

大名鼎鼎的深度学习之父Yann LeCun曾评价GAN是“20年来机器学习领域最酷的想法”。的确,GAN向世人展示了从无到有、无中生有的神奇过程,并且GAN已经在工业界有着广泛的应用,是一项令人非常激动的AI技术。今天我将和大家一起去了解GAN及其内部工作原理,洞开GAN的大门。
本文尽量用浅显易懂的语言来进行表述,少用繁琐的数学公式,并对几个典型的GAN模型进行讲解。
一、GAN(GenerativeAdversarial Networks)
GAN全名叫Generative Adversarial Networks,即生成对抗网络,是一种典型的无监督学习方法。在GAN出现之前,一般是用AE(AutoEncoder)的方法来做图像生成的,但是得到的图像比较模糊,效果始终都不理想。直到2014年,Goodfellow大神在NIPS2014会议上首次提出了GAN,使得GAN第一次进入了人们的眼帘并大放异彩,到目前为止GAN的变种已经超过400种,并且CVPR2018收录的论文中有三分之一的主题和GAN有关,可见GAN仍然是当今一大热门研究方向。
GAN的应用场景非常广泛,主要有以下几个方面:
2.图像翻译。从真实场景的图像到漫画风格的图像、风景画与油画间的风格互换等等。
3.图像修复。比如图像去噪、去除图像中的马赛克(嘿嘿…)。
4.图像超分辨率重建。卫星、遥感以及医学图像中用的比较多,大大提升后续的处理精度。
(一) GAN原理简述
GAN的原理表现为对抗哲学,举个例子:警察和小偷的故事,二者满足两个对抗条件:
1.小偷不停的更新偷盗技术以避免被抓。
2.警察不停的发现新的方法与工具来抓小偷。
小偷想要不被抓就要去学习国外的先进偷盗技术,而警察想要抓到小偷就要尽可能的去掌握小偷的偷盗习性。两者在博弈的过程中不断的总结经验、吸取教训,从而都得到稳步的提升,这就是对抗哲学的精髓所在。要注意这个过程一定是一个交替的过程,也就是说两者是交替提升的。想象一下,如果一开始警察就很强大,把所有小偷全部抓光了,那么在没有了小偷之后警察也不会再去学习新的知识了,侦查能力就得不到提升。反之亦然,如果小偷刚开始就很强大,警察根本抓不到小偷,那么小偷也没有动力学习新的偷盗技术了,小偷的偷盗能力也得不到提升,这就好比在训练神经网络时出现了梯度消失一样。所以一定是一个动态博弈的过程,这也是GAN最显著的特性之一。
在讲完了警察与小偷的故事之后,我们引入今天的主人公——GAN。
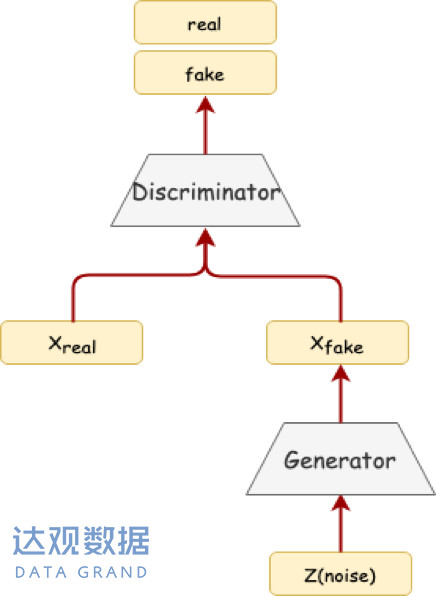
(二) 模型架构图
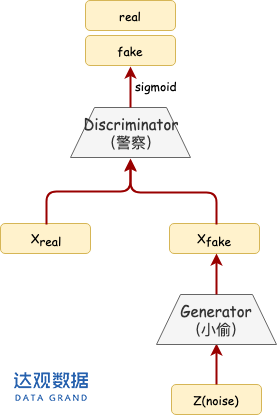
从上图能够看出GAN的整个网络架构是非常简单明了的,GAN由一个生成器(Generator)和一个判别器(Discriminator)组成, 两者的结构都是多层感知机(MLP),具体有多少层、每层多少个神经元可以根据实际情况自行设计,比较灵活。在这里,生成器充当着“小偷”的角色,判别器就扮演“警察”的角色。为了方便讲解,后面把生成器简称为G,判别器简称为D。
G:接收一个随机噪声向量z(比如z服从高斯分布),G的目标就是通过这个噪声来生成一个像真实样本的假样本![]() 。
。
D:判别一个样本是真实样本还是G自己造的假样本。它接收一个样本数据作为输入,所以这个样本可以是G生成的假样本![]() 也可以是真实样本
也可以是真实样本![]() 。它输出一个标量,标量的数值代表了输入样本到底是真实样本还是G生成的假样本的概率。如果接近1,则代表是真实样本,接近于0则代表是生成器生成的假样本,所以此时D最后一层的激活函数一定为sigmoid。
。它输出一个标量,标量的数值代表了输入样本到底是真实样本还是G生成的假样本的概率。如果接近1,则代表是真实样本,接近于0则代表是生成器生成的假样本,所以此时D最后一层的激活函数一定为sigmoid。
网络的最终目标是在D很强大的同时,G生成的假样本送给D后其输出值变为0.5,说明G已经完全骗过了D,即D已经区分不出来输入的样本到底是![]() 还是
还是![]() ,从而得到一个生成效果很好的G。
,从而得到一个生成效果很好的G。
损失函数的设计:
![]()
从上面的式子可以看出,损失函数是两个分布各自期望的和,其中![]() 是真实数据的概率分布,
是真实数据的概率分布,
![]() 是生成器所生成的假样本的概率分布。对于D,它的目的是让
是生成器所生成的假样本的概率分布。对于D,它的目的是让![]() 中的样本的输出结果尽可能的大,即
中的样本的输出结果尽可能的大,即![]() 变大,而让
变大,而让![]() 生成的样本x的输出结果尽可能的小,即
生成的样本x的输出结果尽可能的小,即![]()
变大,导致![]() 变大。对于G,它的目的是用噪声z来生成一个假样本x并让D给出一个较大的值,即让
变大。对于G,它的目的是用噪声z来生成一个假样本x并让D给出一个较大的值,即让![]() 变小,导致
变小,导致![]() 变小。综上,我们得出:
变小。综上,我们得出: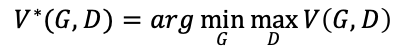
(三) GAN的训练流程
假设batch_size=m,则在每一个epoch中:
先训练判别器k(比如3)次:
1. 从噪声分布z(比如高斯分布)中随机采样出m个噪声向量:![]() 。
。
2. 从真实样本x中随机采样出m个样本:![]() 。
。
3. 用梯度下降法使损失函数![]() : 与1之间的二分类交叉熵减小(因为最后判别器最后一层的激活函数为sigmoid,所以要与0或者1做二分类交叉熵,这也是为什么损失函数要取log的原因)。
: 与1之间的二分类交叉熵减小(因为最后判别器最后一层的激活函数为sigmoid,所以要与0或者1做二分类交叉熵,这也是为什么损失函数要取log的原因)。
4. 用梯度下降法使损失函数![]() :与0之间的二分类交叉熵减小。
:与0之间的二分类交叉熵减小。
5. 所以判别器的总损失函数![]() 即让d_loss越小越好。注意在训练判别器的时候生成器中的所有参数要固定住,即不参加训练。
即让d_loss越小越好。注意在训练判别器的时候生成器中的所有参数要固定住,即不参加训练。
