
目前以理解人类语言为入口的认知智能成为了人工智能发展的突破点,而知识图谱则是迈向认知智能的关键要素。达观数据在2018AIIA人工智能开发者大会承办的语言认知智能与知识图谱公开课上,三位来自企业和学术领域的专家分别从不同角度讲述的知识图谱的应用和发展。文本根据达观数据副总裁王文广演讲内容《知识图谱与文本智能处理》整理所得,内容略有删减。

人们一些模糊词义的表达,比如:以前没有钱买华为,现在没有钱买华为。”这两句“没有钱”的意思很不一样,我们人理解这样的句子很容易,但对于计算机来说理解便很困难。
同一句话在不同场景下含义也很不一样,比如说从青岛开高速出来在车上谈“G20”是指高速有没有堵车,如果是北京或者是杭州谈G20有可能是高铁的票,在一些环境下G20也可能是20国集团峰会,这些表达的意思非常需要语境和背景知识的理解。计算机做文字阅读理解面临的挑战主要包括三个方面:
(1)缺乏常识体系
因为没有丰富的知识体系难以对文字背后的含义进行深入理解和推导
(2)缺乏领域的专家经验
人类的业务、法务、财务专家因为有行业知识,所以阅读文字后与知识对比后可以形成专业的见解
(3)模糊、歧义、抽象会增加困难
语言中模糊不清的现象比比皆是,需结合语境去理解
知识图谱是其中一个为解决问题提出来的方法——我们可以把人类的各种知识以知识图谱的形式沉淀下来,让计算机利用这个知识图谱理解更加复杂的含义。
知识图谱本身是从语义网发展出来的,也是谷歌提出来的概念,知识图谱的构建也是现在AI领域里面的非常大的难点,这是因为不仅涉及到AI领域各方面的技术,还包括人类各种领域的知识所形成的专家系统。
构建高质量的不断演化知识图谱也是AI领域的难点之一,因为知识图谱本身研究的意义就是可以为语言提供更多的背景知识,让计算机更好的读写文字。基本现状像谷歌、百度、搜狗都有大量的通用知识图谱,还有垂直领域的医疗或者是金融领域的知识图谱的广泛应用也很多,如何结合业务场景使用好知识图谱是落地的根本要素。
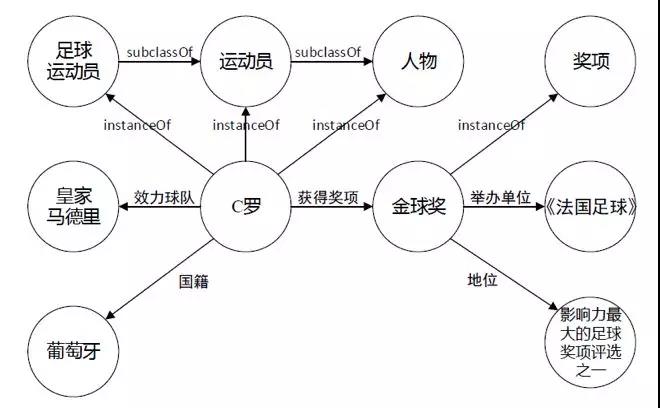
