
近十年来,随着Hadoop生态系统的不断完善,Hadoop早已成为大数据事实上的行业标准之一。面对当今互联网产生的巨大的TB甚至PB级原始数据,利用基于Hadoop的数据仓库解决方案Hive早已是Hadoop的热点应用之一。达观数据团队长期致力于研究和积累Hadoop系统的技术和经验,并构建起了分布式存储、分析、挖掘以及应用的整套大数据处理平台。本文将从Hive的原理、架构及优化等方面来分享Hive的一些心得和使用经验,希望对大家有所收货。

1. Hive基本原理
Hadoop是一个流行的开源框架,用来存储和处理商用硬件上的大规模数据集。对于HDFS上的海量日志而言,编写Mapreduce程序代码对于类似数据仓库的需求来说总是显得相对于难以维护和重用,Hive作为一种基于Hadoop的数据仓库解决方案应运而生,并得到了广泛应用。
Hive是基于Hadoop的数据仓库平台,由Facebook贡献,其支持类似SQL的结构化查询功能。Facebook设计开发Hive的初衷就是让那些熟悉sql编程方式的人也可以更好的利用hadoop,hive可以让数据分析人员只关注于具体业务模型,而不需要深入了解Map/Reduce的编程细节,但是这并不意味着使用hive不需要了解和学习Map/Reduce编程模型和hadoop,复杂的业务需求和模型总是存在的,对于Hive分析人员来说,深入了解Hadoop和Hive的原理和Mapreduce模型,对于优化查询总有益处。
以下先以一个简单的例子说明利用hadoop Map/Reduce程序和Hive实现hadoop word count的例子。
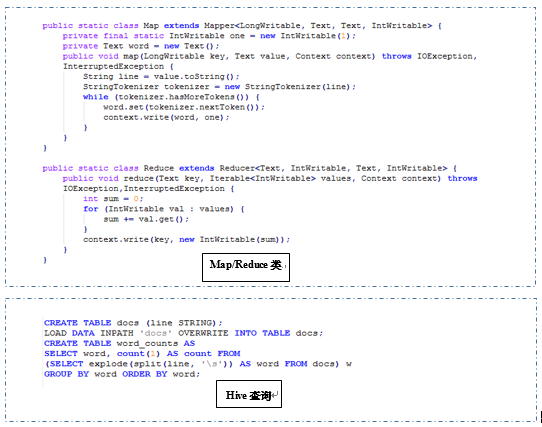
图1:mapreduce和hive分别实现count
通过以上可以看出,hive优点:成本低,可以通过类sql语句快速实现简单或复杂的MapReduce统计。
借助于Hadoop和HDFS的大数据存储能力,数据仍然存储于Hadoop的HDFS中,Hive提供了一种类SQL的查询语言:HiveQL(HQL),对数据进行管理和分析,开发人员可以近乎sql的方式来实现逻辑,从而加快应用开发效率。(关于Hadoop、hdfs的更多知识请参考hadoop官网及hadoop权威指南)
HQL经过解析和编译,最终会生成基于Hadoop平台的Map Reduce任务,Hadoop通过执行这些任务来完成HQL的执行。
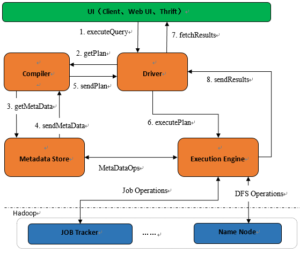
1.1 Hive组件
Hive的组件总体上可以分为以下几个部分:用户接口(UI)、驱动、编译器、元数据(Hive系统参数数据)和执行引擎。
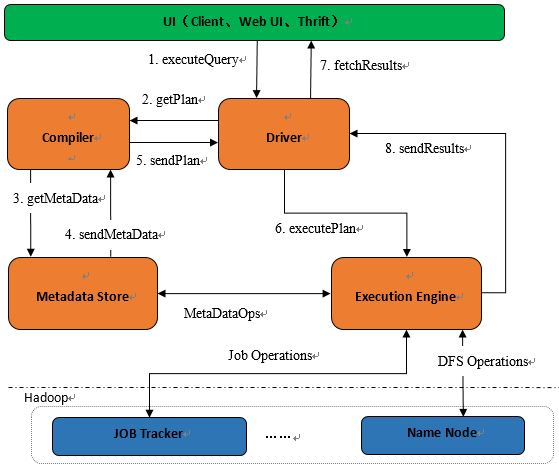
图2:Hive执行流程图
1) 对外的接口UI包括以下几种:命令行CLI,Web界面、JDBC/ODBC接口;
2) 驱动:接收用户提交的查询HQL;
3) 编译器:解析查询语句,执行语法分析,生成执行计划;
4) 元数据Metadata:存放系统的表、分区、列、列类型等所有信息,以及对应的HDFS文件信息等;
5) 执行引擎:执行执行计划,执行计划是一个有向无环图,执行引擎按照各个任务的依赖关系选择执行任务(Job)。
需要注意的是,元数据库一般是通过关系型数据库MySQL来存储。元数据维护了库信息、表信息、列信息等所有内容,例如表T包含哪些列,各列的类型等等。因此元数据库十分重要,需要定期备份以及支持查询的扩展性。
读时验证机制
与传统数据库对表数据进行写时严重不同,Hive对数据的验证方式为读时模式,即只有在读表数据的时候,hive才检查解析具体的字段、shema等,从而保证了大数据量的快速加载。