再训练生成器1次:
1. 从噪声分布中随机采样出m个噪声向量:![]() 。
。
2. 用梯度下降法使损失函数:![]() 与1之间的二分类交叉熵减小。
与1之间的二分类交叉熵减小。
3. 所以生成器的损失函数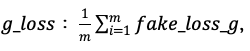 即让g_loss越小越好。注意在训生成器的时候判别器中的所有参数要固定住,即不参加训练。
即让g_loss越小越好。注意在训生成器的时候判别器中的所有参数要固定住,即不参加训练。
直到所有epoch执行完毕,训练结束。
从训练方法中可以看出,生成器和判别器是交替进行训练的,呈现出一种动态博弈的思想,非常有意思。不过在训练的时候还有一些注意事项:
1.在训练G的时候D中的参数不参加训练,即不需要梯度反传。同理,训练D的时候G中的参数不参加训练。
2.为了让D保持在一个相对较高的评判水平,从而更好的训练G。在每一个epoch内,先对D进行k(比如k=3)次训练,然后训练G一次,加快网络的收敛速度。
3.在原始论文中,作者在训练G的时候给出的公式是![]() ,然而这个公式有一些隐患,因为在训练的初始阶段,G生成的样本和真实样本间的差异一般会很大,此时D能很轻松的分辨两种样本,导致
,然而这个公式有一些隐患,因为在训练的初始阶段,G生成的样本和真实样本间的差异一般会很大,此时D能很轻松的分辨两种样本,导致![]() 一直趋近于0,此时梯度消失,G也就得不到训练,所以这里的策略是
一直趋近于0,此时梯度消失,G也就得不到训练,所以这里的策略是![]() ,上面训练过程的阐述中已经对该处的损失函数做了更正。
,上面训练过程的阐述中已经对该处的损失函数做了更正。
(四) 损失函数相关数学推导
我们先将G中的参数固定住,此时的噪声向量通过G后所生成的样本是一一对应的,则有如下映射:
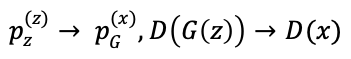
由此将由两个数学期望的和组成的![]() 展开:
展开:
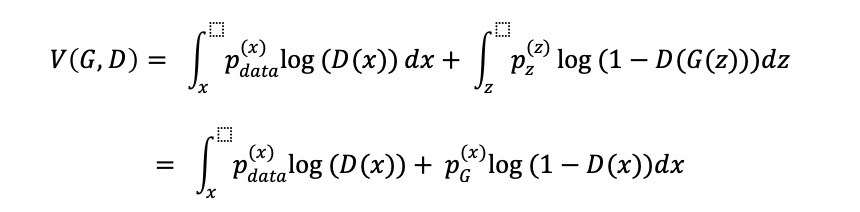
由于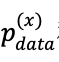 和
和![]() 是固定的常量,另它们等于a,b。令
是固定的常量,另它们等于a,b。令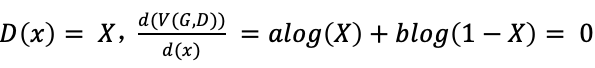 ,得到
,得到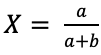 ,由于是唯一极值点,则必为最值点,也能够证明在
,由于是唯一极值点,则必为最值点,也能够证明在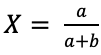 时,其二阶导小于0,那么该最值点为全局最大值点。
时,其二阶导小于0,那么该最值点为全局最大值点。
所以,当G固定住的时候,不断的训练D中的参数,理论上可以让D达到最大值:
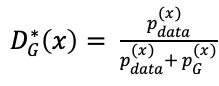 。
。
此时将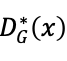 带入进
带入进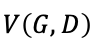 中,得到:
中,得到:
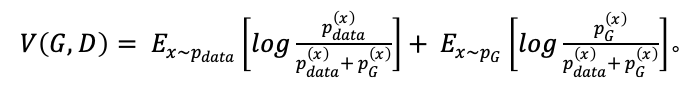
对于两个概率分布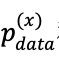 和
和![]() ,它们之间的KL散度就是数据的原始分布与近似分布的概率的对数差的期望值,其公式为:
,它们之间的KL散度就是数据的原始分布与近似分布的概率的对数差的期望值,其公式为:
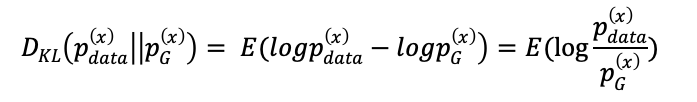
所以此时得到:
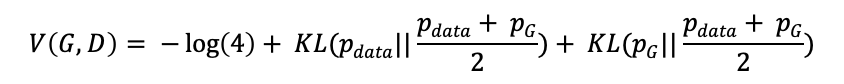
再将两个KL散度的和合并成JS散度,得到:
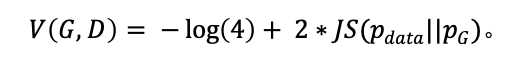
从上式可以看出,如果G要让![]() 最小,必须要让
最小,必须要让![]() 和
和![]() 间的JS散度最小,而JS散度的最小值为0,此时两个分布完全重合,即
间的JS散度最小,而JS散度的最小值为0,此时两个分布完全重合,即 理论上的最小值为
理论上的最小值为![]() ,此时存在唯一解:
,此时存在唯一解:
![]()
使得损失函数达到全局最小值,即生成器完美的实现了生成真实数据的过程,完全掌握了真实数据的概率分布。
(五) 总结
1.GAN的开山之作。
2.GAN的本质其实是利用神经网络强大的非线性拟合能力来学习从一个任意先验的噪声分布到真实数据分布的非线性映射,从而让生成器具有能够产生逼真样本的能力。
3.早期GAN的训练非常不稳定导致训练难度大,还容易出现梯度爆炸、mode collapse等问题。mode collapse的意思就是生成的样本大量集中于部分真实样本,那么就是很严重的mode collapse。以生成动漫头像图片为例,从下图中能够明显的看出,红框标记的图像重复出现了很多次,即存在一定的mode collapse。

二、DCGAN(Deep Convolutional Generative Adversarial Networks)
在GAN被提出之后,GAN的热度曲线呈指数式增长,期间在原始GAN的结构基础上进行改进的GAN变种层出不穷,其中最具代表性的当属DCGAN了,我们来看看它对原始GAN有什么创新:
1.将两个多层感知机替换为两个卷积神经网络。即将CNN融合进GAN中,极大的加速了GAN在图像领域中应用的步伐,此后许多新提出的GAN都一直在沿用DCGAN的网络架构。 2.创新性的将反卷积(也叫转置卷积)操作应用于生成器中。 3.通过大量实验,总结出一套构建网络时很有用的trick。
(一) 反卷积
常见的上采样方式有三种:双线性插值,反卷积(也叫转置卷积)和反池化。鉴于篇幅所限,除反卷积以外的两种上采样方法就不在这里介绍了。
