
本文由达观数据算法工程师范雄雄根据斯坦福计算机博士Danqi Chenhe和Facebook AI研究院Adam Fisch, Jason Weston 以及 Antoine Bordes撰写的文章编译而成,详细讲解了维基百科的开放性问答系统的原理,原文详见:《ReadingWikipedia to Answer Open-Domain Questions》
本文提出以Wikipedia作为唯一的知识源来解决开放领域的问答:任何事实型问题的答案都是在Wikipedia文章中的一段文本。这项海量机器阅读的任务,需要同时面对2个挑战,一是文本检索(找到相关的文章),二是对文本的理解(从文章中识别答案的范围)。我们的方法结合使用了基于bigram hashing以及tf-idf匹配检索模块以及用于在Wikipedia段落中挖掘答案的多层RNN模型。我们在多个已有的QA 数据集的实验表明:
1)相比以往的方法,这两个模块都是非常有竞争力的;
2)在这项具有挑战性任务中,使用distant supervision对他们的联系进行多任务学习是非常有效完整的办法。
本文考虑的问题是如何使用Wikipedia作为唯一知识源回答开放领域的事实型问题,就像人们在百科全书中寻找答案一样。Wikipedia是一个持续不断发展并且包括各种详细信息的知识源,如果可以善加利用,可以很好的促进机器的智能。跟知识库(便于计算机处理,但是对开放领域的问答系统来说,太过稀疏,比如Freebase和DB-Pedia)不同的是,Wikipedia包括人们关心的最新的知识,并且是为人类的阅读(而不是为机器)设计的。
采用Wikipedia的文章作为知识源来做问答(QA),需要同时解决2个挑战:一个是大规模开放领域的问答,一个是机器对文本的理解。
为了能够回答任何问题,系统首先要从500万篇文章中找到少量相关的文章,然后仔细的扫描这几篇文章来找到答案。我们把这个定义为machine reading at scale(MRS)。我们的工作把Wikipedia视为文章的集合,而不考虑他们内在的图结构。这样,我们的方法可以更加通用化,可以用于一系列书、文档甚至是每天更新的报纸新闻。
像IBM的DeepQA这样大规模的问答系统,它的回答依赖于各种不同的知识源:除了Wikipedia,还用到KBs,字典甚至新的文章以及书等等。因此,系统回答的正确性严重依赖于在多个知识源中的信息冗余。只有一个知识源的条件下,迫使我们模型在扫描文章的时候,需要非常的精确仔细,因为有些答案的线索可能只出现一次。这样的挑战,也因此推动了机器阅读能力(机器理解的子领域)的研究以及诸如SQuAD、CNN/Daily Mail、CBT这样的数据集的建立。
然而,这些数据集都是假设已经有一小段的相关文本已经提供给模型了,这在构建开放领域的问题系统中是不现实的。与此形成鲜明对比的是,基于知识库或者在文档中采用信息检索的方法,必须将搜索的结果作为解法的一部分。而MRS是在海量开放知识源中检索的现实条件(并没有作非常理想化的假设)下来做机器理解(需要对文本的深度理解)。
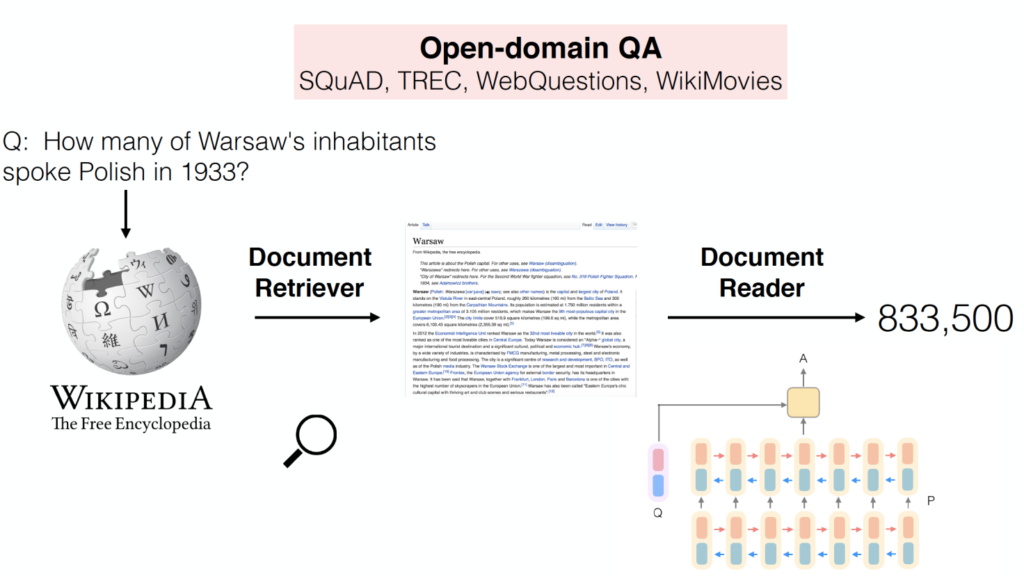
在本文中,我们会展示如何使用多个现有的QA数据集来评估MRS(通过开放领域的系统在全部已有的QA数据集上回答问题)。我们开发了DrQA系统,它基于Wikipedia的强大的QA系统,其组成包括:(2)Document Reader,基于多层RNN的机器理解模型,用于挖掘Document Retriever的文章小集合中的答案范围。图1给出了DrQA系统的图示。