既然hive采用的读时验证机制,那么 如果表schema与表文件内容不匹配,会发生什么呢?
答案是hive会尽其所能的去读数据。如果schema中表有10个字段,而文件记录却只有3个字段,那么其中7个字段将为null;如果某些字段类型定位为数值类型,但是记录中却为非数值字符串,这些字段也将会被转换为null。简而言之,hive会努力catch读数据时遇到的错误,并努力返回。
既然Hive表数据存储在HDFS中且Hive采用的是读时验证方式,定义完表的schema会自动生成表数据的HDFS目录,且我们可以以任何可能的方式来加载表数据或者利用HDFS API将数据写入文件,同理,当我们若需要将hive数据写入其他库(如oracle),也可以直接通过api读取数据再写入目标库。
在实际生产环境中,当需要数据仓库之间的迁移时,就可以直接利用api将源库的数据直接写入hive库的表文件中,包括淘宝开源的datax数据交换系统都采用类似的方式来交换跨库数据。
再次注意,加载或者写入的数据内容要和表定义的schema一致,否则将会造成字段或者表为空。
1.2 Hive数据模型
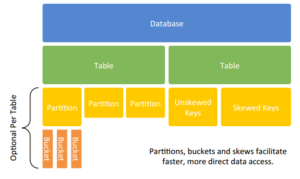
从数据仓库的角度看,Hive是建立在Hadoop上的数据仓库基础架构,可以方便的ETL操作。Hive没有专门的数据存储格式,也没有为数据建立索引,用于可以非常自由的组织Hive中的表,只需要在创建表的时候定义好表的schema即可。Hive中包含4中数据模型:Tabel、ExternalTable、Partition、Bucket。
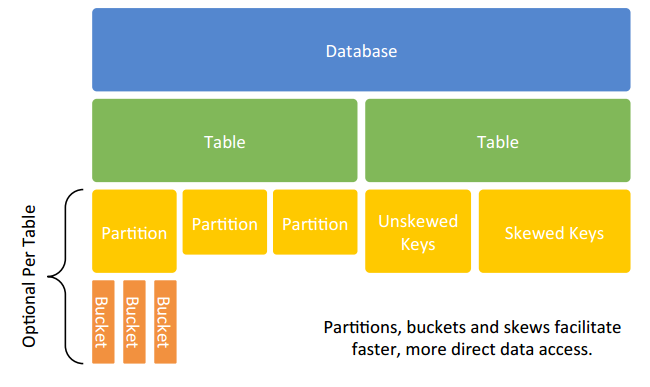
图3:hive数据模型
- Table:类似与传统数据库中的Table,每一个Table在Hive中都有一个相应的目录来存储数据。例如:一个表t,它在HDFS中的路径为:/user/hive/warehouse/t。
- Partition:类似于传统数据库中划分列的索引。在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition数据都存储在对应的目录中。例如:t表中包含ds和city两个Partition,则对应于ds=2014,city=beijing的HDFS子目录为:/user/hive/warehouse/t/ds=2014/city=Beijing;
需要注意的是,分区列是表的伪列,表数据文件中并不存在这个分区列的数据。
- Buckets:对指定列计算的hash,根据hash值切分数据,目的是为了便于并行,每一个Buckets对应一个文件。将user列分数至32个Bucket上,首先对user列的值计算hash,比如,对应hash=0的HDFS目录为:/user/hive/warehouse/t/ds=2014/city=Beijing/part-00000;对应hash=20的目录为:/user/hive/warehouse/t/ds=2014/city=Beijing/part-00020。
- External Table指向已存在HDFS中的数据,可创建Partition。Managed Table创建和数据加载过程,可以用统一语句实现,实际数据被转移到数据仓库目录中,之后对数据的访问将会直接在数据仓库的目录中完成。删除表时,表中的数据和元数据都会删除。External Table只有一个过程,因为加载数据和创建表是同时完成。数据是存储在Location后面指定的HDFS路径中的,并不会移动到数据仓库中。
1.3 Hive翻译成MapReduce Job