常规的卷积操作一般会导致图像的尺寸越来越小,同时图像深度在逐渐增加。而反卷积则使图像尺寸越来越大,而深度在逐渐减小。所以反卷积是卷积操作的逆运算,也就是说反卷积的正向传播是卷积的反向传播,其反向传播是卷积的正向传播,本文力求用形象的过程来展现反卷积的工作原理(注:下文所阐述的反卷积工作方式为tensorflow机器学习框架反卷积的底层实现方法,其他框架的底层实现方法可能略有不同)。
若输入为3*3大小的单通道图像:

考虑卷积核大小kernel_size=3*3,stride=2,padding=same的反卷积操作,且卷积核为:

如果stride=2,那么就在输入图像的每行和每列之间插入(stride-1)行(列)的零元素,另外还需要在补零后的矩阵的左边和上边添加额外的(stride-1)行(列)的零元素:
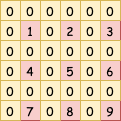
如果卷积核的大小kernel_size=3,且padding=same的情况下,我们知道在正常的卷积模式下是要上、下、左、右各添加(kernel_size-1)/2个行(列)元素,他们的初始值都为0,以此来保证输出图像与输入图像的大小是相同的,所以这里也采取相同的padding操作。这里简单说明一下:如果kernel_size=4,那么(kernel_size-1)/2=1.5,无法整除,那么此时左方和上方添加一行(列)零元素,右方和下方添加两行(列)零元素,总之要保证添加的总行(列)数要和kernel_size-1是相等的,这也是tensorflow机器学习框架在卷积操作中padding=same时的填补方法。所以现在输入图像变成了这样:
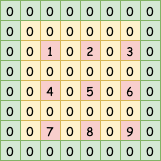
此时输入图像的尺寸由3*3变成了8*8,我们用kernel_size=3,stride=1,padding=valid的方式对这张图进行常规的卷积操作,则输出尺寸变为:H=(8+0-3)/1+1=6,W=(8+0-3)/1+1=6。注意这步操作中的kernel_size是和反卷积核的kernel_size是保持一致的,stride固定为1,而且不进行padding操作,因为前面已经padding过了,得到:
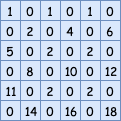
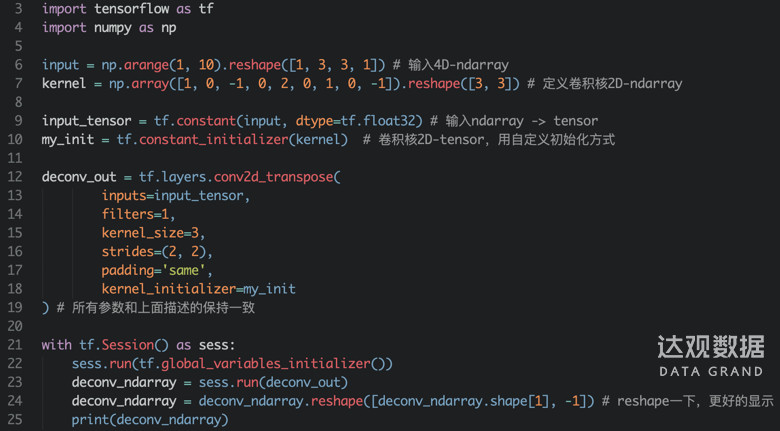
我们用tensorflow做个小实验,来验证上面算法的正确性。
输出:
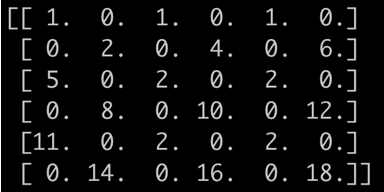
输出结果和我们自己推导的完全一致!可见,反卷积也仅仅是卷积操作而已,与正常卷积使用相同大小的卷积核,只不过反卷积需要通过特定的规则对输入tensor通过padding 0元素的方式处理一下。这样我们最终得到的输出图像尺寸要比原图像大,即实现了上采样的功能。怎么样,是不是非常简单。
反卷积的应用领域非常广泛,不仅仅在GAN中,还在图像分割以及feature map的可视化领域有着广泛的应用。好了,简单讲完反卷积后,让我们回到DCGAN。
(二) 网络实现上的一些tirck
1. 在生成器与判别器中,将所有池化层替换为步长大于1的卷积操作,即抛弃所有池化层,目的是让网络去学习属于它自己的上(下)采样方式。想了一下,确实是非常有效的trick,因为在图像分割领域中,maxpooling操作会破会图像的边缘与细节,导致分割结果很粗糙,所以一般都通过别的办法来替代maxpooling,以保证分割结果的细节完好。
2. 移除全局平均池化层,全局平均池化在图像分类网络中有着举足轻重的地位,作者在做实验的过程中发现在判别器中用全局平均池化再接全连接层虽然能够增加模型的稳定性,但同时严重减缓了模型的收敛速度,所以决定移除。
3. 除了生成器的最后一层和判别器的输入层,其余层都做batch normalization操作。是一个非常有助于网络快速收敛的trick。作者发现如果全部层都用batch normalization,容易发生mode collapse现象,并使得模型变得不稳定。
4. 生成器最后一层的激活函数采用tanh,其余层为relu激活函数。而判别器中则全部采用leaky relu激活函数。
(三) DCGAN中生成器的网络结构
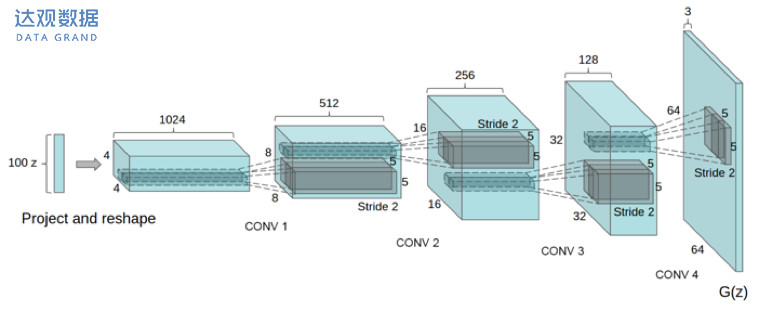
网络的整体架构和原始GAN是差不多的,不同的仅仅是生成器和判别器的内部结构,由MLP换成了CNN。从图中来看,主要是由一个激活函数为relu的全连接层,三个激活函数为relu的反卷积层,以及最后的激活函数为tanh的反卷积层,将一个长度为100满足正态分布(或者均匀分布)的向量z变成一个大小为64*64的3通道图像,这也是生成器生成的最终图像。判别器在结构上与生成器是完全对称的,类似于常规的分类网络,这里不再赘述。
注意:由于生成器最后一层的激活函数为tanh,因此输出值的范围在[-1, 1]上,所以真实图片样本也必须要进行缩放范围一致的归一化操作,即![]() ,令
,令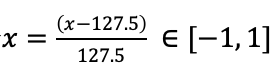 ,将输入样本x上的像素值都归一化到[-1, 1]上,再将这个归一化后的图片送入判别器中,以此来保证每一个输入进判别器的样本分布区间的一致性。当然也可以采用别的归一化方法,只要能让
,将输入样本x上的像素值都归一化到[-1, 1]上,再将这个归一化后的图片送入判别器中,以此来保证每一个输入进判别器的样本分布区间的一致性。当然也可以采用别的归一化方法,只要能让![]() 就好。
就好。
(四) 用DCGAN在MNIST数据集上训练手写数字生成
开源代码仓库地址: https://github.com/carpedm20/DCGAN-tensorflow
在训练了30个epoch后,我把每个epoch生成器生成的100张图片存下来并缩小做成动态图:
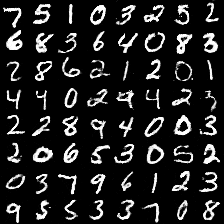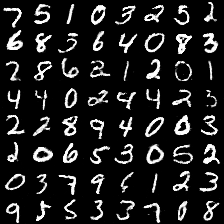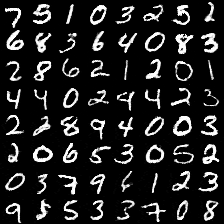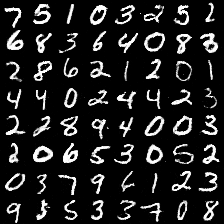