(1)Document Retriever,采用bigram hashing以及tf-idf匹配实现,该模块主要用于给定一个question之后,快速找到相关的文章的一个小集合;
(2)Document Reader,基于多层RNN的机器理解模型,用于挖掘Document Retriever的文章小集合中的答案范围。图1给出了DrQA系统的图示。
我们的实验表明,Document Retriever比Wikipedia内置的搜索引擎效果好,Document Reader可以达到目前最好的SQuAD水准。最后,我们整个系统是用多个benchmark来评估的。特别是,相比于单任务的训练,采用多任务以及distant supervision方法,其表现在所有数据集上都有所提高。
图一
根据每年举行的TREC比赛的设定,开放领域的QA最开始是被定义为在非结构化文档中寻找答案。随着KB的发展(比如WebQuestions,SimpleQuestions,又比如自动抽取的KBs,OpenIE triples 和 NELL),最近基于KB的QA有了许多新的改进。然而,KB固有的局限(不够完整以及固定的数据格式)促使研究人员回归到最初的设定,即从原始数据中去寻找答案。
重新审视这个问题的第二个动机,是因为随着最近新的深度学习框架的出现(比如attention-based and memory-augmented neural networks以及新的训练评测数据集的开放,这些数据集包括QuizBowl,包含新闻文章的CNN/Daily Mail,包含儿童书的CBT以及基于Wikipedia的WikiReading和SQuAD),机器的文本阅读理解(比如通过阅读一小段文本或者故事来回答问题)有了长足的进步。本文的目的是想测试下这些新方法在开放领域的QA中表现如何。
采用Wikipedia作为知识源的QA之前已经有过尝试。Ryu et al. (2014) 实验过只采用Wikipedia的模型,他们将文章内容和其他多个基于不同类型的半结构化知识(比如信息框,文章结构,类别结构,定义等)实现的答案匹配模块结合在一起使用。类似的,Ahn et al. (2004) 将Wikipedia和其他的文档一起检索来使用。Buscaldi and Rosso (2006)也尝试在Wikipedia中挖掘知识。他们没有将其作为寻找问题答案的知识源,而是用它来验证QA返回的结果的正确性。并使用Wikipedia分类来确定一组符合预期答案的模式。在我们的工作中,我们只考虑文本的理解,并且只用了Wikipedia作为唯一的知识源,以便将重点放在大规模的阅读理解上。
许多发展多年的完整的QA处理方法流不是用Web数据(QuASE),就是用Wikipedia的数据(Microsoft的AskMSR,IBM的 DeepQA,YodaQA),后者是开源,因此可以复现用于比较效果。AskMSR是一个基于搜索引擎的QA系统,它依赖于“数据冗余而不是对问题或候选答案进行复杂的语言学分析”,也就是说,它不像我们一样专注于机器理解。DeepQA是一个非常复杂的系统,它依赖于包括文本文档在内的非结构化信息以及诸如KB,数据库和本体的结构化数据来生成候选答案或对证据进行投票。YodaQA是以DeepQA为蓝本的开源系统,同样结合使用网站、信息提取、数据库和Wikipedia。相比于这些方法,我们的阅读理解由于使用的是单个知识源,因此更具挑战性。
在机器学习以及NLP中,多任务学习以及任务迁移有着丰富的历史。有些工作试图通过多任务学习将多个QA训练集合并到一起,这样,
(1)通过task transfer实现跨数据集的提升;
(2)提供一个通用的系统,可以回答不同类型的问题,因为答案不可避免的分布在不同的数据集上。
