在企业数字化转型进程中,PDF 等非结构化文档处理始终是效率瓶颈。金融机构的募集说明书、企业的财务报表、政务系统的审批材料,这些动辄数万字的 PDF 文件,依靠人工逐页解析、数据录入,不仅耗时耗力,更易因人为疏漏造成决策偏差。达观数据以 “RPA+AI” 双轮驱动打造的智能流程自动化解决方案,彻底打破这一困局 —— 百份 PDF 解析 / 转换效率提升 20 倍,准确率突破 99%,成为非结构化数据处理的 “隐形克星”。
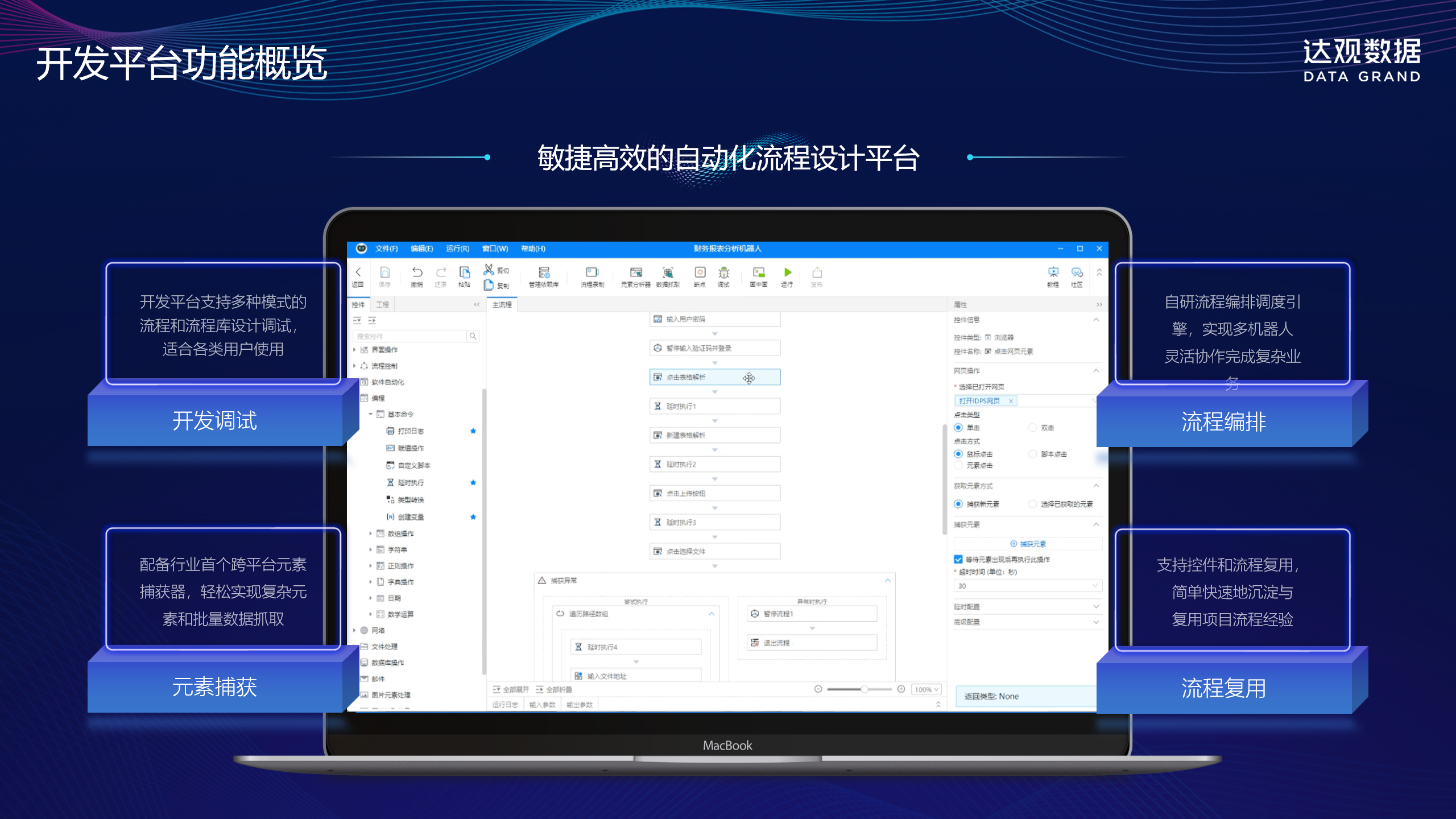
一、痛点直击:非结构化数据处理的三重困境
非结构化数据占企业数据总量的 80% 以上,其中 PDF 文档因格式固定、安全性高成为主流载体,但处理过程中普遍面临三大难题:
效率黑洞吞噬人力成本。某股份制银行曾统计,信贷审批中的 PDF 财报解析需 3 名员工耗时 1 天处理 10 份文件,百份文件处理周期长达 10 天,人工成本占运营支出的 35%。传统模式下,员工需在不同系统间切换、手动复制粘贴关键数据,重复劳动占比超 70%。
数据失真引发决策风险。人工解析依赖经验判断,复杂条款易出现理解偏差。头部券商的实践显示,人工处理新债募集说明书的准确率仅 82%,“累进利率计算”“回售触发条件” 等专业条款的误判率更是高达 15%,直接影响投资决策质量。
系统孤岛阻碍流程贯通。PDF 中的关键数据需手动录入业务系统才能产生价值,但不同平台接口不兼容导致数据流转中断。某公募基金每月需安排 4 名员工专职将 PDF 数据转录至估值系统,跨系统同步延迟超 24 小时。
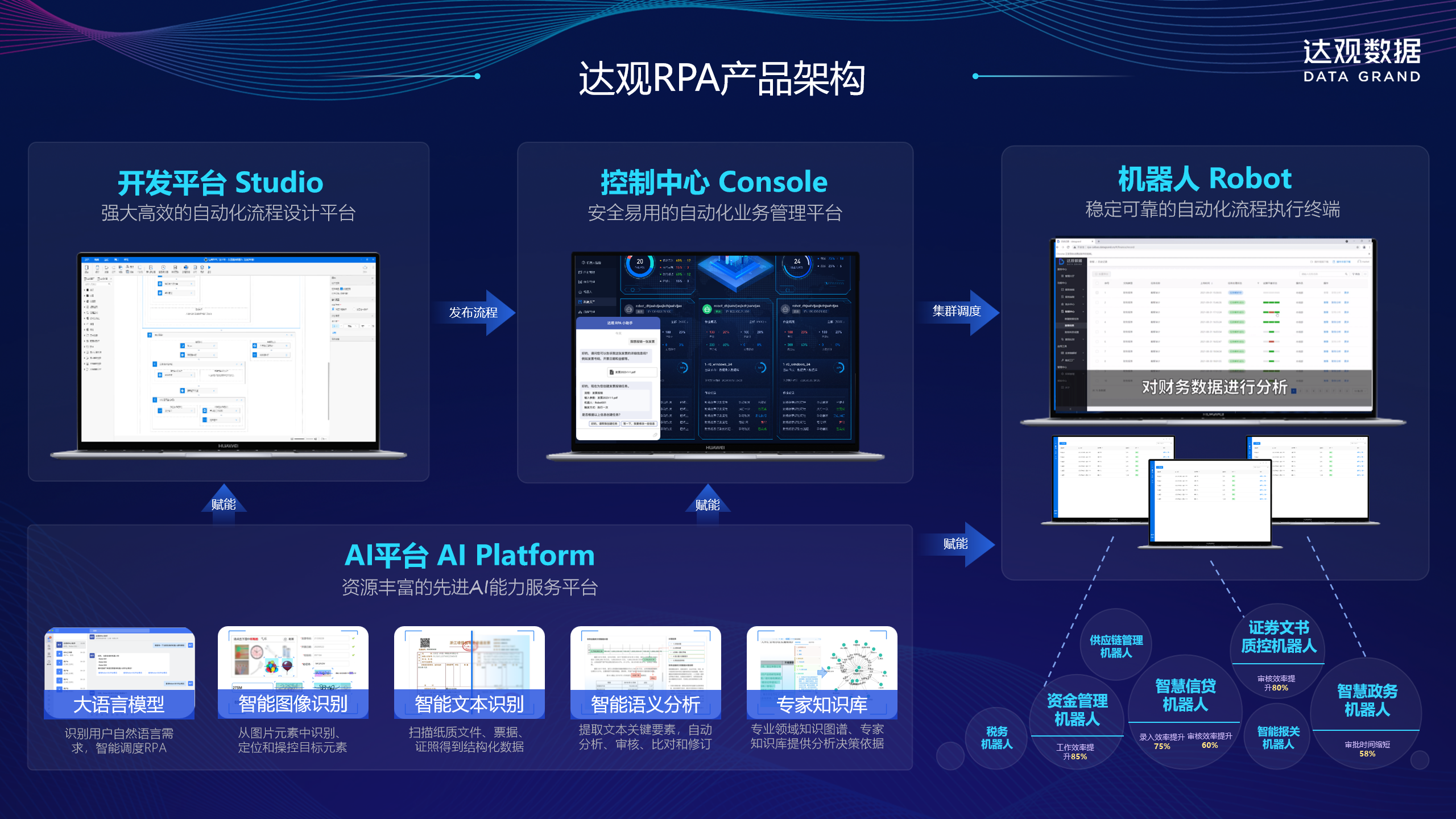
二、技术破局:达观 RPA 的 “三维智能引擎”
达观数据突破传统 RPA 的流程自动化局限,融合自研 AI 技术构建 “感知 – 决策 – 执行” 完整闭环,其核心竞争力体现在三大技术支柱:
(一)IDP 文档解析引擎:非结构化数据的 “智能眼睛”
达观自研的文档智能处理(IDP)技术,实现 PDF 解析的 “像素级精准”。针对扫描件、加密文档、多格式混排等复杂场景,通过深度学习算法完成版面分析、文字识别与要素抽取,可精准捕捉票面利率、行权价格等 100 + 类关键信息。配合 OCR 技术,即使是手写批注的 PDF 文件,识别准确率仍可达 98.5% 以上。