可以看出并没有出现mode collapse现象,生成样本具有一定的多样性,效果还不错。其实主要还是数据集比较简单,图片比较小,复杂纹理信息不多,比较容易生成。
生成的这些数据就可以用作手写数字识别的训练数据。但是这些数据是没有标签的,然而手写数字识别为监督学习,难道还要对它们进行人工标注?这个问题我们留到下一个小节来解决。
(五) 总结
1.训练方法和训练原始GAN的方法保持一致。
2.将两个MLP替换成为两个CNN,生成的图像较原始GAN来说质量更高,更逼真。
3.通过大量实验总结出一套非常有用的trick,使得DCGAN在训练时的稳定性相比原始GAN有显著改善,要知道原始GAN是非常难训练的。
4.后面要讲的模型中G和D的架构均和DCGAN保持一致,便不再赘述。
三、InfoGAN(InformationMaximizing Generative Adversarial Nets)
DCGAN已经能够生成足够逼真的图像了,但是它直接将噪声向量z作为G的输入,没有为z添加任何限制,导致我们根本不知道G主要用到了z的哪个维度来生成图片,即已经将z进行高度耦合处理,所以z的维度信息对于真实数据来说不具有语义特征,也就是说是不可解释的。
![]()
拿上面的图为例,我们发现第三个“7”中间出现了一个横线,但是为什么会出现这个横线,谁也不知道,为了让GAN具有可解释性,比较有代表性的GAN变体——InfoGAN就出现啦,为了解决语义问题,InfoGAN的作者对损失函数进行了一些小的改进,一定程度上让网络学习到了可解释的特征表示,即作者文中所说的interpretable reptesentation。
(一)原理阐述
既然要让输入的噪声向量z带有一定的语意信息,那就人为的为它添加上一些限制,于是作者把G的输入看成两部分:一部分就是噪声z,可以将它看成是不可压缩的噪声向量。另一部分是若干个离散的和连续的latent variables(潜变量)所拼接而成的向量c,用于代表生成数据的不同语意信息。
以MNIST数据集为例,可以用一个离散的随机变量(0-9,用于表示生成数字的具体数值)和两个连续的随机变量(假设用于表示笔划的粗细与倾斜程度)。所以此时的c由一个离散的向量(长度为10)、两个连续的向量(长度为1)拼接而成,即c长度为12。

上图是作者用InfoGAN在MNIST数据集上的部分结果,通过保持离散变量不变、逐渐增大某一个连续的潜变量(论文中是从-2到2),可以看出从左到右数字的笔划逐渐增粗,具有很强的可解释性。所以上一小节遗留的问题就迎刃而解了,理想情况下,我们可以通过这些潜变量来生成无数个满足我们需求的手写数字了!也就不需要再为生成的数据人工打标签了。
所以此时对于G的输入来说不再是单纯的噪声z了,而是z和一个长度为12的向量c,但是仅仅有这个设定还不够,因为生成器的学习具有很高的自由度,它很容易找到一个解,使得:
![]()
此时在生成器看来,z和c是两个完全独立的向量,有没有c都一样可以生成数据,这样生成器就完全绕过了c,导致它起不到应有的作用。
为了解决这个问题,作者通过优化GAN的损失函数来让![]() 和c强制产生联系,使得两者完成建模。作者从信息论中得到启发,提出基于互信息(mutual information)的正则化项。在信息论中,互信息
和c强制产生联系,使得两者完成建模。作者从信息论中得到启发,提出基于互信息(mutual information)的正则化项。在信息论中,互信息![]() 用来衡量“已知随机变量Y的情况下,可以获得多少有关随机变量X的信息”,其计算公式为:
用来衡量“已知随机变量Y的情况下,可以获得多少有关随机变量X的信息”,其计算公式为:

上式中,H表示计算熵值,所以I(X;Y)是两个熵值的差。H(X|Y)衡量的是“给定随机变量的情况下,随机变量X的不确定性”。从公式中可以看出,若X和Y是独立的,此时H(X)=H(X|Y),得到I(X;Y)=0,为最小值。若X和Y有非常强的关联时,即已知Y时,X没有不确定性,则H(X|Y)=0 ,I(X;Y)达到最大值。所以为了让G(z,c)和c之间产生尽量明确的语义信息,必须要让它们二者的互信息足够的大,所以我们对GAN的损失函数添加一个正则项,就可以改写为:
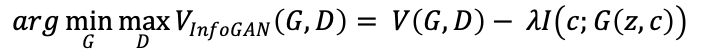
注意![]() 属于G的损失函数的一部分,所以这里为负号,即让该项越大越好,使得G的损失函数变小。其中
属于G的损失函数的一部分,所以这里为负号,即让该项越大越好,使得G的损失函数变小。其中![]() 为平衡两个损失函数的权重。但是,在计算
为平衡两个损失函数的权重。但是,在计算![]() 的过程中,需要知道后验概率分布
的过程中,需要知道后验概率分布![]() ,而这个分布在实际中是很难获取的,因此作者在解决这个问题时采用了变分推理的思想,引入变分分布
,而这个分布在实际中是很难获取的,因此作者在解决这个问题时采用了变分推理的思想,引入变分分布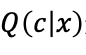 来逼近
来逼近![]() ,进而通过轮流迭代的方法用
,进而通过轮流迭代的方法用![]() 去逼近
去逼近![]() 的下界,得到最终的网路损失函数:
的下界,得到最终的网路损失函数:
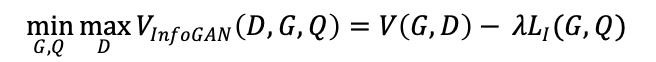
(二)网络结构
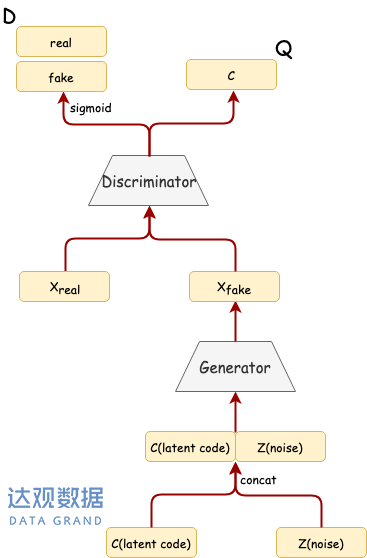
从上图可以清晰的看出,虽然在设计InfoGAN时的数学推导比较复杂,但是网络架构还是非常简单明了的。G和D的网络结构和DCGAN保持一致,均由CNN构成。在此基础上,改动的地方主要有:
1.G的输入不仅仅是噪声向量z了,而是z和具有语意信息的浅变量c进行拼接后的向量输入给G。
2.D的输出在原先的基础上添加了一个新的输出分支Q,Q和D共享全部分卷积层,然后各自通过不同的全连接层输出不同的内容:Q的输出对应于![]() 的c的概率分布,D则仍然判别真伪。
的c的概率分布,D则仍然判别真伪。
(三) InfoGAN的训练流程