Hive编译器将HQL代码转换成一组操作符(operator),操作符是Hive的最小操作单元,每个操作符代表了一种HDFS操作或者MapReduce作业。Hive中的操作符包括:
表:Hive执行常用的操作符列表
| 操作符 | 描述 |
| TableScanOperator | 扫描hive表数据 |
| ReduceSinkOperator | 创建将发送到Reducer端的<Key,Value>对 |
| JoinOperator | Join两份数据 |
| SelectOperator | 选择输出列 |
| FileSinkOperator | 建立结果数据,输出至文件 |
| FilterOperator | 过滤输入数据 |
| GroupByOperator | Group By 语句 |
| MapJoinOperator | Mapjoin |
| LimitOperator | Limit语句 |
| UnionOperator | Union语句 |
对于MapReduce操作单元,Hive通过ExecMapper和ExecReducer执行MapReduce任务。
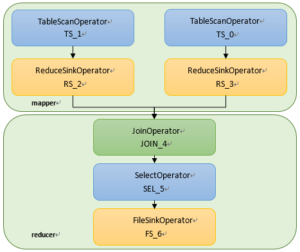
对于Hive语句:
INSERT OVERWRITE TABLE read_log_tmp
SELECT a.userid,a.bookid,b.author,b.categoryid
FROM user_read_log a JOIN book_info b ON a.bookid = b.bookid;
其执行计划为:
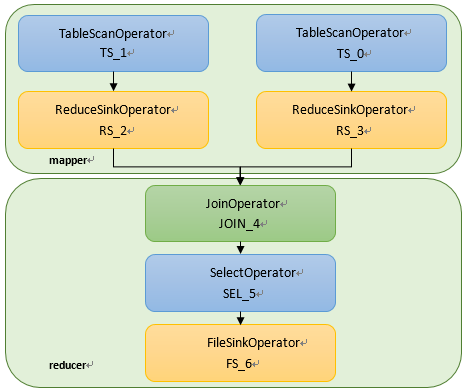
图4:reduce端join的任务执行流程
1.4 与一般SQL的区别
Hive 视图与一般数据库视图
Hive视图与一般数据库视图作用角色相同,都是基于数据规模缩减或者基于安全机制下的某些条件查询下的数据子集。Hive视图只支持逻辑视图,不支持物化视图,即每次对视图的查询hive都将执行查询任务,因此视图不会带来性能上的提升。作为Hive查询优化的一部分,对视图的查询条件语句和视图的定义查询条件语句将会尽可能的合并成一个条件查询。
Hive索引与一般数据库索引
相比于传统数据库,Hive只提供有限的索引功能,通过在某些字段上建立索引来加速某些操作。通常当逻辑分区太多太细,partition无法满足时,可以考虑建立索引。Hive1.2.1版本目前支持的索引类型有CompactIndexHandler和Bitmap。
CompactIndexHandler 压缩索引通过将列中相同的值得字段进行压缩从而减小存储和加快访问时间。需要注意的是Hive创建压缩索引时会将索引数据也存储在Hive表中。对于表tb_index (id int, name string) 而言,建立索引后的索引表中默认的三列一次为索引列(id)、hdfs文件地址(_bucketname)、偏移量(offset)。特别注意,offset列类型为array<bigint>。
Bitmap 位图索引作为一种常见的索引,如果索引列只有固定的几个值,那么就可以采用位图索引来加速查询。利用位图索引可以方便的进行AND/OR/XOR等各类计算,Hive0.8版本开始引入位图索引,位图索引在大数据处理方面的应用广泛,比如可以利用bitmap来计算用户留存率(索引做与运算,效率远好于join的方式)。如果Bitmap索引很稀疏,那么就需要对索引压缩以节省存储空间和加快IO。Hive的Bitmap Handler采用的是EWAH(https://github.com/lemire/javaewah)压缩方式。

图5:Hive compact索引及bitmap索引
