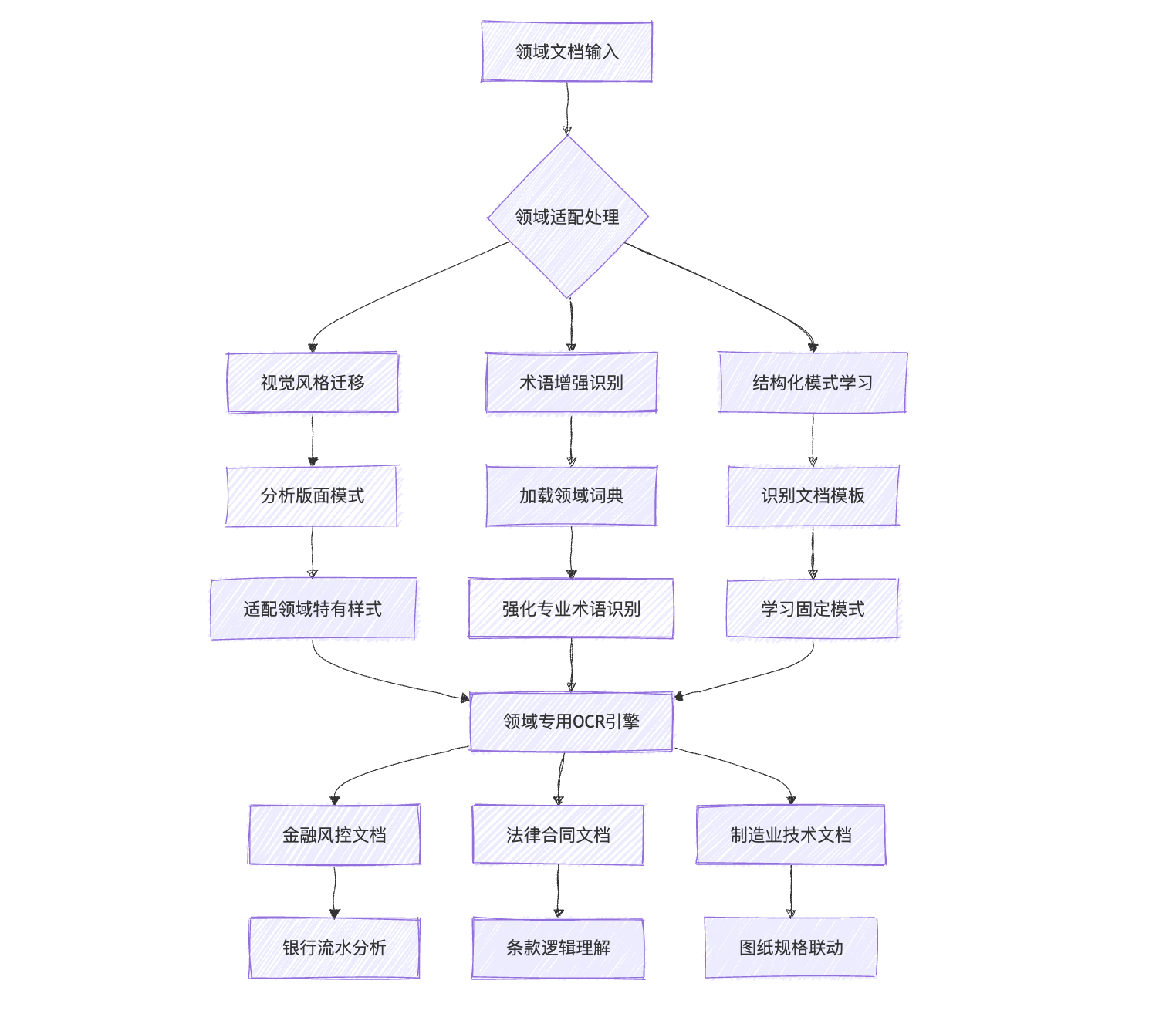
领域自适应微调框架
达观基于DeepSeek-OCR开发的多粒度领域适配框架处理流程:
行业趋势展望:技术融合的发展方向
感知-认知一体化
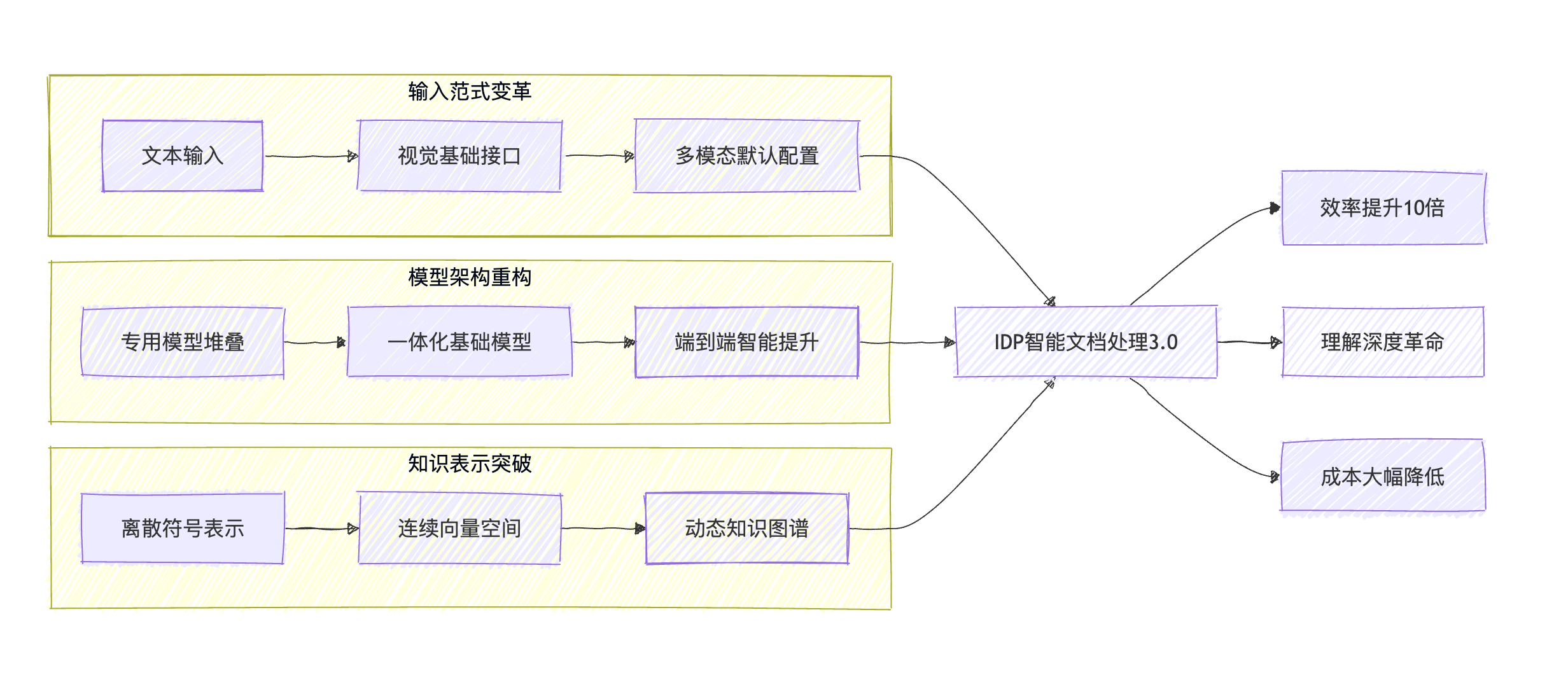
DeepSeek-OCR与达观IDP的集成代表了感知与认知融合的技术趋势演进:
技术生态的演进趋势
当前集成模式指向的三个重要技术趋势演进路径:
- 模态融合的拓扑革命:从特征级融合走向认知图谱级的语义编织
- 计算范式的量子跃迁:基于注意力机制的动态计算取代静态流程
- 知识表达的语义升维:从符号主义到连接主义的融合统一
效能突破:从量变到质变的技术飞跃
处理效能显著提升
通过上述技术架构的重构,达观IDP在关键性能指标上实现了突破性进展:
- 时空维度的突破:
- 长文档处理:100页技术文档从2小时压缩至15分钟,效率提升87.5%
- 吞吐量革命:单GPU日处理能力从2万页跃升至20万页,实现数量级飞跃
- 认知深度的突破:
- 全局语义理解:通过视觉上下文压缩实现跨页语义连续体构建
- 多模态推理:文本、表格、图表的语义关联推理准确率提升42%
- 细粒度认知:关键信息抽取F1值达98.7%,实现法律条款级的精准解析
结语
达观IDP与DeepSeek-OCR的深度集成,并非两项技术的简单叠加,而是对智能文档处理模式的重要优化。这种优化的核心在于:
实现了从 “先识别后理解” 到 “边感知边认知”的模式转变,让AI能够像人类专家那样,在“浏览”文档的过程中就完成深度的理解和分析。
对于行业而言,这标志着文档智能3.0时代的开启——一个文档不再需要被“拆解”才能被理解的时代,一个视觉与语义自然融合的时代,一个处理效率与理解深度同步跃升的时代。
在这个新时代中,达观数据通过前瞻性的技术布局,正在为各行业的数字化转型提供全新的智能化基础设施。而DeepSeek-OCR所代表的视觉压缩技术,很可能成为未来多模态AI系统的标准配置,为海量信息的处理与理解提供新方式。