假设batch_size=m,数据集为MNIST,则根据作者的方法,不可压缩噪声向量的长度为62,离散潜变量的个数为1,取值范围为[0, 9],代表0-9共10个数字,连续浅变量的个数为2,代表了生成数字的倾斜程度和笔划粗细,最好服从[-2, 2]上的均匀分布,因为这样能够显式的通过改变其在[-2,2]上的数值观察到生成数据相应的变化,便于实验,所以此时输入变量的长度为62+10+2=74。
则在每一个epoch中:
先训练判别器k(比如3)次:
1. 从噪声分布(比如高斯分布)中随机采样出m个噪声向量: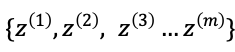 。
。
2.从真实样本x中随机采样出m个样本: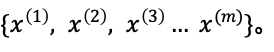
3. 用梯度下降法使损失函数real_loss:![]() 与1之间的二分类交叉熵减小(因为最后判别器最后一层的激活函数为sigmoid,所以要与0或者1做二分类交叉熵,这也是为什么损失函数要取log的原因)。
与1之间的二分类交叉熵减小(因为最后判别器最后一层的激活函数为sigmoid,所以要与0或者1做二分类交叉熵,这也是为什么损失函数要取log的原因)。
4.用梯度下降法使损失函数fake_loss:![]() 与0之间的二分类交叉熵减小。
与0之间的二分类交叉熵减小。
5. 所以判别器的总损失函数d_loss: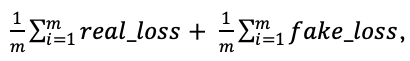 即让d_loss减小。注意在训练判别器的时候分类器中的所有参数要固定住,即不参加训练。
即让d_loss减小。注意在训练判别器的时候分类器中的所有参数要固定住,即不参加训练。
再训练生成器1次:
1. 从噪声分布中随机采样出m个噪声向量: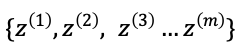 。
。
2. 从离散随机分布中随机采样m个长度为10、one-hot编码格式的向量:![]() 。
。
3. 从两个连续随机分布中各随机采样m个长度为1的向量:![]() ,
,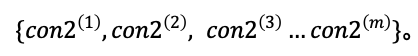
4. 将上面的所有向量进行concat操作,得到长度为74的向量,共m个,并记录每个向量所在的位置,便于计算损失函数。
5. 此时g_loss由三部分组成:一个是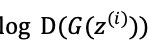 与1之间的二分类交叉熵、一个是Q分支输出的离散浅变量的预测值和相应的输入部分的交叉熵以及Q分支输出的连续浅变量的预测值和输入部分的互信息,并为这三部分乘上适当的平衡因子,其中互信息项的系数是负的。
与1之间的二分类交叉熵、一个是Q分支输出的离散浅变量的预测值和相应的输入部分的交叉熵以及Q分支输出的连续浅变量的预测值和输入部分的互信息,并为这三部分乘上适当的平衡因子,其中互信息项的系数是负的。
6. 用梯度下降法使越小越好。注意在训生成器的时候判别器中的所有参数要固定住,即不参加训练。
直到所有epoch执行完毕,训练结束。
(四)总结
1.G的输入不再是一个单一的噪声向量,而是噪声向量与潜变量的拼接。
2.对于潜变量来说,G和D组成的大网络就好比是一个AutoEncoder,不同之处只是将信息编码在了图像中,而非向量,最后通过D解码还原回。
3.D的输出由原先的单一分支变为两个不同的分支。
4.从信息熵的角度对噪声向量和潜变量的关系完成建模,并通过数学推导以及实验的方式证明了该方法确实有效。
5.通过潜变量,使得G生成的数据具有一定的可解释性。
四、WGAN(Wasserstein GAN)
(一) Wassersteindistance
从前面的章节我们知道,DCGAN的损失函数本质上是让![]() 与
与![]() 间的JS散度尽可能的小,但是很有可能出现
间的JS散度尽可能的小,但是很有可能出现![]() 与
与![]() 两个分布根本就没有重叠的地方,对于任意两个没有交叠、距离足够远的分布,它们之间的JS散度恒定为log2,导致梯度消失,此时
两个分布根本就没有重叠的地方,对于任意两个没有交叠、距离足够远的分布,它们之间的JS散度恒定为log2,导致梯度消失,此时![]() 不可能在训练的过程中向
不可能在训练的过程中向![]() 的方向移动,D也就得不到训练。而WGAN就着手于从损失函数上进行优化,使得训练更加稳定。
的方向移动,D也就得不到训练。而WGAN就着手于从损失函数上进行优化,使得训练更加稳定。
WGAN的作者用大量的数学推导来证明了基于二分类交叉熵的损失函数的缺陷与不合理性,并提出了一种新的损失函数,取名为Wasserstein distance,这个损失函数在任何位置都有着相对平滑的梯度,由于篇幅所限,我尽量直观的向大家阐述,我们先来看一下网络结构。
(二)网络结构
乍一看怎么和DCGAN相差无几呢,是的,作者在网络结构上的变动仅仅是去掉了DCGAN中D最后一层的sigmoid激活函数,使得网络最后一层的输出变成线性的了。
(三) 原理阐述
究竟什么是Wasserstein distance呢?Wasserstein distance用来衡量来两个分布间的距离,而且即使两个分布间没有交叠,也会根据分布相距的远近程度给出一个相应的数值,即损失函数的值会随着两个分布间的距离的远近程度而动态的发生改变,在这篇论文中,作者初步给出Wasserstein distance的表达式:
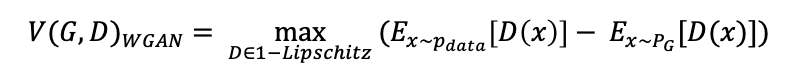
从直观上理解,损失函数是两个期望的差值,并让这个差值尽可能的大,即使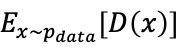 尽可能的大,同时使
尽可能的大,同时使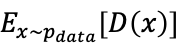 尽可能的小,但仅从这个表达式是不足以让训练变得收敛的,我们来看下图:
尽可能的小,但仅从这个表达式是不足以让训练变得收敛的,我们来看下图:
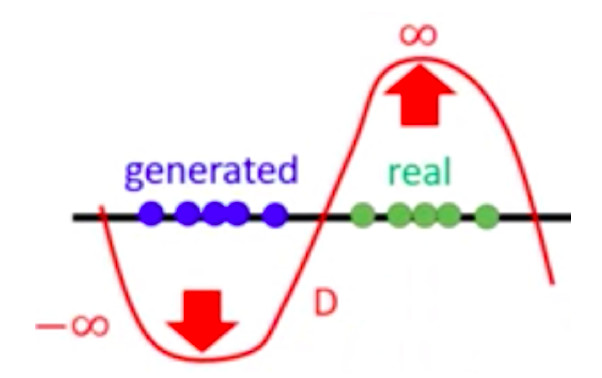