Fader et al. (2014)用WebQuestions、TREC和WikiAnswers作为评测,以四个知识库作为知识来源,通过多任务学习在后两个数据集上获得了提升。Bordes et al. (2015)以Freebase作为知识源采用 distant supervision合并了WebQuestions和SimpleQuestions,结果显示在两个数据集上都是略微提升,但是只采用一个训练,另一个作为测试的话,结果却很差,这说明task transfer确实是非常有挑战性的任务。(Kadlec et al., 2016)也得到类似的结论。我们的工作也是类似的想法,不过做了特别的限制,必须先检索,再理解,而不是用KB直接取一个好的结果。
下面我们将介绍Facebook的系统DrQA,主要由两部分组成:
(1)Document Retriever模块,用于找到相关的文章
(2)Document Reader模块,机器理解模型,用于从单个或小集合的,文档中抽取答案
Document Retriever
参考传统的QA系统,我们采用非机器学习的文本检索系统来缩小我们的检索范围,然后把注意力集中在这些可能相关的文章阅读理解来寻找答案。相比于内置的基于ElasticSearch的Wikipedia Search API,简单的倒排查询结合term vector model打分的效果在很多类型的问题上的效果要更好。文章和问题通过tf-idf作为权重的bag-of-word向量来衡量相关性。后来我们通过加入n-gram特征,把小范围的词序考虑进来,进一步改进系统。我们最好的系统是用bigram计数以及(Weinberger et al., 2009)提出的哈希方法(用murmur3 hash将bigram映射到224个bin中),同时保留了速度和内存的效率。
我们采用Document Retriever作为整个系统的第一部分,对任何问题,设定返回5篇Wikipedia的文章。这些文章在后续的Document Reader进行处理。
Document Reader
我们的Document Reader是受最近神经网络模型在机器阅读理解方面的优异表现而启发,其思想跟(Hermann et al., 2015;Chen et al., 2016)提出的AttentiveReader是非常相似的。
给定一个含有l个token的问题 ![]()
和包含n个段落的文档集合,其中单个段落 p 包含m个token,
![]() 我们开发了一个RNN模型,然后依次应用到每个段落上,最后聚合所有的预测结果。我们的方法是这样工作的:
我们开发了一个RNN模型,然后依次应用到每个段落上,最后聚合所有的预测结果。我们的方法是这样工作的:
段落编码
首先我们把段落中的所有token pi 表示成特征向量序列![]()
然后作为RNN的输入,得到如下表示: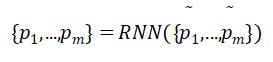 其中,pi希望是可以将token pi的上下文信息编码进去。我们采用多层双向LSTM,然后在每层的隐藏单元最后串联pi
其中,pi希望是可以将token pi的上下文信息编码进去。我们采用多层双向LSTM,然后在每层的隐藏单元最后串联pi
特征向量![]() 包含以下几部分:
包含以下几部分:
![]()
我们用840B网上爬来数据训练得到300维的Glove word embedding。大部分的训练完的word embedding保持不变,仅仅对最常用的1000个问题中包含的词进行优化,因为像what,how,which,many等这些词对QA系统来说非常重要。
完全匹配: ![]()