从Hive索引功能来看,其主要功能就是避免第一轮mr任务的全表扫描,而改为扫描索引表。如果索引索引表本身很大,其开销仍然很大,在集群资源充足的情况下,可以忽略使用hive下的索引。
2. Schema设计
没有通用的schema,只有合适的schema。在设计Hive的schema的时候,需要考虑到存储、业务上的高频查询造成的开销等等,设计适合自己的数据模型。
2.1 设置分区表
对于Hive来说,利用分区来设计表总是必要的,分区提供了一种隔离数据和优化查询的便利的方式。特别是面对日益增长的数据规模。设置符合逻辑的分区可以避免进行全表扫描,只需加载特定某些hdfs目录的数据文件。
设置分区时,需要考虑被设置成分区的字段,按照时间分区一般而言就是一个好的方案,其好处在于其是按照不同时间粒度来确定合适大小的数据积累量,随着时间的推移,分区数量的增长是均匀的,分区的大小也是均匀的。达观数据每日处理大量的用户日志,对于user_log来说,设置分区字段为日期(天)是合理的。如果以userid字段来建立动态分区,而userid的基数是非常大的,显然分区数目是会超过hive的默认设置而执行失败。如果相对userid进行hash,我们可以以userid进行分桶(bucket),根据userid进行hash然后分发到桶中,相同hash值的userid会分发到同一个桶中。每个桶对应着一个单独的文件。
2.2 避免小文件
虽然分区有利于隔离数据和查询,设置过多过细的分区也会带来瓶颈,主要是因为HDFS非常容易存储大数据文件,由于分区对应着hdfs的目录结构,当存在过多的分区时,意味着文件的数目就越多,过多增长的小文件会给namecode带来巨大的性能压力。同时小文件过多会影响JOB的执行,hadoop会将一个job转换成多个task,即使对于每个小文件也需要一个task去单独处理,task作为一个独立的jvm实例,其开启和停止的开销可能会大大超过实际的任务处理时间。因此,hive表设计的分区不应该过多过细,每个目录下的文件足够大,应该是文件系统中块大小的若干倍。(达观数据 文辉)
查询避免生成小文件技巧
既然hive或者说hadoop需要大文件,HQL执行语句也需要注意输入文件和输出文件的大小,防止生成过多小文件。hive可以通过配置参数在mr过程中合并小文件。
Map合并小文件:
set mapred.max.split.size=256000000 #每个Map最大输入大小(单位:字节)
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat #执行Map前进行小文件合并
输出合并:
set hive.merge.mapfiles = true #在Map-only的任务结束时合并小文件
set hive.merge.mapredfiles= true #在Map-Reduce的任务结束时合并小文件
set hive.merge.size.per.task = 256*1000*1000 #合并文件的大小
set hive.merge.smallfiles.avgsize=16000000 #当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
create table user_log (user_id int,url string,source_ip string)
partitioned by (dt string)
clustered by (user_id) into 96 buckets;