虽然能够准确对生成样本和真实样本完美的区分,但是在没有了sigmoid函数限制值域的情况下会让D在真实样本上的输出值趋于无穷大,而在生成样本上的输出值趋于无穷小,导致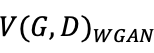
永远不会收敛,为了避免出现这个问题,作者在损失函数中添加了一个额外的限制条件:
 限制是指:在样本空间中,要求判别器函数D(x)梯度值不大于一个有限的常数k,通过权重限制的方式保证了权重参数的有界性,间接限制了其梯度信息。
限制是指:在样本空间中,要求判别器函数D(x)梯度值不大于一个有限的常数k,通过权重限制的方式保证了权重参数的有界性,间接限制了其梯度信息。
目的就是让D的输出曲线尽可能的平滑,不让它趋向与无穷大或者无穷小,那么怎么限制呢?在作者2017年发布的WGAN中只是对D的权重进行简单的clipping操作:
人为的规定一个阈值c,并将D中的网络参数数值全部限制在上[-c,c],对于D中的任意一个参数w,如果 w>c, 则令w=c。如果w<-c,则令w=-c,即始终保持![]() ,该操作称为weight clipping,使得D的输出曲线比较平滑。是的,就是这么简单!实验证明该算法虽然简单粗暴,但确实使得训练过程变得更加稳定。另一方面,c的取值范围很难确定,是一个依赖于经验的数值。如果取的过小,网络参数都被限制在了一个比较小的范围,导致D的拟合能力受限。如果取的过大,又可能会让D的输出值趋近于无穷,网络又无法收敛,所以它的取值极度依赖实验,不过一般地,将c取为0.01是一个比较个合理的值。综上,WGAN改动的地方主要有以下三点:
,该操作称为weight clipping,使得D的输出曲线比较平滑。是的,就是这么简单!实验证明该算法虽然简单粗暴,但确实使得训练过程变得更加稳定。另一方面,c的取值范围很难确定,是一个依赖于经验的数值。如果取的过小,网络参数都被限制在了一个比较小的范围,导致D的拟合能力受限。如果取的过大,又可能会让D的输出值趋近于无穷,网络又无法收敛,所以它的取值极度依赖实验,不过一般地,将c取为0.01是一个比较个合理的值。综上,WGAN改动的地方主要有以下三点:
1.D最后一层去掉sigmoid激活函数,所以它现在的输出值不再代表二分类的概率了。 2.G和D的loss不再取log,即不再用与0或者1的二分类交叉熵作为损失函数了。 3.每次更新D的参数后,将其所有参数的绝对值截断到不超过一个固定常数c(经验数值,可以取为0.01),即weight clipping操作,其实本质上就是对D的参数添加了一个简单粗暴的正则项。
(四) WGAN的训练流程
假设batch_size=m,则在每一个epoch中:
先训练判别器k(比如5)次:
1. 从噪声分布(比如高斯分布)中随机采样出m个噪声向量:![]() .
.
2. 从真实样本x中随机采样出m个真实样本:![]()
3. 用梯度下降法使损失函数![]() 越小越好(取负号的原因是一般的深度学习框架只能让损失函数越来越小,所以这里加个负号就和原先最大化的逻辑保持一致了)。
越小越好(取负号的原因是一般的深度学习框架只能让损失函数越来越小,所以这里加个负号就和原先最大化的逻辑保持一致了)。
4. 用梯度下降法使损失函数![]() 越小越好,并保存
越小越好,并保存![]() 生成的假样本的结果,记
生成的假样本的结果,记![]() 。
。
5. 所以判别器的总损失函数![]() ,即让d_loss越小越好。注意在训练判别器的时候分类器中的所有参数要固定住,即不参加训练。
,即让d_loss越小越好。注意在训练判别器的时候分类器中的所有参数要固定住,即不参加训练。
6. 检查D中所有可训练参数的值,将它们限制在一个人为规定的常数|c|内,即![]() ,令
,令![]()
(可以将c取为0.01)。
再训练生成器1次:
1. 从噪声分布中随机采样出m个噪声向量:![]() 用梯度下降法使损失函数
用梯度下降法使损失函数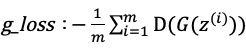 越小越好。注意在训生成器的时候判别器中的所有参数要固定住,即不参加训练。
越小越好。注意在训生成器的时候判别器中的所有参数要固定住,即不参加训练。
直到所有epoch执行完毕,训练结束。
(五) 总结
1.修改一直在沿用的原始GAN损失函数,提出一种新的损失函数,使得GAN的训练变得比以前稳定。
2.提出针对判别器的weight clipping操作,并经过大量实验证明确实能够让训练变得稳定、加快模型收敛,而且代码实现上也非常简单,对DCGAN代码的改动不超过20行就能让它变成WGAN。
3.模型是否能够收敛高度依赖于超参数c的取值,而该参数的选取通常依赖于实验。如果选取得当,能够提高网络训练的稳定性,如果选取不当,模型反而无法收敛。
五、WGAN_GP(WassersteinGAN with Gradient Penality)
(一) gradient penality
在提出了WGAN后,作者继续在WGAN上进行优化,又给出了一种新的损失函数,抛弃weight clipping,也就不再需要经验常数c了,取而代之的是gradient penality(梯度惩罚),因此取名为WGAN_GP,也叫Improved_WGAN。
Gradient penality是指:对D的每一个输入样本x,使得![]() 。意思是对于任意一个输入样本x,用D的输出结果D(x)对求梯度后的值的L2范数不大于1。
。意思是对于任意一个输入样本x,用D的输出结果D(x)对求梯度后的值的L2范数不大于1。
上面的解释可能有些拗口,我们从一维空间中的函数f(x)来进行阐述:一维函数f(x),对于任意输入x,该函数满足: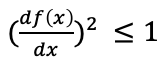 ,即任意一点的斜率的平方不大于1,进而可以推出:
,即任意一点的斜率的平方不大于1,进而可以推出: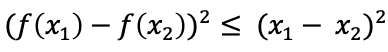 ,可想而知f(x)的函数曲线是比较平滑的,所以称为梯度惩罚。那为什么是L2范数呢而不是L1范数呢?原因很简单,L1范数会破坏一个函数的可微性呀,所以L2范数是非常合理的!