我们用3个简单的二值特征,表示段落中的pi是否可以完全匹配question中的某个词q,不管是原始,小写或者lemma形式,这些简单的特征在实验中效果非常显著,在第五部分将会看到。
Token特征:
![]()
我们也增加了一些人工的特征,这些特征能够反映token的一些上下文信息,包括词性,命名实体名以及词频。
Aligned question embedding:
参考(Lee et al., 2016)以及其他最近的工作,最后一部分加入的是aligned question embedding:
![]()
![]()
特别的,![]() 的计算方式是word embedding的非线性映射的点乘:
的计算方式是word embedding的非线性映射的点乘:
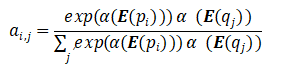
![]() 是一个ReLU非线性的单稠密层。跟完全匹配的特征相比,这些特征给意思相似但不同的词加入了平滑的对齐。
是一个ReLU非线性的单稠密层。跟完全匹配的特征相比,这些特征给意思相似但不同的词加入了平滑的对齐。
问题编码
问题的encoding简单很多,我们只需要在所有词向量![]() 上应用RNN,然后把隐层单元合并到一个向量中去:
上应用RNN,然后把隐层单元合并到一个向量中去:![]() ,q的具体计算为
,q的具体计算为![]() ,其中
,其中![]() 编码了每个词的重要性信息,我们用如下方式计算q:
编码了每个词的重要性信息,我们用如下方式计算q: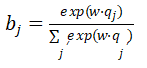
其中,w是需要学习的权重向量。
预测
在段落层面,我们的目标是预测哪些范围里面的词很有可能是答案。以段落向量![]() 以及问题q作为输入,简单的训练2个独立的分类器来预测范围的两端。具体做法是,我们用双线性项来捕捉
以及问题q作为输入,简单的训练2个独立的分类器来预测范围的两端。具体做法是,我们用双线性项来捕捉![]() 和q的相似度并且计算每个词作为开始和结束的可能性:为了使打分可以兼容多个检索文档的段落,我们采用非归一化的指数,然后在所有候选段落里拿使分数最大的token范围。
和q的相似度并且计算每个词作为开始和结束的可能性:为了使打分可以兼容多个检索文档的段落,我们采用非归一化的指数,然后在所有候选段落里拿使分数最大的token范围。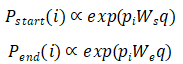

为了使打分可以兼容多个检索文档的段落,我们采用非归一化的指数,然后在所有候选段落里拿使分数最大的token范围。
我们的工作依赖于三种类型的数据:
(1)Wikipedia作为寻找答案的知识源。
(2)SQuAD数据集,作为训练Document Reader的主要数据源
(3)除了SQuAD之外,还用了CuratedTREC, WebQuestions和WikiMovies三个数据集来测试我们整个问答系统的能力,以及评估我们模型对于多任务学习以及distant supervision的学习能力。数据集的统计数据见后面的表2。
Wikipedia
我们用的是2016-12-21版的Wikipedia全量英文数据作为回答问题的知识源。对每一页,我们仅抽取纯文本,列表以及图片信息会被过滤掉。在丢弃了了内部消歧、列表、索引和概要页面之后,我们保留了5,075,182篇文章,包含9,008,962个独特的未定义的token类型。
SQuAD