(二)曹植大模型:业务逻辑的 “超级大脑”
700 亿参数的曹植大模型赋予 RPA 语义理解能力,破解 “知其然不知其所以然” 的行业痛点。在处理含权债券 PDF 时,系统可自动解析 “赎回条款触发条件” 等模糊表述,通过对比历史数据生成风险提示;面对财务报表中的勾稽关系,能智能校验数据一致性,识别异常数值并标注原因。
(三)全栈自动化引擎:跨系统执行的 “灵活双手”
作为摆脱微软框架依赖的国产 RPA 平台,达观 RPA 可无缝适配麒麟操作系统、达梦数据库等国产化软硬件,同时兼容 Wind、Bloomberg 等专业终端。机器人能 7×24 小时模拟人工操作,完成 PDF 下载、解析、数据录入、报告生成全流程,且操作轨迹可追溯,满足金融行业合规要求。
三、案例实证:效率提升 20 倍的真实落地
(一)头部券商:3 分钟完成 10 万字 PDF 解析
某头部券商投研部门曾面临新债发行分析效率瓶颈:人工处理 10 万字募集说明书需 3 小时,百份文件耗时超 12 天,严重影响投资决策时效。引入达观 RPA 后,实现三大突破:
• 解析效率飙升 20 倍:RPA 机器人自动爬取上交所公告,调用 IDP 引擎 3 分钟完成单份文档解析,百份文件处理压缩至 5 小时,效率提升 28.8 倍;
• 准确率跃升至 99.2%:NLP 技术精准识别复杂条款,解析错误率从 18% 降至 0.8%,投研报告质量显著提升;
• 数据直连业务系统:结构化数据自动同步至估值模型,省去人工录入环节,决策周期从 3 天缩短至 4 小时。
(二)某城商行:账户年检效率提升 80%
某城商行资产规模突破 7500 亿元后,企业账户年检面临巨大压力:8 名员工每月全负荷工作仅能完成 3000 户审核,PDF 资料比对错误率达 12%。达观 RPA 的落地带来革命性变化:
• 夜间自动化作业:机器人凌晨登录核心系统,批量下载 PDF 格式的余额表、印鉴表,跨表比对后生成结果台账,次日仅需核查异常数据;