,可想而知f(x)的函数曲线是比较平滑的,所以称为梯度惩罚。那为什么是L2范数呢而不是L1范数呢?原因很简单,L1范数会破坏一个函数的可微性呀,所以L2范数是非常合理的!
注意前面我说的是针对于D的每一个输入样本,都让它满足![]() ,实际上这是不现实的,所以作者又想了一个办法来解决这个问题:假设从真实数据中采样出来的一个点称为x(这个点是高维空间中的点),G利用采样得到的噪声向量所生成的假数据称为
,实际上这是不现实的,所以作者又想了一个办法来解决这个问题:假设从真实数据中采样出来的一个点称为x(这个点是高维空间中的点),G利用采样得到的噪声向量所生成的假数据称为![]() 在这两点之间的某一个位置采样一个点记为,即对于每一个
在这两点之间的某一个位置采样一个点记为,即对于每一个![]() ,尽量让
,尽量让![]() 。那么最常见的满足上述要求的采样方法就是线性采样方法了,即在x与
。那么最常见的满足上述要求的采样方法就是线性采样方法了,即在x与![]() 所形成的超平面上任意选取一个点
所形成的超平面上任意选取一个点![]() ,换句话说就是在生成样本和真实样本间做一个线性插值,所以存在
,换句话说就是在生成样本和真实样本间做一个线性插值,所以存在![]() 。
。
在新的损失函数闪亮登场之前,我们还有一个小小的优化!因为作者最后发现,其实让![]() 是最好的方案,而不是把1作为上、下限,别问我为什么,作者也不知道!因为是通过大量的实验总结出来的。
是最好的方案,而不是把1作为上、下限,别问我为什么,作者也不知道!因为是通过大量的实验总结出来的。
那么WGAN_GP的核心就在线性插值这了,为了不让这部分变得太抽象,我们用pytorch来实现一下插值这部分。
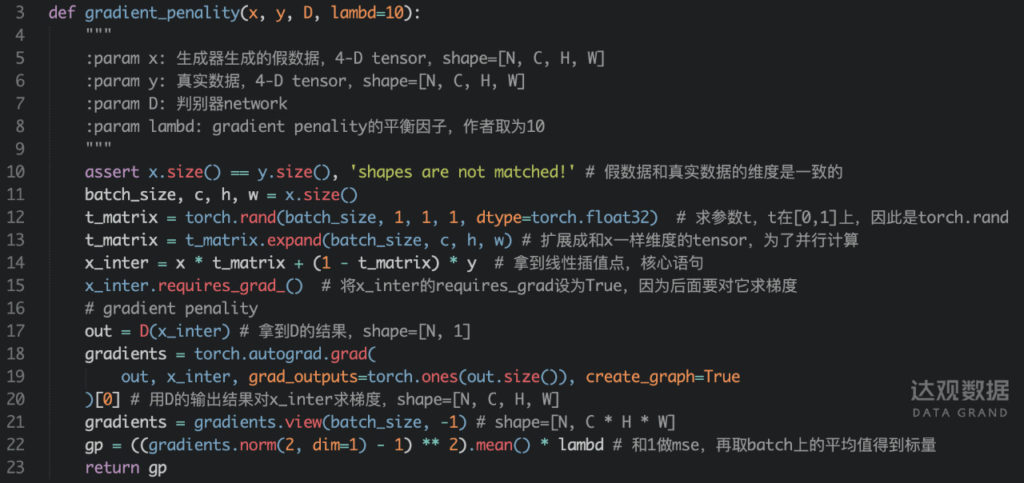
所以,新的损失函数可以写为:
![]()
说了这么多,其实用数学公式表达出来还是非常简单的,式子中前两项仍然是WGAN的损失函数,只是新添加了一个正则项,![]() 便是在真实数据和生成数据之间通过线性插值得到的点,即尽量让D对它的梯度的L2范数越接近于1,使
便是在真实数据和生成数据之间通过线性插值得到的点,即尽量让D对它的梯度的L2范数越接近于1,使![]() 越大越好,通过该正则项,能让损失函数上的每一点都有较为平滑的梯度,训练也就更加稳定,大大降低了训练GAN的难度。超参数
越大越好,通过该正则项,能让损失函数上的每一点都有较为平滑的梯度,训练也就更加稳定,大大降低了训练GAN的难度。超参数![]()
用于对这两部分的损失函数进行平衡,作者通过实验发现![]() =10是一个比较合理的数值。
=10是一个比较合理的数值。
(二) WGAN_GP的训练流程
假设batch_size=m,则在每一个epoch中:
先训练判别器k(比如5)次:
1. 从噪声分布(比如高斯分布)中随机采样出m个噪声向量:![]() 。
。
2. 从真实样本x中随机采样出m个真实样本:![]() 。
。
3. 用梯度下降法使损失函数 ![]() 越小越好(取负号的原因是一般的深度学习框架只能让损失函数越来越小,所以这里加个负号就和原先最大化的逻辑保持一致了)。
越小越好(取负号的原因是一般的深度学习框架只能让损失函数越来越小,所以这里加个负号就和原先最大化的逻辑保持一致了)。
4. 用梯度下降法使损失函数![]() 越小越好,并保存
越小越好,并保存![]() 生成的假样本的结果,记为
生成的假样本的结果,记为![]() 。
。
5.在这m个假样本与已经得到的m个真实样本![]() 进行线性插值,得到m个插值样本:。将m个插值样本送入D中得到的结果对输入求梯度,使
进行线性插值,得到m个插值样本:。将m个插值样本送入D中得到的结果对输入求梯度,使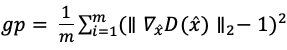 越小越好。
越小越好。
6.所以判别器的总损失函数d_loss =read_loss + fake_loss + gp,即让d_loss越小越好。注意在训练判别器的时候分类器中的所有参数要固定住,即不参加训练。为平衡两个损失函数的权重,取为10是比较合理的数值。
再训练生成器1次:
从噪声分布中随机采样出m个噪声向量:![]() 用梯度下降法使损失函数g_loss:
用梯度下降法使损失函数g_loss:
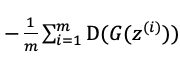 越小越好。注意在训练生成器的时候判别器中的所有参数要固定住,即不参加训练。
越小越好。注意在训练生成器的时候判别器中的所有参数要固定住,即不参加训练。
直到所有epoch执行完毕,训练结束。
(三) WGAN_GP小试牛刀
在写这篇文章的时候,正好看到TinyMind举办了一个关于用GAN生成书法字体的比赛https://www.tinymind.cn/competitions/45 – ranking,当时距离比赛结束仅剩三天时间,但是为了让文章更充实一些,还是马不停蹄的把数据集下载到本地,不说了,GAN就完了!
