
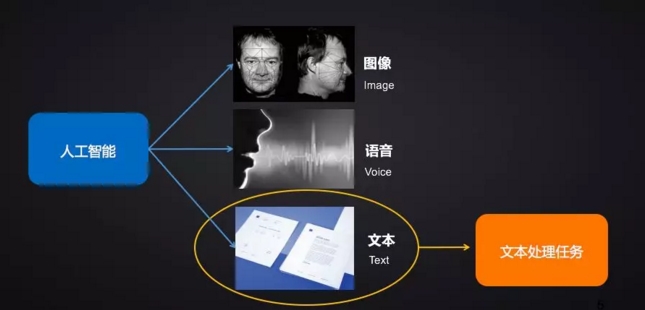
人工智能目前的三个主要细分领域为图像、语音和文本,达观数据所专注的是文本智能处理领域。文本智能处理,亦即自然语言处理,试图让机器来理解人类的语言,而语言是人类认知发展过程中产生的高层次抽象实体,不像图像、语音可以直接转化为计算机可理解的对象,它的主要应用主要是在智能问答,机器翻译,文本分类,文本摘要,标签提取,情感分析,主题模型等等方面。
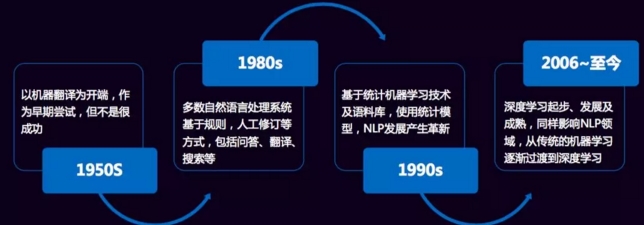
自然语言的发展历程经历了以下几个阶段。这里值得一提的是,关于语言模型,早在2000年,百度IDL的徐伟博士提出了使用神经网络来训练二元语言模型,随后Bengio等人在2001年发表在NIPS上的文章《A Neural Probabilistic Language Model》,正式提出神经网络语言模型(NNLM),在训练模型的过程中也能得到词向量。2007年,Mnih和Hinton在神经网络语言模型(NNLM)的基础上提出了log双线性语言模型(Log-Bilinear Language Model,LBL),同时,Hinton在2007年发表在 ICML 上的《Three new graphical models for statistical language modelling》初见其将深度学习搬入NLP的决心。
2008年,Ronan Collobert等人 在ICML 上发表了《A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning》,其中的模型名字叫C&W模型,这是第一个直接以生成词向量为目标的模型。LBL与NNLM的区别正如它们的名字所示,LBL的模型结构是一个log双线性结构;而NNLM的模型结构为神经网络结构。这些积淀也成就了Mikolov创造了实用高效的Word2Vec工具,起初,他用循环神经网络RNNLM来做语言模型,发表paper《Recurrent neural network based language model》,之后就是各种改进,博士论文研究的也是用循环神经网络来做语言模型,《Statistical Language Models based on Neural Networks》。
2013年,Mikolov等人同时提出了CBOW和Skip-gram模型。使用了Hierarchial Softmax和Negative Sampling两种trick来高效获取词向量。当然这个模型不是一蹴而就的,而是对于前人在NNLM、RNNLM和C&W模型上的经验,简化现有模型,保留核心部分而得到的。同时开源了Word2Vec词向量生成工具,深度学习才在NLP领域遍地开花结果。
文本数据经过清洗、分词等预处理之后,传统方法通过提取诸如词频、TF-IDF、互信息、信息增益等特征形成高维稀疏的特征集合,而现在则基本对词进行embedding形成低维稠密的词向量,作为深度学习模型的输入,这样的框架可用于文本分析、情感分析、机器翻译等等应用场景,直接端到端的解决问题,也无需大量的特征工程,无监督训练词向量作为输入可带来效果的极大提升。