SQuAD(The Stanford Question Answering Dataset)是一个基于Wikipedia的用于机器阅读理解的数据集。该数据集包含87000个训练样例以及10000个开发样例。每个样例包括从一篇Wikipedia文章中抽取的段落以及相关的人为编写的问题。答案永远是在段落中的某一部分,如果模型预测的答案匹配上了,就会给予肯定。目前用了2个评估指标:EM(字符完全匹配)和F1 score,衡量了token级别的加权平均后的准确和召回率。
接下来,在给定的相关段落中,(相关段落的定义可以参考Rajpurkar et al.,2016),我们用SQuAD来训练以及评估我们的Document Reader。对于基于Wikipedia的开放领域的问题,我们只用SQuAD数据集的开发集合中的QA对,我们要求系统在没有相关段落的情况下找到正确答案的范围,也就是模型的查找范围是整个Wikipedia,而不是标准SQuAD数据集中的相关段落。
开放领域QA的评测资源
SQuAD是目前最大的通用QA数据集。SQuAD的问题收集过程是通过给人展现一个段落,然后人工编写的。这样这些问题的分布是非常特殊的。因此,我们计划在其他数据集上来训练和评估我们开放域的QA系统,这些数据集可以是不同的方式构建的(不一定是从维基百科寻找回答)。
CuratedTREC
这个数据集是TREC QA任务中,Baudiˇs and ˇ Sediv`y (2015)定下的benchmark收集的。我们用的大的版本,包含从TREC1999, 2000, 2001 and 2002中抽取的2180个问题。
WebQuestions
在(Berant et al.,2013)有介绍。这个数据集是用于Freebase作为知识源来回答问题。它是用Google suggest API来爬取问题,然后用Amazon Mechanical Turk来回答问题。我们使用实体名称将每个答案转换为文本,以便数据集不需要引用Freebase ID,纯粹由纯文本问题答案对组成。
WikiMovies
在(Miller et al., 2016)有介绍。包含96,000个电影相关的问题答案对。最开始是从OMDb和MovieLens数据集中创建的,这些样例的构建是为了验证只采用Wikipedia中标题和第一部分包含电影的文章作为知识源的时候,也可以回答问题。
Distantly Supervised Data
上面提供的所有QA数据集都包含训练数据,但CuratedTREC,WebQuestions和WikiMovies只包含问答对,而不是像SQuAD中有关联文档或段落,因此不能用于直接训练Document Reader。借鉴(Mintz et al., 2009)之前的用distant supervision (DS)来抽取关系的工作,我们写了个方法,将段落自动关联到这些训练样例,然后将这些示例添加到我们的训练集中。
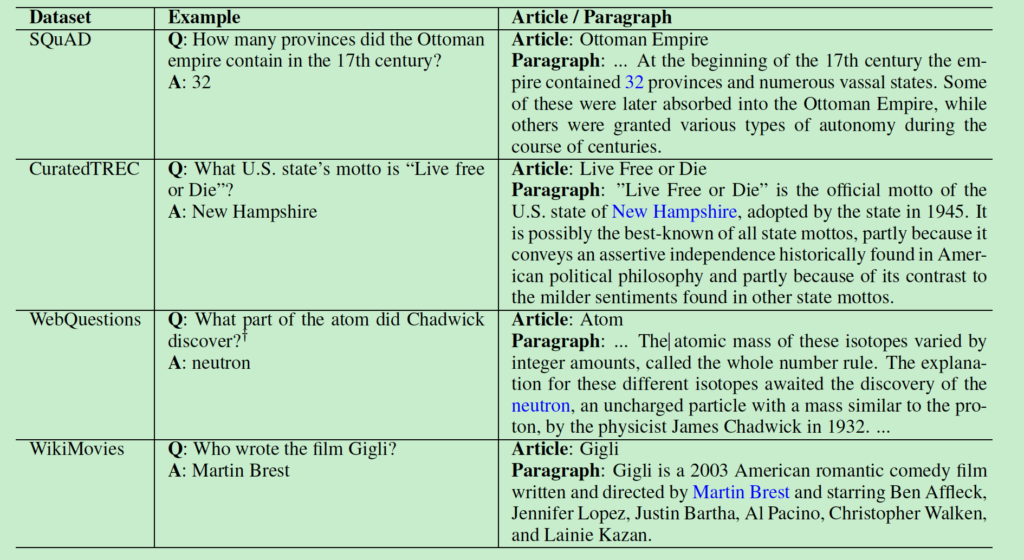
表1
方法如下:
首先,我们运行Document Retriever检索得到跟question相关的top 5篇Wikipedia文章。文章的段落中没有完全包含答案的丢弃,字符少于25或者多于1500个字符的段落丢弃。问题中包含命名实体的,如果在段落中不包含该实体的,丢弃。对剩下的所有段落,我们对匹配到答案的所有位置,用一个大小为20个token的窗口来跟question做unigram和bigram计算重叠度来进行打分,保留分数最高的5个段落。如果都是非0重叠的段落,那么这个样例丢弃;否则就加到DS训练集中。表1给了一些例子,Table2给出了统计数据。
SQuAD生成额外的DS数据,寻找答案的范围,我们不仅可以是在已提供的段落中,也可以在该段落同一页或者不同页。我们观察到大约一半的DS样例都来自SQuAD中使用的文章以外的页面。

