
2025 年银保监会普惠金融工作会议数据显示:全国银行业普惠型小微企业贷款余额突破 38 万亿元,同比增长 23%,但普惠贷款的平均不良率仍比各项贷款平均水平高 1.2 个百分点;同时,单户授信 10 万元以下的普惠贷款,传统人工流水审核成本达 280 元 / 笔,而单笔贷款年利息收益仅约 400 元,扣除资金成本、运营成本后,银行几乎无利可图,甚至出现 “做得越多亏得越多” 的倒挂现象。
普惠金融的核心痛点,本质是 “小额分散” 的业务特征与 “传统流水审核模式” 的错配:传统对公、大额零售的审核逻辑,依赖 “全量流水核查、人工穿透验证、多维度交叉佐证”,但在普惠场景下,这种模式必然导致 “成本高、效率低、覆盖窄”—— 某农商行曾测算,若沿用传统人工审核模式,要完成年度普惠贷款投放目标,需新增 3 倍以上的审核人员,人力成本将增加 1200 万元 / 年。
与此同时,普惠客群(个体工商户、小微企业主、农户)的流水具有公私账不分、碎片化严重、现金交易占比高、第三方支付流水为主、缺乏规范财务报表的特点,传统风控模型极易失效:某城商行 2024 年普惠贷款坏账中,62% 源于 “流水造假未识别”“真实经营能力误判”,而过度收紧风控又会导致 “优质普惠客户被拒贷”,陷入 “一放就乱、一收就死” 的恶性循环。
本文聚焦普惠金融流水审核的核心困境,结合监管要求与银行实操案例,拆解 “数据整合 – 模型轻量化 – 流程分级 – 动态风控” 四位一体的平衡方案,帮助银行在不显著增加成本的前提下,实现 “效率提升、风险可控、覆盖扩大” 的三重目标,破解普惠金融的 “不可能三角”。
一、普惠金融流水审核的4大核心困境
普惠客群的经营特征与流水特点,决定了其审核逻辑与大额信贷完全不同,传统模式的短板被无限放大,形成4个难以突破的痛点:
1.困境 1:流水碎片化严重,数据质量差,真实性难验证
(1)公私账不分:90% 以上的个体工商户、小微企业主,用个人银行卡、微信、支付宝收取经营款,同时用于家庭消费,流水里混杂着买菜、育儿、房贷等个人支出,无法清晰区分经营收支与个人收支;
(2)碎片化交易:单笔交易金额多在几十元到几千元,单月交易笔数可达上百笔,人工逐笔核对效率极低;且大量现金交易无法体现在银行流水中,导致 “流水收入远低于实际经营收入”;
(3)第三方支付为主:普惠客群的经营收入中,微信、支付宝等第三方支付占比超 70%,但传统审核仅要求提供银行流水,遗漏了核心经营数据,导致经营能力误判。
2.困境 2:单户审核成本倒挂,规模化盈利难
传统流水审核的成本与贷款金额无关,无论贷款1万元还是1000万元,都需要完成 “流水收集-整理-核对-分析-复核” 的全流程。对单户授信10万元以下的普惠贷款:
(1)人工审核单户耗时约 40 分钟,人力成本+系统成本约280元/笔;
(2)若贷款年化利率4%,单笔贷款年利息仅4000 元,扣除资金成本(约2%)、坏账成本(约 2%)后,净利润不足1000元,而审核成本占比达28%;
(3)若出现1笔坏账,需要25笔正常贷款的收益才能覆盖,导致银行对小额普惠贷款 “不愿贷、不敢贷”。
3.困境 3:传统风控模型失效,风险识别准确率低
(1)缺乏征信数据:超过30%的普惠客群无央行征信记录,或征信记录空白,无法通过传统征信模型评估信用;