知识图谱本质上是一种语义网络,将客观的经验沉淀在巨大的网络中,结点代表实体(entity)或者概念(concept),边(edge)代表实体/概念之间的语义关系,成熟的图数据库如neo4j,Dgraph,JanusGraph等可以用来存储知识图谱。
知识图谱更加广泛的被认知的是一个三元组的表示形式。就是有三个值,第一个表示第一个实体,第二个值表示第二个实体,中间值是两者之间的关系。三元组本身基于三元组的语义网发展起来,有RDF的检索语言,还有基于RDF的存储的开源的方式,都是很方便使用方式。
深度学习的发展促使知识的表示从三元组迈向稠密向量表示,从Word2Vec到对三元组的表示学习,稠密向量,实体等本身可以用Word2Vec等进行表示学习,例如 Vector(山东省) – Vector(威海市) = Vector(广东省) – Vector(佛山市) ,对于三元组的表示学习,有各类深度学习算法,如TransE、TransH、TransR、TransG、KBGAN、等。
知识图谱上的应用非常多,比如推荐系统可以用上知识图谱来实现更加智能的推荐,除此之外,知识问答、文档审核等也是知识图谱常见的应用场景。
一般来讲会把知识图谱分成通用和行业的知识图谱,通用型的就是刚刚提过像谷歌,构建知识图谱就是一个面向全领域,没有一些特别的偏好,国内有百度或者是搜狗的知识图谱,还有一些是开放式的像wikidata 以及中文openKG等。
行业垂直型知识图谱是面向某一特定领域,如金融、法律、财会、教育等,以专家知识为主,通过结合业务场景,基于行业数据构建,打造“语义层面的行业知识库”,通常也更加专业。
比如向百度或者是搜狗搜一些人名地名会以卡片的形式展现出来,这个是知识图谱的现实的应用。金融领域会用知识图谱分析借贷关系或者是企业的信贷状况等,这是非常强的应用场景。
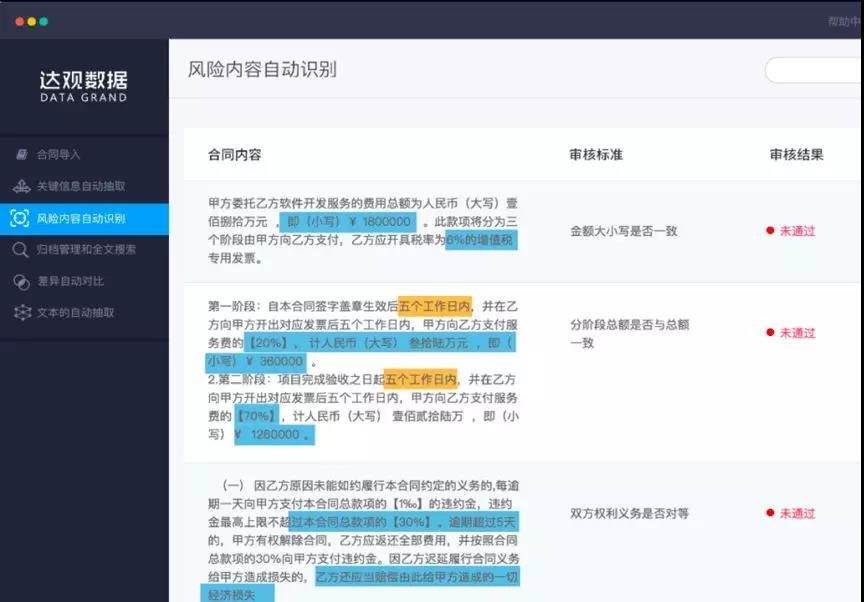
目前达观达观构建一些企业信息法律类的知识图谱用来帮助我们的文档智能审阅系统更好的审核合同或者是专业文本,像财报或者是上交所的公告等。