我们知道hive输出最终是mr的输出,即reducer(或mapper)的输出,有多少个reducer(mapper)输出就会生成多少个输出文件,根据shuffle/sort的原理,每个文件按照某个值进行shuffle后的结果。我们可通过设置hive.enforce.bucketing=true来强制将对应记录分发到正确桶中,或者通过添加cluster by语句以及设置set mapred.reduce.tasks=96来设置reducer的数目,从而保证输出与schema一致。根据hive的读时验证方式,正确的插入数据取决与我们自己,而不能依靠schema。
2.3 选择文件格式
Hive提供的默认文件存储格式有textfile、sequencefile、rcfile等。用户也可以通过实现接口来自定义输入输的文件格式。
在实际应用中,textfile由于无压缩,磁盘及解析的开销都很大,一般很少使用。Sequencefile以键值对的形式存储的二进制的格式,其支持针对记录级别和块级别的压缩。rcfile是一种行列结合的存储方式(text file和sequencefile都是行表[row table]),其保证同一条记录在同一个hdfs块中,块以列式存储。一般而言,对于OLTP而言,行表优势大于列表,对于OLAP而言,列表的优势大于行表,特别容易想到当做聚合操作时,列表的复杂度将会比行表小的多,虽然单独rcfile的列运算不一定总是存在的,但是rcfile的高压缩率确实减少文件大小,因此实际应用中,rcfile总是成为不二的选择,达观数据平台在选择文件存储格式时也大量选择了rcfile方案。
3. 查看执行计划及优化
达观的数据仓库基于Hive搭建,每日需要处理大量的计算流程,Hive的稳定性和性能至关重要。众多的任务需要我们合理的调节分配集群资源,合理的配置各参数,合理的优化查询。Hive优化包含各个方面,如job个数优化、job的map/reducer个数优化、并行执行优化等等,本节将主要从HQL查询优化角度来具体说明
3.1 Join语句
对于上述的join语句
INSERT OVERWRITE TABLE read_log_tmp
SELECT a.userid,a.bookid,b.author
FROM user_read_log a JOIN book_info b ON a.bookid = b.bookid;
explain该查询语句后:

图:map端join的执行计划
由于表中数据为空,对于小数据量,hive会自动采取map join的方式来优化join,从mapreduce的编程模型来看,实现join的方式主要有map端join、reduce端join。Map端join利用hadoop 分布式缓存技术通过将小表变换成hashtable文件分发到各个task,map大表时可以直接判断hashtable来完成join,注意小表的hashtable是放在内存中的,在内存中作匹配,因此map join是一种非常快的join方式,也是一种常见的优化方式。如果小表够小,那么就可以以map join的方式来完成join完成。Hive通过设置hive.auto.convert.join=true(默认值)来自动完成map join的优化,而无需显示指示map join。缺省情况下map join的优化是打开的。
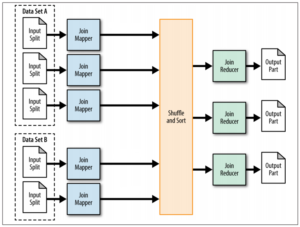
Reduce端join需要reducer来完成join过程,对于上述join代码,reduce 端join的mr流程如下,
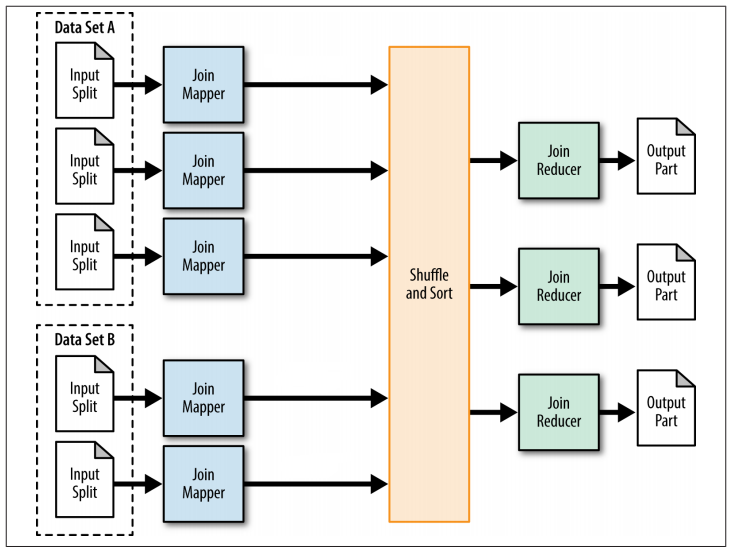
图:reduce端join的mapreduce过程
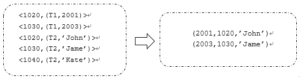