文本分类
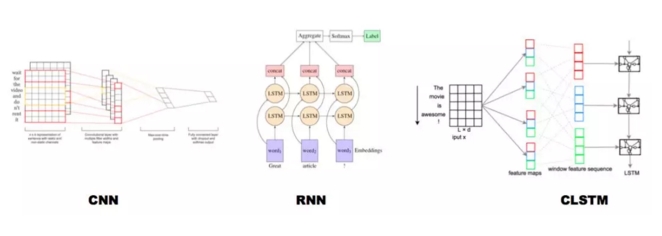
对于文本分类,以下列出了几种典型的深度学习模型:
序列标注
序列标注的任务就是给每个汉字打上一个标签,对于分词任务来说,我们可以定义标签集合为:。B代表这个汉字是词汇的开始字符,M代表这个汉字是词汇的中间字符,E代表这个汉字是词汇的结束字符,而S代表单字词。下图为中文分词序列标注过程:
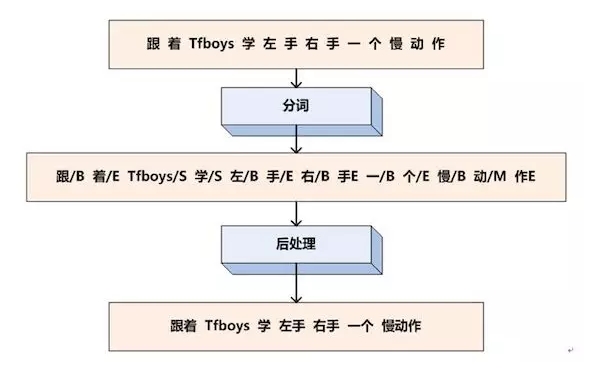
中文分词转换为对汉字的序列标注问题,假设我们已经训练好了序列标注模型,那么分别给每个汉字打上标签集合中的某个标签,这就算是分词结束了,因为这种形式不方便人来查看,所以可以增加一个后处理步骤,把B开头,后面跟着M的汉字拼接在一起,直到碰见E标签为止,这样就等于分出了一个单词,而打上S标签的汉字就可以看做是一个单字词。于是我们的例子就通过序列标注,被分词成如下形式:{跟着 Tfboys 学 左手 右手 一个 慢动作}
对于序列标注,传统的方法基本是使用大量的特征工程,进入CRF模型,但不同的领域需要进行相应的调整,无法做到通用。而深度学习模型,例如Bi-LSTM+CRF则避免了这样的情况,可以通用于不同的领域,且直接采用词向量作为输入,提高了泛化能力,使用LSTM和GRU等循环神经网络还可以学习到一些较远的上下文特征和一些非线性特征。
经典的Bi-LSTM+CRF模型如下所示:

生成式摘要
对于生成式摘要,采用Encode-Decoder模型结构,两者都为神经网络结构,输入原文经过编码器编码为向量,解码器从向量中提取关键信息,组合成生成式摘要。当然,还会在解码器中引入注意力机制,以解决在长序列摘要的生成时,个别字词重复出现的问题。
此外,在生成式摘要中,采用强化学习与深度学习相结合的学习方式,通过最优化词的联合概率分布,即MLE(最大似然),有监督进行学习,在这里生成候选的摘要集。模型图中的ROUGE指标评价是不可导的,所以无法采用梯度下降的方式训练,这样我们就考虑强化学习,鼓励reward高的模型,通过给予反馈来更新模型。最终训练得到表现最好的模型。
知识图谱关系抽取
对于知识图谱的关系抽取,主要有两种方法:一个是基于参数共享的方法,对于输入句子通过共用的 word embedding 层,然后接双向的 LSTM 层来对输入进行编码。然后分别使用一个 LSTM 来进行命名实体识别 (NER)和一个 CNN 来进行关系分类(RC);另一个是基于联合标注的方法,把原来涉及到序列标注任务和分类任务的关系抽取完全变成了一个序列标注问题。然后通过一个端对端的神经网络模型直接得到关系实体三元组。
我们有三类标签,分别是:
①单词在实体中的位置{B(begin),I(inside),E(end),S(single)}②关系类型{CF,CP,…}③关系角色{1(entity1),2(entity2)}根据标签序列,将同样关系类型的实体合并成一个三元组作为最后的结果,如果一个句子包含一个以上同一类型的关系,那么就采用就近原则来进行配对。