知识图谱有这么多好处,我们怎么去构建一个知识图谱?简单来说,构建知识图谱其实是一个系统性的工程,不是单一的算法能够完成。
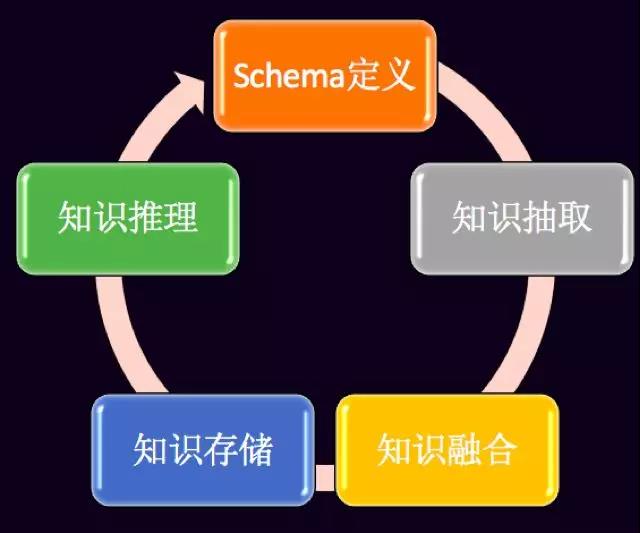
另外对于知识图谱来说非常重要的一点是反馈机制,我们怎么样利用反馈系统不断地让知识图谱进行进化?这个在构建知识图谱的过程当中非常需要考虑的问题。此外,工程上详细的logging和报表系统以在需要的时候进行分析和纠正。
分层次的领域模式(Schema)非常重要
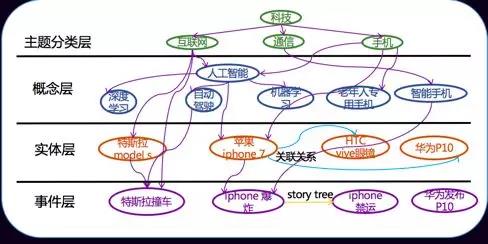
schema的构造是层级的方式,专业领域是先按照专家经验构造出一个知识图谱的schema,然后在实践过程当中不断完善,像通用的谷歌或者是百度他们自上而下利用类算法抽取知识图谱,然后归类到已经有的schema,如果归类不到就想方设法生成新的schema的模式匹配它。
在这里面知识图谱构建过程当中,除了schema之外就是往图谱里填内容,这个过程就是知识抽取,本身是包括了实体抽取和关系抽取,还有属性抽取这几个概念,在实践过程当中,其实不完全是像在论文里面看到的各种抽取,有可能是从结构化数据库里面按照某一种专业的规则直接转化,因为很多的知识其实已经存储在各个企业里面关系数据库里面。这种情况下可能是用了简单的规则就转化成知识图谱的一部分的内容。
另外一部分是半结构数据,维基百科很多的标签是已经存在在里面的,还有国家企业信息公示网的各种实体公司名或者是企业法人都是以半结构化存在,这个用模板匹配就可以完成了。
这里面简单的就总结了刚刚提到的点,在不同的背景下可能选择不同的知识抽取的算法可以更好的去帮助我们构建一个完整的知识图谱。

这是一个像BiLSTM-CRF用于命名实体识别常用的办法,帮助我们识别非结构化文本,比如说书籍或者是合同或者是新闻里面的实体。
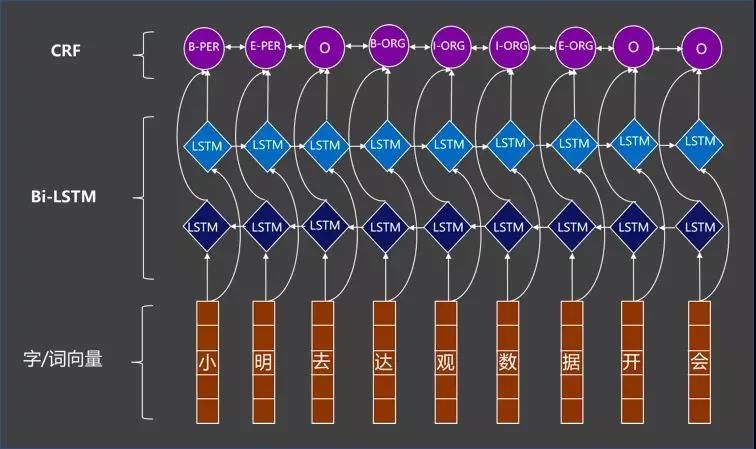