相比于map join, reduce 端join无法再map过程中过滤任何记录,只能将join的两张表的所有数据按照join key进行shuffle/sort,并按照join key的hash值将<key,value>对分发到特定的reducer。Reducer对于所有的键值对执行join操作,例如0号(bookid的hash值为0)reducer收到的键值对如下,其中T1、T2表示记录的来源表,起到标识作用:
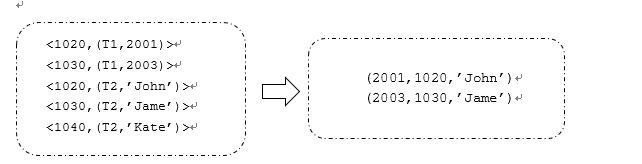
图:reduce端join的reducer join
Reducer端join无法避免的reduce截断以及传输的大量数据都会给集群网络带来压力,从上图可以看出所有hash(bookid) % reducer_number等于0的key-value对都会通过shuffle被分发到0号reducer,如果分到0号reducer的记录数目远大于其他reducer的记录数目,显然0号的reducer的数据处理量将会远大于其他reducer,因此处理时间也会远大于其他reducer,甚至会带来内存等其他问题,这就是数据倾斜问题。对于join造成的数据倾斜问题我们可以通过设置参数set Hive.optimize.skewjoin=true,让hive自己尝试解决join过程中产生的倾斜问题。
3.2 Group by语句
我们对user_read_log表按userid goup by语句来继续探讨数据倾斜问题,首先我们explain group by语句:
explain select userid,count(*) from user_read_log group by userid。
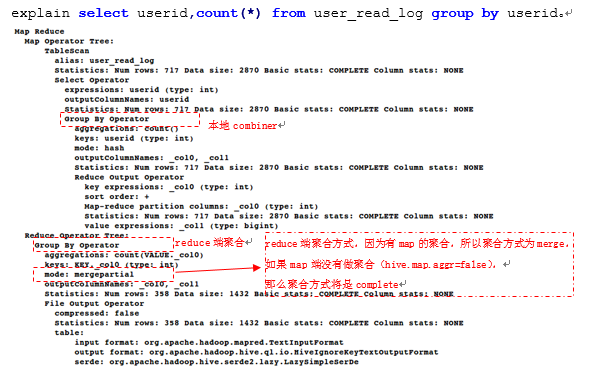
图:goup by的执行计划
Group by的执行计划按照userid的hash值分发记录,同时在map端也做了本地reduce,group by的shuffle过程是按照hash(userid)来分发的,实际应用中日志中很多用户都是未注册用户或者未登录,userid字段为空的记录数远大于userid不为空的记录数,当所有的空userid记录都分发到特定某一个reducer后,也会带来严重的数据倾斜问题。造成数据倾斜的主要原因在于分发到某个或某几个reducer的数据量远大于其他reducer的数据量。
对于group by造成的数据倾斜问题,我们可以通过设置参数
set hive.map.aggr=true (开启map端combiner);
set hive.groupby.skewindata=true;
这个参数的作用是做Reduce操作的时候,拿到的key并不是所有相同值给同一个Reduce,而是随机分发,然后Reduce做聚合,做完之后再做一轮MR,拿前面聚合过的数据再算结果。虽然多了一轮MR任务,但是可以有效的减少数据倾斜问题可能带来的危险。
正确的设置Hive参数可以在某种程度上避免的数据倾斜问题,合适的查询语句也可以避免数据倾斜问题。要尽早的过滤数据和裁剪数据,减少后续处理的数据量,使得join key的数据分布较为均匀,将空字段随机赋予值,这样既可以均匀分发倾斜的数据:
select userid,name from user_info a
join (
select case when userid is null then cast(rand(47)*100000 as int)
else userid
from user_read_log
) b on a.userid = b.userid
如果用户在定义schema的时候就已经预料到表数据可能会存在严重的数据倾斜问题,Hive自0.10.0引入了skew table的概念,如建表语句
CREATE TABLE user_read_log (userid int,bookid, …)