(2)造假成本极低:普惠客群的流水造假仅需PS几张微信、支付宝截图,成本不足 100 元,而传统人工审核难以识别;
(3)行业适配性差:传统风控模型基于大额对公、优质零售客户数据训练,对农户、街边小店、电商卖家等普惠客群的经营特征不适应,误判率高达35%以上。
4.困境 4:效率与风控的矛盾难以调和
普惠金融的核心竞争力是 “快”——客户申请贷款后,希望当天就能放款,而传统人工审核需要3-7天,无法满足客户的资金需求;但为了提升效率简化审核流程,又会导致风险上升:某银行曾推出“秒批”普惠贷产品,完全依赖征信数据,取消流水审核,上线3个月后不良率飙升至8%,被迫紧急下线。
二、破局核心:构建“轻量、智能、分级”的普惠流水审核体系
破解普惠金融流水审核困境的核心,是用技术替代人工重复劳动,用数据补充流水不足,用分级流程平衡效率与风控,实现“80% 的低风险业务自动审核,20%的高风险业务人工聚焦”,将单户审核成本降至50元以下,审核时效压缩至1小时以内,同时将不良率控制在2%以内。
1.数据层:整合多源碎片化流水,还原真实经营全貌
针对普惠客群流水碎片化、第三方支付为主的特点,打破 “仅看银行流水” 的局限,整合 “银行流水+第三方支付流水+场景经营数据”,构建多维度的经营数据画像,解决 “数据不全、真实性难验证” 的问题。
(1)全量流水一键授权采集(替代人工上传)
①对接央行 “数字人民币”、微信支付、支付宝、银联云闪付的官方API,实现客户一键授权自动采集全量流水,无需客户手动上传截图、Excel,从源头避免PS造假;
②自动标准化处理第三方支付流水,按“经营类 / 个人类”自动分类:将“收款码收入”“商家转账”标注为经营收入,将“红包”“转账给家人”“消费支出”标注为个人支出,无需人工分类;
③落地效果:某农商行上线一键采集功能后,流水收集时间从平均 2 天缩短至 5 分钟,流水造假率从28%降至3%。
(2)场景经营数据交叉验证(补充现金交易缺口)
针对普惠客群现金交易占比高的问题,引入场景化经营数据,交叉验证流水真实性:
①零售/餐饮类:对接美团、饿了么、抖音本地生活等平台,获取商户的订单量、交易额、客单价数据,与流水收入比对;
②批发/制造类:对接进销存系统、物流系统,获取进货量、出货量、库存数据,验证经营规模;
③涉农类:对接农业农村局、供销社数据,获取种植面积、养殖数量、农产品收购数据,还原农户真实经营收入。
(3)公私账自动分离算法(解决公私不分痛点)
训练专门针对普惠客群的公私账分离 AI 模型,基于“交易对手、交易金额、交易时间、交易备注”等特征,自动区分经营收支与个人收支:
①规则特征:交易对手为上下游企业、供应商、客户的,标注为经营收支;交易时间为营业时间的,优先标注为经营收支;
②AI 特征:基于海量标注数据训练模型,识别无明确备注的经营交易,准确率可达 92% 以上;
③落地效果:某银行应用公私账分离模型后,人工整理流水的时间减少 85%,经营收入核算准确率从 65% 提升至 93%。
2.模型层:轻量化风控模型,兼顾准确率与效率
针对普惠金融 “小额、高频、批量” 的特点,摒弃复杂的大模型,采用 “规则引擎+轻量机器学习模型” 的混合架构,既保证风险识别准确率,又实现毫秒级审批,同时大幅降低模型训练与运维成本。
(1)核心规则引擎(覆盖 80% 的基础风险)
基于普惠客群的常见风险点,预设 100+条可解释、易调整的审核规则,快速过滤高风险客户:
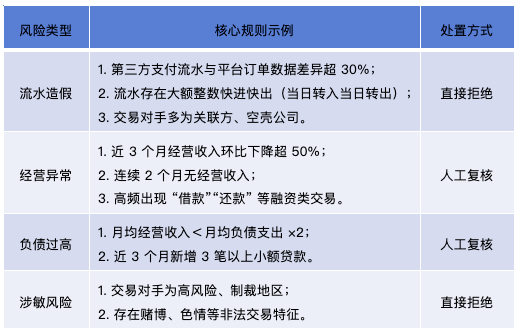
(2)轻量机器学习模型(识别隐性风险)
在规则引擎的基础上,用 XGBoost、LightGBM等轻量模型,训练普惠客群专属的风险评分模型,输入特征包括:
①流水特征:近 6 个月经营收入均值、收入波动率、交易频次、第三方支付占比;
②经营特征:行业类型、经营年限、订单量增长率、库存周转率;
③信用特征:征信记录、逾期历史、负债水平;
④模型优势:训练数据量需求小、迭代速度快、推理速度快(毫秒级),适合批量处理小额贷款申请,风险识别准确率比纯规则模型提升 25%。
(3)行业差异化模型适配(解决 “一刀切” 问题)
针对不同行业的经营特点,训练行业专属的子模型,避免“用统一标准评判所有行业”:
①餐饮行业:重点关注“日均订单量、客单价、翻台率”,允许流水有较大的季节性波动;
②涉农行业:重点关注“种植 / 养殖周期、农产品价格、补贴收入”,允许收入集中在收获季节;
③电商行业:重点关注“店铺评分、退货率、复购率”,验证线上交易的真实性。
3.流程层:分级审核机制,实现效率与风控的最优平衡
建立“自动审批-抽样复核-人工审核-专家会商”的四级分级审核流程,让机器处理80% 的低风险业务,人工仅聚焦20%的中高风险业务,最大化提升效率,同时控制风险。

核心优化点:
(1)事后抽样复核:对自动审批的低风险业务,每月抽取5%进行人工复核,若发现模型误判,立即更新模型参数,形成闭环优化;
(2)动态调整分级阈值:根据不良率变化,动态调整风险等级的评分阈值,若某一等级的不良率超过2%,则收紧阈值,提升人工复核比例;
(3)实地尽调轻量化:对高风险客户,采用“远程视频尽调”替代传统上门尽调,通过视频查看经营场所、库存、营业执照,将尽调时间从1天缩短30 分钟。
4.风控层:贷后动态监控,弥补贷前审核不足
普惠客群的经营稳定性差,仅靠贷前审核无法完全控制风险,需建立贷后流水动态监控机制,实时捕捉经营恶化信号,提前采取风险处置措施。
(1)自动监控指标:每月自动采集客户的银行流水、第三方支付流水,监控 “经营收入环比变化、负债变化、异常交易” 等指标,若出现 “连续 2 个月收入下降超 30%”“新增大额民间借款” 等情况,自动触发预警;
(2)分级预警处置:黄色预警(轻微异常):推送客户经理电话回访;橙色预警(中度异常):上门核实经营情况;红色预警(严重异常):提前收回贷款、压缩授信额度;
(3)无还本续贷自动审批:对经营正常、还款记录良好的客户,到期前自动审批无还本续贷,无需重新提交流水审核,提升客户体验的同时,降低客户流失率。
三、落地案例:某县域农商行普惠流水审核改造实践
某县域农商行,服务辖区内 2.3 万户个体工商户、农户,2024 年普惠贷款余额 18 亿元,但单户审核成本达 320 元/笔,不良率2.8%,普惠业务长期亏损。2025 年初,该行启动普惠流水审核体系改造,采用上述“数据-模型-流程-风控”四位一体方案,3 个月后实现显著效果:
1.改造措施
(1)数据整合:对接微信、支付宝、美团、饿了么 API,实现全量流水一键采集;上线公私账自动分离模型,自动区分经营与个人收支;
(2)模型搭建:基于本行近 3 年普惠贷款数据,训练 “规则引擎+ XGBoost” 混合风控模型,适配本地餐饮、零售、种植、养殖4大核心行业;