Bi-LSTM双向网络分别从前往后和从后往前进行序列信号的记忆和传递是常见做法,CRF等经典方法结果可控性好,在序列标注时,在顶层用CRF对Bi-LSTM的结果进行二次操作可得到更好的结果。
除了刚刚提到的知识抽取之外,其实抽取完之后在不同的地方表现方法和表达方式不一样,在不同来源的知识里面如何融合成一个相同的?这个是我们需要考虑的点,这里有几个例子:比如说苏东坡在不同的地方会被提到,而且有不同的名字,可能是历书里面有东坡学士这样的说法,还有苏轼的叫法。
另外这些不仅仅存在中国,因为多元跨国之间的交流也导致很大的问题,比如说后面的例子是美国总统特朗普,中文的官方名称是特朗普,大家还有称他为川普,还有其他的语言西班牙或者是土耳其语。在多元的环境下如何进行知识图谱?其实对知识图谱构建是非常大的挑战。
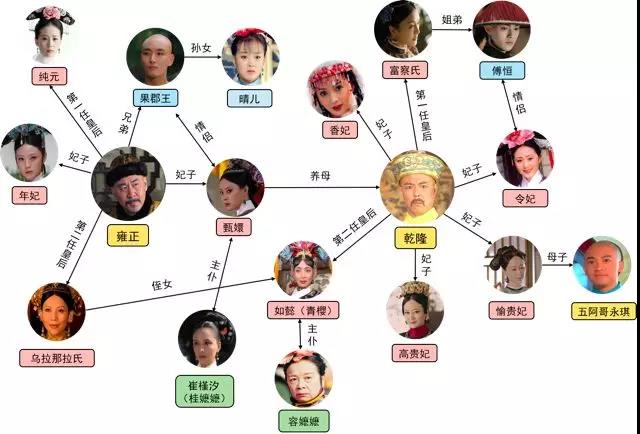
这是一个网络上的例子,来自于几个不同的影视剧或者是小说,里面的部分人是同一个人,但是不同的小说可能有不同的名字或是不同影视剧里面的主角,这样如果做成一个知识图谱如何归结好?利用各种影视剧小说里面的内容进行推理,其实是多元知识融合里面非常通俗易懂的例子。这个是人工整理,人有专业的知识非常好做,但是耗费了大量的人力,不能把各种知识都做很好的融合,所以我们需要发掘更多算法去实现这个目标。
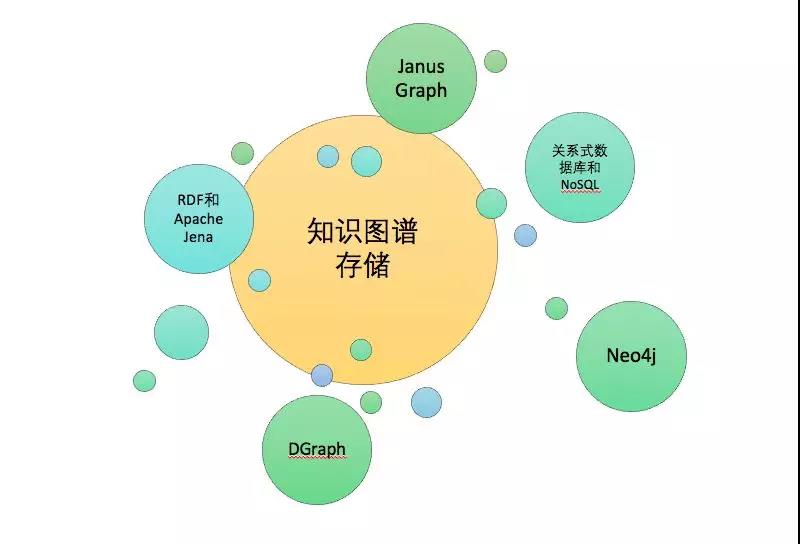
除了刚刚提到的抽取和融合之外,对于知识图谱的存储其实也是非常大的挑战。大一点的通用的知识图谱都是几十亿甚至上百亿的节点,可能百亿千亿级别的关系,如何做好存储系统是极其需要考虑的点,下图总结目前常见的几种存储类型,像RDF和ApacheJena以三元组的形式表现的,NoSQL也可以存储,但是如果量大会很吃力,开源的Neo4j是单机的,DGraph正在发展,按照官方的说法支持千亿级别的,但是现在还没有达到,但亿级别是完全没有问题的。
下图一个JanusGraph,有如下几个特点:
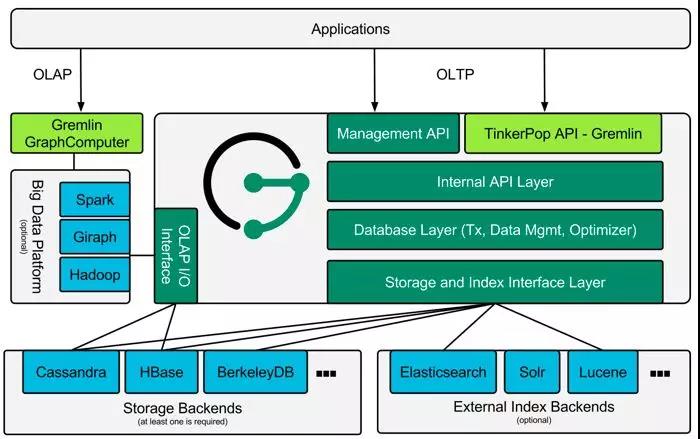
- 十亿以上的节点和边
- C* 或 Hbase等
- 与Spark无缝集成
- 支持使用ElasticSearch进行高效检索
- 最终一致性
- 支持Gremlin语言进行在线分析
- 开源
除了以上这些点,如果构建好了知识图谱,要对知识进行推理和评估,知识推理本身可以补充知识图谱的内容,或者是进行完善或者是较验。对于知识图谱大部分还是需要人工的参与。
Path Ranking Algorithm(PRA)算法和DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning,这两个是知识推理的前沿进展,有兴趣可以去看一下。
总之,从合适的业务场景出发是成功构建和使用行业知识图谱的关键。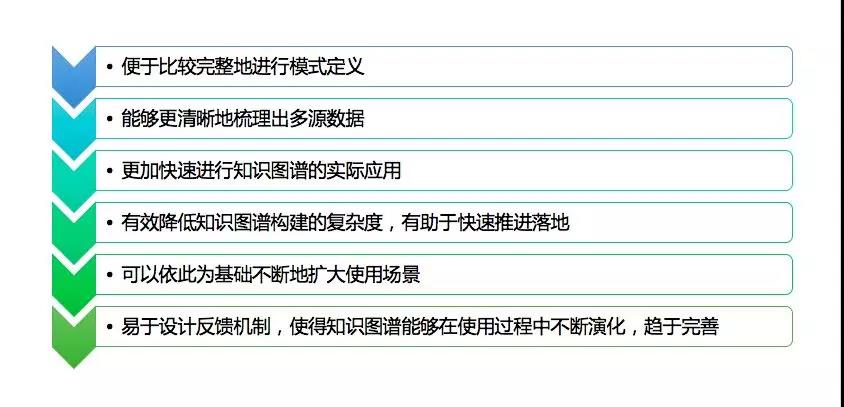
知识图谱的作用是衔接企业的数据和业务需求。
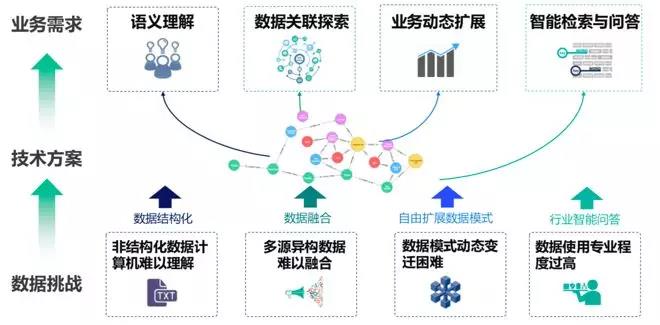
对于企业来说,是把原有的分散的数据变成集中化的管理。可能是遇到比较大的集团企业他的传统的数据是分散的,不同的部门和公司之间,这部分的知识是没有被更好的利用起来。如何利用好这些数据?更好的支持业务,让整个业务更高效的运行?其实是整个企业在做知识图谱需要考虑的一个点。
对于我们来说他的难点就是在于因为本身的数据非常的分散,不同的数据结构表示不一样,存在不同的地方有不同的表达方式,如何做好这部分融合的工作其实是很大的难点。
知识图谱的应用场景可以是简单的利用,即直接用知识图谱的分析,下图比是早的阿里巴巴的分析图,当时发生了一个事件马云把支付宝私有化,当时他们画了一个阿里巴巴的股权结构图,像这种股权分析在金融领域里面是非常直接的知识图谱的应用。
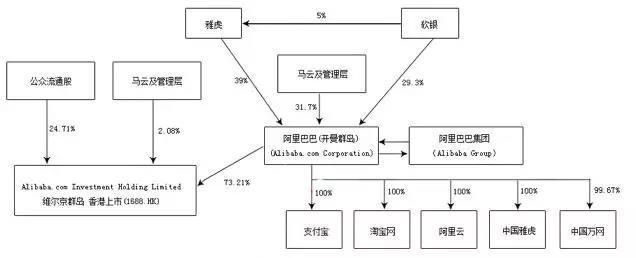
除此之外,信贷分析也是经典的应用场景,直接用知识图谱或者是知识推理进行分析,生成相应的报告或者得出一些结论,这个是最直接的应用场景。