比赛目的是用GAN来生成图片大小为128*128的书法字体图片,评判标准是上传10000张自己生成的书法字进行系统评分,当然质量、多样性越高越好。训练集中共有100种字,每种字又有400张不同的字体图片,所以一共是40000张图片,每张图片的高、宽都在200到400之间,并且为灰度图像,那么我们就来用WGAN_GP来完成这个小比赛!,参考开源代码地址:https://github.com/igul222/improved_wgan_training,实现框架为tensorflow。
先来看看数据集长什么样吧。

这里我将每种字随机抽出1个并resize到64*64进行排列展示,所以正好100个不同的字,发现有一些根本不认识!不过认不认识没关系,对于网络来说它需要的仅仅是数据而已。另外一点就是这里面有一些脏数据,比如大字下面还有一些小字,这肯定不是我们期望的样本,但是我在这里并没有过滤掉这些脏数据,一是工作量太大,不能自动完成,需要人工检查。二是先尝试着训练一下,不行的话再想办法剔除,事实证明对结果影响不大。
原repo的代码只能生成64*64的图片,所以需要对其网络结构进行相应的改进,使其能够产生128*128的图片,改进的方案也非常简单:
1)将G的第一个全连接层的输出神经元个数扩大为原先的两倍,所以这时reshape后tensor深度变为原先的两倍,此后卷积核的个数每层都除以2。
2)将生成器最后一层的激活函数改为relu,接一个batch normalization,并在其后面再添加一个deconv层,激活函数为tanh。
3)将判别器的最后一层的全连接层改为卷积层,接一个batch normalization,激活函数为leaky relu,并重复一次,即再降采样一次,reshape后再接一个单神经元的全连接层就可以了,注意没有激活函数。
4)因为是新的数据了,所以数据读取以及组织数据的代码需要自己写。损失函数、训练代码不用动。可能需要在实验中对学习率进行调整。
在训练了40个epoch后,我把每个epoch生成器生成的100张图片存下来并缩小做成动态图:

(gif 图片太大,截取部分静态图)
可以看出生成的数据已经趋于稳定,变动不大。由于时间有限再加上工作繁忙,没有足够的时间对网络进行优化,排名没进前10,因为前10名才有奖励呀,重在参与嘛!将10000张生成的图片上传后,官网展示了部分图片:

个人感觉效果一般吧,不过在参加了这个小比赛后让我学到了很多知识,也认识到了自身的不足。
- 直接把数据的标签信息仍掉了,所有数据同等对待一起训的,导致最终数据的多样性可能不够高,拉低评分。
- 既然是比赛,采取合理的小技巧来达到更高的评分也是可以的。我们知道越大的图片越不好生成,而64*64的图片相对来说比较容易生成,也易于训练。可以只生成64*64的图片,提交成绩的时候再通过一些好的插值方法(比如双三次插值)resize到128*128!赛后我知道确实有人是这样做的。不过这种方法所生成的书法字肯定没有直接生成128*128的图片质量高。
- 其实有很多比WGAN_GP更先进、生成效果更好的网络,毕竟这篇文章的发表时间是在2017年,但是新手上路嘛,以稳为主,就选择了一个比较经典的模型。
-
为以后的手写字识别提供了不少思路,通过GAN来增加训练数据量是非常可行的方法。
(四) 总结
1.为WGAN的损失函数提出了一种新的正则方法——gradient penality,从而更好的解决了训练GAN的过程中梯度消失的问题。
2.比标准WGAN拥有更快的收敛速度,并能生成更高质量的样本。
3.将resnet中的残差块成功应用于生成器和判别器中,使网络可以变得更深、同时能够生成质量更高的样本,并且训练过程也更加稳定。
4.不需要过多的调参,成功训练多种针对图片的GAN结构。
六 、总结
1.本文沿着GANDCGANInfoGANWGANWGAN_GP的路线来介绍GAN,其初衷是能让大家对GAN有一个感性的了解,所以大量的数学公式推导没有列出来。当然,还有很多优秀的GAN本文没有涉及到,毕竟以入门为主嘛!相信在读完本文后能够让大家更好的理解当下比较新颖并且有意思的GAN。
2.其实GAN在最终的实现上都非常简单,比较难的地方是涉及模型损失函数的优化以及相关数学推导、还有就是在现有网络上的创新,从而提出一个新颖并且生成质量高的GAN模型。
3.虽然GAN在图像生成上取得了耀眼的成绩,但并没有在NLP领域取得显著成果。其中一个主要原因是图像数据都是实数空间上的连续数据,而NLP中大多都是离散数据,例如分词后的词组。而对于连续型数据,就可以略微改变合成的数据,比如一个浮点类型的像素值为0.64,将这个值改为0.65是没有问题的。但是对于离散型数据,如果输出了一个单词”hello”,但接下来不能将其改为”hello+0.01”,因为根本没有这个单词!所以NLP中应用GAN是比较困难的。但并不代表没有人研究这个方向,有一些学者已经能够将GAN应用于NLP中了,大多数要与强化学习结合,感兴趣的小伙伴可以读一读TextGAN、SeqGAN这两篇文章。
4.由于平时对GAN的接触比较少,再加上专业水平有限,文章中出错之处在所难免,还望多多包涵。
七、参考文献
[1]IanJ. Goodfellow, Jean Pouget-Abadie and Mehdi Mirza, “Gererative AdversarialNetworks,” ArXiv preprint arXiv:1406.2661, 2014.
[2]AlecRadford, Luke Metz and Soumith Chintala, “Unsupervised Representation Learningwith Deep Convolutional Generative Adversarial Networks,” ArXiv preprintaxXiv:1511.06434, 2016.
[3]Xi Chen, Yan Duan and Rein Houthooft, “InfoGAN:Interpretable Representation Learning by Information Maximizing GenerativeAdversarial Nets,” ArXiv Preprint arXiv:1606.03657, 2016.
[4]Martin Arjovsky, Soumith Chintala and Léon Bottou, “WassersteinGAN,” ArXiv preprint arXiv:1606.03657, 2016.
[5]Ishaan Gulrajani, Faruk Ahmed and Martin Arjovsky, “ImprovedTraining of Wasserstein GANs”, ArXiv preprint arXiv:1704.00028, 2017.
BOUT
关于作者
马振宇:达观数据算法工程师,负责达观数据OCR方向的相关算法研发,优化工作。