(3)流程优化:推行四级分级审核流程,低风险业务自动秒批,中高风险业务分级人工审核;
(4)贷后监控:建立贷后流水动态监控系统,实时预警经营异常。
2.改造效果
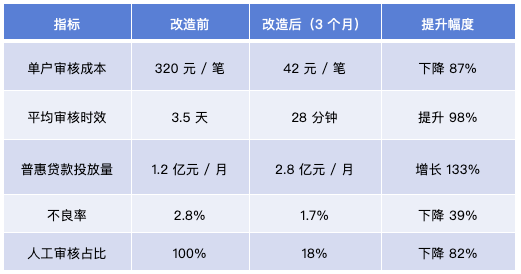
3.关键经验
(1)本地化数据优先:优先使用本行本地客户数据训练模型,比通用模型准确率高 20% 以上;
(2)循序渐进推广:先在餐饮、零售行业试点,验证效果后再推广至涉农、制造等行业;
(3)轻资产投入:无需采购昂贵的大模型,基于现有智能审核系统升级,总投入不足 50 万元,6 个月即可收回成本。
四、避坑指南:普惠流水审核的5大常见误区
1.误区 1:为了效率完全放弃流水审核,仅依赖征信数据
(1)典型表现:推出 “纯征信秒批” 产品,取消流水审核,导致大量无经营能力的客户获得贷款,不良率飙升;
(2)规避方法:即使是纯信用普惠贷,也必须采集至少近 3 个月的第三方支付流水,验证基本经营能力,征信仅作为辅助参考。
2.误区 2:照搬大额信贷审核标准,过度要求客户提供材料
(1)典型表现:要求个体工商户提供财务报表、审计报告、全套购销合同,导致客户流失率超 60%;
(2)规避方法:遵循 “最小必要” 原则,仅要求客户提供一键授权的流水数据,无需额外提供纸质材料;对高风险客户,仅要求提供核心佐证材料。
3.误区 3:模型一劳永逸,不做持续迭代
(1)典型表现:模型上线后长期不更新,面对新型造假手法、行业变化,风险识别准确率持续下降;
(2)规避方法:建立 “每月模型迭代” 机制,将人工复核发现的误判案例、新型造假案例加入训练集,持续优化模型参数;每季度根据不良率变化,调整规则与分级阈值。
4.误区 4:忽视数据合规与隐私保护
(1)典型表现:未经客户授权采集第三方支付流水,或超范围使用客户流水数据,违反《个人信息保护法》;
(2)规避方法:严格执行 “单独告知 + 明确授权” 原则,仅采集审核必需的流水数据,使用完后按规定销毁;所有数据加密存储,严格权限管控,防止数据泄露。
5.误区 5:一刀切否定现金交易,导致优质客户被拒
(1)典型表现:完全不认可现金交易,仅以银行流水核算经营收入,导致大量现金交易占比高的农户、街边小店被拒贷;
(2)规避方法:引入场景经营数据(如进货单、物流单、供销社收购数据)交叉验证现金交易,合理估算客户真实经营收入。
五、结语
惠金融的初心,是让每一个有经营能力的小微企业主、农户,都能获得平等的金融服务。而流水审核作为普惠信贷的核心环节,其痛点的破解,不能靠 “增加人力、提高利率”,而要靠技术创新 —— 用自动化采集替代人工上传,用 AI 模型替代人工整理,用分级流程替代全量人工审核,最终实现 “让数据多跑路,让客户少跑腿,让银行降成本”。
对银行业务人员而言,普惠金融不是 “政策任务”,而是未来银行业的核心增长点。谁能率先破解小额分散场景下的流水审核难题,实现 “效率、成本、风险” 的最优平衡,谁就能在普惠金融的蓝海中抢占先机,既履行社会责任,又实现商业可持续。
未来,随着数字人民币的全面推广、经营场景数据的进一步开放,普惠金融流水审核将更加智能化、自动化。但无论技术如何发展,“穿透真实经营能力、服务实体经济” 的核心始终不变 —— 这既是普惠金融的初心,也是银行风控的本质。