第二是利用知识图谱做一些舆情分析热点分析,把知识图谱和其他的结合起来使用。

达观擅长的VOC用户评论分析,会涉及到用户评论归类到哪一个实体里面,比如说一个企业会抓他的所有的评论和微博数据,会归纳到具体的品牌和产品上,甚至是归到产品的某些类别中。比如说手机,有不同的品牌,每个品牌下面有不同的型号,每个型号下有不同的版本,手机本身有不同的零件——屏幕或者是相机之类。每个评论过来之后其实针对的是某一个具体手机的型号,在这个型号里面有可能是针对整机进行评价,有可能是针对整机里面的部件。那么我们需要做的更好的分析就是可以利用像手机这种类似的知识图谱对它进行更深入的分析。
招聘也是达观目前在做的,有企业在用,可以对候选人和职位构建出图谱进行分析,更好的理解这个职位需要招什么人?也可以更好的了解候选人适合哪一个职位。
此外,基于知识图谱实现更加智能的搜索。基于知识图谱的检索最早用在搜索引擎上面,搜索利用这些之后可以更好的理解用户的意图,达到更好的效果。
推荐系统也可以用知识图谱,这个是达观在做的,达观的推荐系统在业界比较领先,知识图谱可以针对不同的场景或者是不同的类型还有不同的领域推荐。推荐中最重要的一点是冷启动问题,如果完全没有数据的系统或者是刚构建的系统,想达到好的推荐效果比较难,利用知识图谱里面的内容能更好的在冷启动的环境下达到更好的效果。如何利用深度学习把知识图谱用在推荐系统上,也是达观数据在研究的内容。
构建知识图谱之上的问答系统是最直接的,知识问答是你需要了解用户问的问题是什么意思?然后给他一个最直接的答案。知识问答除了像各种搜索引擎,这个里面的例子有几个,一个是问范冰冰的男友是谁,百度就直接给出一个卡片。

前面就是一些通用场景下的应用场景,下面讲讲达观数据对知识图谱的的一些应用。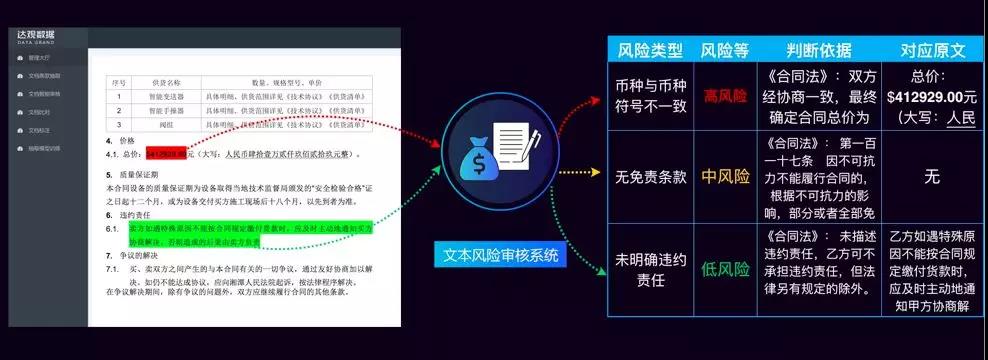
这个场景是合同审阅,自动化的帮企业审阅各种合同文本和公告,合同需要符合合同法规定的,以及企业内部的法务部门对合同有一些要求,以及本身合同是一个非常规范的文本,不允许有错别字等。
