

各个行业都存在有大量的数据分析工作,这些数据可能来源于各个渠道,格式多样,质量参差不齐。本文将带领大家通过一个简单的例子,初步了解使用达观数据NLP平台进行NLP模型建模的全过程。
以新闻分类为例。首先,建立一项“新闻分类”的NLP任务:构建一个新闻分类模型,通过分析数据,构建标签体系,标注训练,使之可以对新闻稿件进行分类预测,预测新闻是属于标签体系中哪个标签类别。我们按照大体的建模流程进行任务分解:
构建标签体系→数据标注→模型训练→模型评估与调优→模型上线
1.构建标签体系
对样本数据进行数据分析,并结合业务专家经验知识,构建一个适合该任务场景的标签体系。
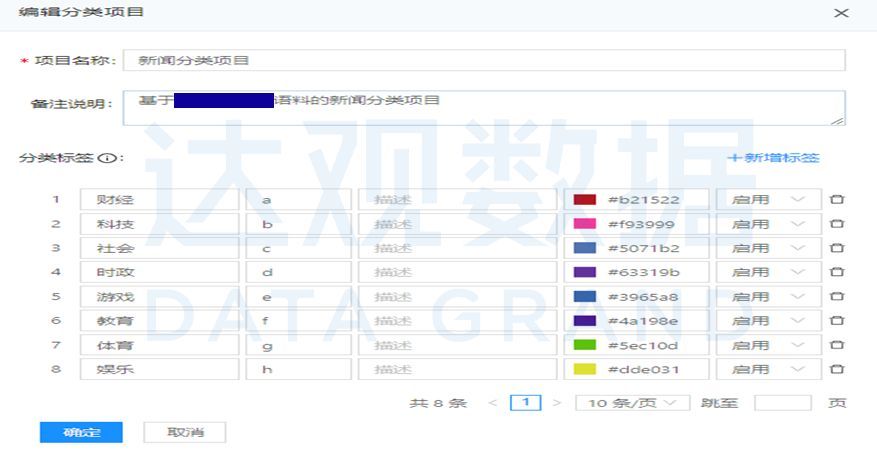
通过达观数据NLP平台构建分类标签
2.数据标注
有了标签体系,下一步就是对样本数据进行数据标注。简单来说,数据标注的过程就是通过人工贴标签的方式,为模型提供可学习的样本数据,最终使模型可以自主识别数据。例如:样本数据是“为什么我的业务C还是无法办理?”,可以将其标注为“业务C”。

通过达观数据NLP平台轻松进行数据标注
3.模型训练
模型训练是将已标注的数据输入给模型,让模型去学习其中的数据规律。通常我们会按照一定的比例,将数据集划分为训练集、验证集、测试集,
✓ 训练集(training set)用于运行学习算法,训练模型。
✓ 验证集(development set)用于调整超参数、选择特征等,以选择合适模型。
✓ 测试集(test set)只用于评估已选择模型的性能,但不会据此改变学习算法或参数。
应用达观NLP平台可以进行一键完成模型训练。

一键完成模型训练
4.模型评估与调优
模型评估
当模型学习了训练集数据,完成训练后,我们需要对其进行性能评估,看看模型对新数据(测试集)的预测能力如何。
常用评估指标包括:准确率、精确率、召回率、F1值等。
准确率(Accuracy):就是所有的预测正确(正类负类)的占总的比重。
精确率(Precision):查准率,即正确预测为正的占全部预测为正的比例。
召回率(Recall):查全率,即正确预测为正的占全部实际为正的比例。
F1值(H-mean值):F1值为算数平均数除以几何平均数,且越大越好。

模型评估效果展示
模型调优
当模型评估完成后,需要对误差样本进行误差原因分析,找到模型在某些样本数据上分类表现不好的原因,以便做针对性调整。
模型调优是一个漫长而复杂的过程,包含模型的重新训练、新想法的试验、效果评估和指标对比等。
5.模型上线
当模型调优后,达到一个比较好的评估效果,即可进行模型上线,使之投入实际生产中,帮忙我们更智能便捷地完成工作。
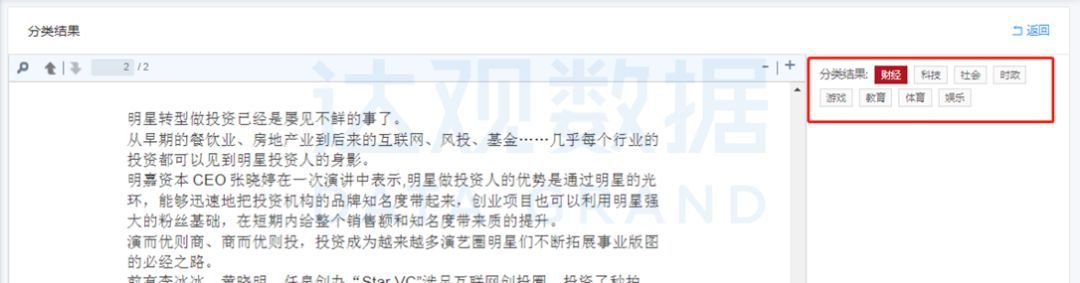
自动对新的语料进行分类预测
以上是一个常规建模流程,使用者不需要会写代码,应用达观NLP平台即可快速、便捷地享受构建NLP模型的一条龙服务。
达观数据NLP平台,不仅包含传统NLP领域的中文分词、词性分析、实体抽取等基础功能,同时针对不同行业的业务需要,提供基于篇章级、段落级的语义分析应用。充分结合当前机器学习领域、自然语言生成领域的算法和模型,提供基于业务知识的探索与深度应用,满足行业用户对场景化的多元需求。
达观数据自然语言处理NLP平台能够满足行业客户多元化的文本挖掘分析、事件分析、舆情分析等多场景诉求,支持贴合行业的文本内容分析、观点提取、敏感信息过滤、评论分析、事件发展趋势分析等高端应用。