SKEWED BY (userid) ON (null) [STORED AS DIRECTORIES];
需要注意的是,skew table只是将倾斜特别严重的列的分开存储为不同的文件,每个制定的倾斜值制定为一个文件或者目录,因此在查询的时候可以通过过滤倾斜值来避免数据倾斜问题:
select userid,name from user_info a
join (
select userid from user_read_log where pt=’2015’ and userid is not null
) b on a.userid = b.userid
可以看出,如果不加过滤条件,倾斜问题还是会存在,通过对skew table加过滤条件的好处是避免了mapper的表扫描过滤操作。
3.3 Join的物理优化
Hive内部实现了MapJoinResolver(处理MapJoin)、SkewJoinResolver(处理倾斜join)、CommonJoinResolver
(处理普通Join)等类来实现join的查询物理优化(/org/apache/hadoop/hive/ql/optimizer/physical)。
CommonJoinResolver类负责将普通Join转换成MapJoin,Hive通过这个类来实现mapjoin的自动优化。对于表A和表B的join查询,会产生3个分支:
- 以表A作为大表进行Mapjoin;
- 以表A作为大表进行Mapjoin;
- Map-reduce join
由于不知道输入数据规模,因此编译时并不会决定走那个分支,而是在运行时判断走那个分支。需要注意的是要像完成上述自动转换,需要将hive.auto.convert.join.noconditionaltask设置为true(默认值),同时可以手工控制转载进内存的小表的大小(hive.auto.convert.join.noconditionaltask.size)。
MapJoinResolver 类负责迭代各个mr任务,检查每个任务是否存在map join操作,如果有,会将local map work转换成local map join work。
SkewJoinResolver类负责迭代有join操作的reducer任务,一旦单个reducer产生了倾斜,那么就会将倾斜值得数据写入hdfs,然后用一个新的map join的任务来处理倾斜值的计算。虽然多了一轮mr任务,但是由于采用的map join,效率也是很高的。良好的mr模式和执行流程总是至关重要的。
4. 窗口分析函数
Hive提供了丰富了数学统计函数,同时也提供了用户自定义函数的接口,用户可以自定义UDF、UDAF、UDTF Hive 0.11版本开始提供窗口和分析函数(Windowing and Analytics Functions),包括LEAD、LAG、FIRST_VALUE、LAST_VALUE、RANK、ROW_NUMBER、PERCENT_RANK、CUBE、ROLLUP等。
窗口函数是深受数据分析人员的喜爱,利用窗口函数可以方便的实现复杂的数据统计分析需求,oracle、db2、postgresql等数据库中也提供了window function的功能。窗口函数与聚合函数一样,都是对表子集的操作,从结果上看,区别在于窗口函数的结果不会聚合,原有的每行记录依然会存在。
窗口函数的典型分析应用包括:
- 按分区聚合(排序,top n问题)
- 行间计算(时间序列分析)
- 关联计算(购物篮分析)
我们以一个简单的行间计算的例子说明窗口函数的应用(关于其他函数的具体说明,请参考hive文档)。用户阅读行为的统计分析需要从点击书籍行为中归纳统计出来,用户在时间点T1点击了章节A,在时间点T2点击了章节B,在时间点T3点击了章节C 。用户浏览日志结构如下表所示。