达观文档智能审阅系统能利用知识图谱里面包括对法律文本的语义化的图谱应用,自动完成审阅。以及对企业信息可以从工商信息网的信息里面可以做一些较验。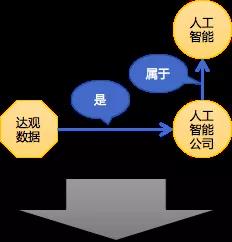
推荐系统刚刚提到过,推荐系统里面应用到知识图谱,这个是简单的例子,比如说达观数据和人工智能公司,是属于人工智能的一个领域,如果一个用户对人工智能感兴趣,对达观相关的信息就感兴趣,比如说达观的融资信息,这个对人工智能来说是一个比较有用的新闻,可以判断这个领域是不是繁荣?估值是不是上涨了还是下降了?
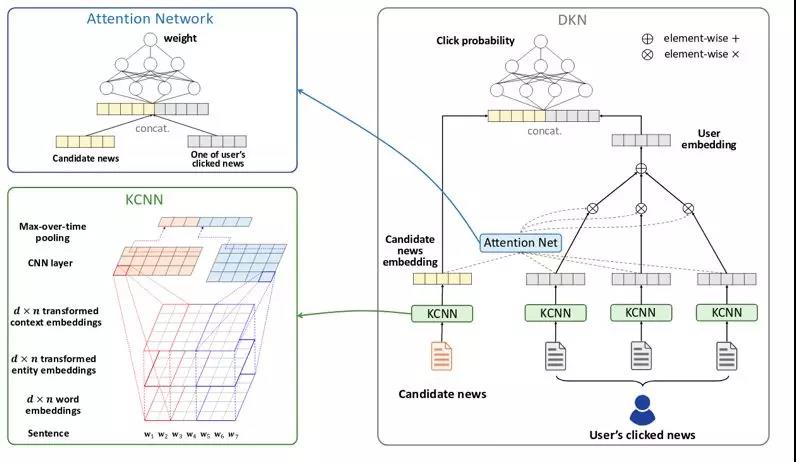
上图是达观用深度学习的方式把知识图谱的三元组表示应用到协同过滤和推荐相关的领域。
前面简单的介绍了整个知识图谱的相关的内容,最后做一些总结。
1.构建知识图谱本身是非常系统性的工程,包括计算机的方方面面还有实践过程,以及企业真实应用场景中包括对企业的不断的沟通,不同部门之间整合的过程
2.整个知识图谱的构建没有”银弹”,没有一个统一或者是完美的方法搞定一个事情,在做事情的过程当中需要因时因地制宜的实现
3.知识图谱的构建能有效提升文本智能处理的效果
4.知识图谱可能是走向认知智能的关键要素
5.知识图谱需要结合应用场景做分析落地,落地之后还要不断的优化总结来提升整个效果
BOUT
关于嘉宾
王文广,达观数据副总裁,在人工智能领域和系统架构设计上有十余年工作经验,浙江大学计算机硕士。曾担任金融AI公司Kavout首席架构师,将人工智能(AI)和自然语言处理(NLP)技术应用于金融、证券、量化交易等领域,效果得到美国大型基金公司认可。
曾负责盛大创新院搜索、推荐、广告等多个项目的架构设计工作,所设计和开发的系统具备海量数据的快速处理和高度智能的挖掘能力,多次获得嘉奖。早期在百度负责MP3搜索、语音识别与搜索和音频指纹等系统的核心研发。