表 2
这部分,我们首先给出Document Retriever以及Document Reader单独的评测结果,然后再给出结合使用后,DrQA的评测结果。

表3
找到相关的文章
我们首先测试了Document Retriever 模块在所有QA数据集上的表现。如表 3所示,我们对比了3.1章节中描述的另外两种办法(用Wikipedia Search Engine检索包含答案的文章)。具体而言,我们计算了系统返回top5个页面中至少有一个包含正确答案的比例,结果显示我们这个简单的方法在所有数据集上都要比Wikipedia Search的效果好,尤其是采用了bigram hashing之后。我们同样对比了Okapi BM 25以及采用bag-of-word词向量计算余弦距离的方法,两者的效果都比我们的方法差。
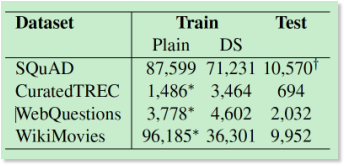
表 4
Reader在SQuAD上的评测
接下来,我们在标准SQuAD数据集上,对Document Reader模块进行评估。
评估细节:我们用3层128个隐层单元的双向LSTM对段落和问题encoding,用Stanford CoreNLP toolkit工具包进行分词,生成词根、词性、命名实体识别。
最后,所有的训练样例根据段落长度排序,然后根据每组32个来分组。我们采用(Kingma and Ba,2014)提到Adamax来进行优化。将p = 0.3的应用于word embedding和LSTM的所有隐藏单元。
结果和分析:表 4展示了我们在开发集和测试集上的评测结果。SQuAD自创建以来一直是一个非常有竞争力的benchmark,表中我们仅罗列了系统的最佳表现的数据。我们的系统在测试集上可以达到70.0%完全匹配以及79.0% F1 scores。截止本文写作的时候,我们的系统超过所有公布的结果,并且可以跟SQUAD排行榜上的最佳算法匹敌。并且,我们觉得我们的模型比绝大多数的系统要简单。我们对段落token的特征向量进行断融分析。如表5所示,所有的特征对我们系统最终的效果都有帮助。去掉对齐的question embedding feature,我们系统依然能打到超过77%的F1 score。但是,如果同时去掉![]() 和
和![]() ,系统的效果就会差很多。
,系统的效果就会差很多。
所以我们得出这样的结论:这两个特征在问题的本质释义以及答案的上下文的特征表达上起到类似但相互补充的作用。
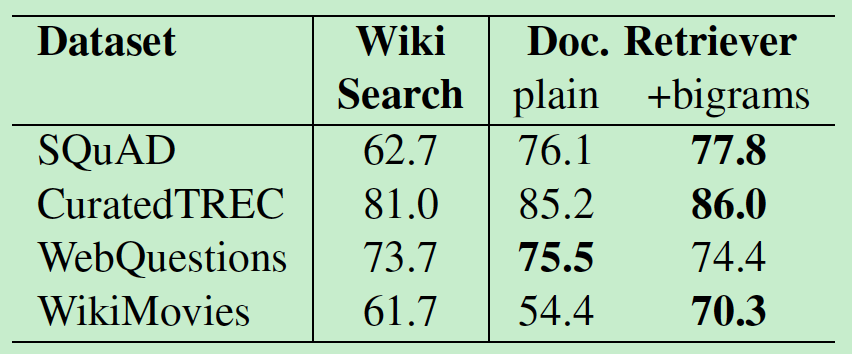
表 5
全量FullWikipedia问答
最后,我们对整个系统DrQA(面向开放领域的QA系统)在第4章节中介绍的4个数据集上进行了评测。我们分别试了3个版本的DrQA来评估采用distant supervision以及跨训练集的多任务学习带来的影响:
1.SQuAD:Document Reader模型只用SQuAD作为训练集,其他的数据集用来评估测试
2.Fine-tune (DS):Document Reader模型先在SQuAD上训练,然后分别用其他数据集的distant supervision (DS)训练集来进行优化
3.Multitask (DS):同时用SQuAD以及其他DS的训练集了训练Document Reader模型
对于整个Wikipedia,我们用了streamlined模型(没有用CoreNLP解析的![]() 或者