| USER_ID | BOOK_ID | CHAPTER_ID | LOG_TIME |
| 1001 | 2001 | 40001 | 1443016010 |
| 1001 | 2001 | 40004 | 1443016012 |
| 1001 | 2001 | 40005 | 1443016310 |
通过对连续的用户点击日志分析,通过Hive提供的窗口分析函数可以计算出用户各章节的阅读时间。按照USER_ID、BOOKID构建窗口,并按照LOG_TIME排序,对窗口的每一条记录取相对下一条记录的LOG_TIME减去当前记录的LOG_TIME即为当前记录章节的阅读时间。
SELECT
Userid, bookid, chapterid, end_time – start_time as read_time
FROM
(
SELECT userid, bookid, chapterid, log_time as start_time,
lead(log_time,1,null) over(partition by userid, bookid order by log_time) as end_time
FROM user_read_log where pt=’2015–12–01’
) a;
通过上述查询既可以找出2015-12-01日所有用户对每一章节的阅读时间。感谢窗口函数,否则hive将束手无策。只能通过开发mr代码或者实现udaf来实现上述功能。
窗口分析函数关键在于定义的窗口数据集及其对窗口的操作,通过over(窗口定义语句)来定义窗口。日常分析和实际应用中,经常会有窗口分析应用的场景,例如基于分区的排序、集合、统计等复杂操作。例如我们需要统计每个用户阅读时间最多的3本书:

图:行间计算示意图及代码
对上述语句explain后的结果:

图:行间计算的执行计划
窗口函数使得Hive的具备了完整的数据分析功能,在实际的应用环境中,达观数据分析团队大量使用hive窗口分析函数来实现较为复杂的逻辑,提高开发和迭代效率。
5. 总结和展望
本文在介绍Hive的原理和架构的基础上,分享了达观团队在Hive上的部分使用经验。Hive仍然处在不断的发展之中,将HQL理解成Mapreduce程序、理解Hadoop的核心能力是更好的使用和优化Hive的根本。
技术的发展日新月异,随着spark的日益完善和流行,hive社区正考虑将spark作为hive的执行引擎之一。Spark是一种基于rdd(弹性数据集)的内存分布式并行处理框架,内部集成了Spark SQL模块来实现对结构化数据的SQL功能。相比于Hadoop将大量的中间结果写入HDFS,Spark避免了中间结果的持久化,速度更快且更有利于迭代计算。 达观数据团队也将紧跟技术发展潮流,结合自身的业务需求,采取合理的框架架构,提升系统的处理能力。(达观数据联合创始人 文辉)





6. 参考资料:
- Hive wiki:https://cwiki.apache.org/confluence/display/Hive/Home
- Hive Design Docs:https://cwiki.apache.org/confluence/display/Hive/DesignDocs
- Hadoop: The Definitive Guide (3rd Edition)
- Programming Hive
- Analytical Queries with Hive:http://www.slideshare.net/Hadoop_Summit/analytical-queries-with-hive