• 人工成本年省 60 万:季度账户自检从 3 天压缩至 4 小时,人天消耗减少 80%,全年节省人工成本超 60 万元;
• 错误率趋近于零:数据比对准确率提升至 99.99%,逾期信息整理错误率从 12% 降至 0.1% 以下,不良资产回收率提高 15 个百分点。
(三)某公募基金:每月减少 1200 小时人工操作
某公募基金新债信息收集曾依赖人工:登录 12 个数据源下载 PDF 资料,单只债券信息聚合需 5 小时,每月人工操作超 1500 小时。达观 RPA 的应用实现:
• 多源数据秒级聚合:机器人 7×24 小时巡检数据源,单只债券信息收集压缩至 15 分钟,效率提升 20 倍;
• 自动去重与同步:跨平台数据自动去重校验,实时更新至数据中台,每月减少人工操作 1200 小时;
• 合规风险可控:操作轨迹全程留痕,满足监管部门数据溯源要求,通过等保三级认证。

四、全场景覆盖:不止于 PDF 解析的价值延伸
达观 RPA 的非结构化数据处理能力已渗透至多行业核心场景:
金融领域:在信贷审批中,自动解析企业 PDF 财报并计算偿债能力指标;资管业务中,实现信托计划 PDF 合同的条款抽取与风险预警;
企业财务:费用报销时自动识别 PDF 发票信息,与报销单比对校验;采购付款环节,解析供应商 PDF 对账单并完成付款审批;
供应链管理:智能报关机器人解析 PDF 报关单,自动录入海关系统,报关效率提升 3 倍。
五、实施保障:45 天快速落地的服务体系
达观数据建立全周期服务体系确保价值落地:前期通过流程诊断定位痛点,出具定制化方案;实施阶段采用敏捷开发,45 天即可完成平台部署与流程开发,如某城商行项目仅用 6 周即实现全流程上线;后期提供 7×24 小时运维与技术升级,保障系统数万小时平稳运行。
结语
当企业还在为百份 PDF 的处理效率焦头烂额时,达观数据已用 “RPA+AI” 技术重新定义非结构化数据处理标准。从 3 分钟解析 10 万字文档到 99.99% 的比对准确率,从每月节省 1200 小时人工到年降 60 万成本,这些真实数据印证了其 “非结构化数据克星” 的实力。在数字化转型进入深水区的今天,选择达观 RPA,就是选择效率革命与成本优化的双重突破。