或者![]() )。我们发现,虽然这些特征在SQuAD上提供了精确段落情况下的阅读有帮助,但是在整体系统中却没有实际的提升。此外,WebQuestions和WikiMovies提供了候选答案的列表(例如,用于WebQuestions的160万个Freebase实体字符串),并且我们在预测期间限制答案范围必须在此列表中。
)。我们发现,虽然这些特征在SQuAD上提供了精确段落情况下的阅读有帮助,但是在整体系统中却没有实际的提升。此外,WebQuestions和WikiMovies提供了候选答案的列表(例如,用于WebQuestions的160万个Freebase实体字符串),并且我们在预测期间限制答案范围必须在此列表中。
结果: 表 6显示了评测结果。与机器理解(给定了正确的段落)和没有约束限制的QA(可以使用冗余资源)相比,我们的任务要困难许多,尽管如此,DrQA仍然在所有的四个数据集中给出了合理的表现。
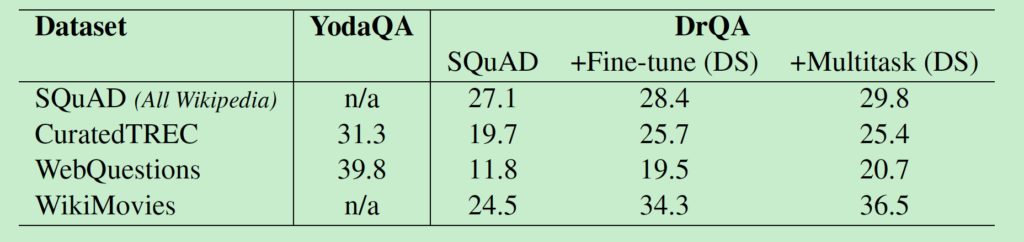
表6
我们感兴趣的是,有一个系统,单纯使用Wikipedia作为知识源就可 以回答任何问题。仅使用SQuAD进行训练的单一模型在四个数据集上的表现均优于使用distant supervision的多任务模型。然而,单独在SQuAD上进行训练时的表现并不差,表明任务转移其实是有一定作用的。然而,从SQuAD到Multitask(DS)的大部分改进可能并非来自任务迁移,因为使用DS对每个数据集单独进行优化也有改进,表明这是在同一领域中引入额外数据是有帮助的。尽管如此,我们目前能找到的最佳模型就是多任务的DS系统。
我们跟之前已经在CuratedTREC以及WebQuestions上发表过结果的无约束多知识源(不局限于Wikipedia)的QA系统YodaQA进行比较。虽然我们的任务要困难许多,但是令人欣慰的是我们系统的表现并没有比CuratedTREC(31.3 vs 25.4)差太多。在WebQuestions上差距表现的明显一些,可能是因为YodaQA直接使用了WebQuestions基于的Freebase的结构信息。
DrQA在SQuAD上的表现与其在表4中Document Reader在机器理解上的表现相比,出现大幅下降(从69.5到27.1),因为我们现在给的查找范围是整个维基百科,而不是单个段落。如果给定正确的段落,我们的表现可以达到49.4,表明非常热门的句子会带来很多错误的候选段落。尽管Document Retriever表现得不错(77.8%检索到正确答案,参见表3)。 值得注意的是,大部分下降来自SQUAD问题本身。 它们是以特定的段落作为背景而写的,因此当去掉上下文后,它们的表述可能带有歧义。 除了SQuAD以外,专门为MRS设计的其他资源可能还需要进一步研究。
我们研究了大规模数据的阅读理解问题——仅使用Wikipedia作为唯一知识源来回答开放领域的问题。 我们的研究结果表明,MRS是研究人员关注的一项非常具有挑战性的任务。 机器理解系统本身并不能解决整个问题。 为了提供了一个有效的完整系统,我们的方法集成了搜索、distant supervision和多任务学习多项技术。 并且通过在多个benchmark上评估个别组件以及的完整系统显示了我们方法的有效性。
未来的工作将主要集中在两块来提高我们的DrQA系统:
1)Document Reader目前的训练是基于单独的段落,未来在训练中,会直接多个相关段落或者文档。
2)训练端到端的Document Retriever和Document Reader管道流,而不是分开训练。
BOUT
关于作者
范雄雄,达观数据推荐算法工程师。复旦大学计算机技术专业硕士,曾在爱奇艺BI部门开发多款大数据产品;对推荐系统、数据挖掘、用户画像、大数据处理有较深入的理解和实践经验。




