

1 NER简介
NER(Named Entity Recognition,命名实体识别)又称作专名识别,是自然语言处理中常见的一项任务,使用的范围非常广。命名实体通常指的是文本中具有特别意义或者指代性非常强的实体,通常包括人名、地名、机构名、时间、专有名词等。NER系统就是从非结构化的文本中抽取出上述实体,并且可以按照业务需求识别出更多类别的实体,比如产品名称、型号、价格等。因此实体这个概念可以很广,只要是业务需要的特殊文本片段都可以称为实体。以下将详细介绍达观数据在文本语义理解过程中是如何构建中文NER系统的。(达观数据 高翔)
2 NER问题分解
NER问题的目标是从文本抽取出特定需求实体的文本片段。针对这个任务,通常使用基于规则的方法和基于模型的方法。
2.1基于规则的方法
基于规则进行实体抽取是较容易想到的方式。针对有特殊上下文的实体,或实体本身有很多特征的文本,使用规则的方法简单且有效。比如,抽取文本中物品价格,如果文本中所有商品价格都是“数字+元”的形式,则可以通过正则表达式”\d*\.?\d+元”进行抽取。但是如果待抽取文本中价格的表达方式多种多样,例如“一千八百万”、“伍佰贰拾圆”、“2000万元”,这个时候就要修改规则来满足所有可能的情况。随着语料数量的增加,面对的情况也越来越复杂,规则之间也可能发生冲突,整个系统也可能变得不可维护。因此基于规则的方式比较适合半结构化或比较规范的文本中的进行抽取任务,结合业务需求能够达到一定的效果。总结一下基于规则的实体抽取方式,优点:简单,快速;缺点:适用性差,维护成本高后期甚至不能维护。(达观数据 高翔)
2.2 基于模型的方法
从模型的角度来看,命名实体识别问题实际上是序列标注问题。序列标注问题指的是模型的输入是一个序列,包括文字、时间等,输出也是一个序列。针对输入序列的每一个单元,输出一个特定的标签。以中文分词任务进行举例,例如输入序列是一串文字:“我是中国人”,输出序列是一串标签:“SSBME”,其中“BMES”组成了一种中文分词的标签体系,B表示这个字是词的开始Begin,M表示词的中间Middle,E表示词的结尾End,S表示单字成词。因此我们可以根据输出序列“SSBME”进行解码,得到分词结果“我\是\中国人“。序列标注问题涵盖了自然语言处理中的很多任务,包括语音识别、中文分词、机器翻译、命名实体识别等,而常见的序列标注模型包括HMM,CRF,RNN等模型。
2.2.1 HMM
HMM(Hidden Markov Model,隐马尔可夫模型)是使用非常广泛经典的一个统计模型,作为一个生成式模型,HMM用来描述一个含有隐含未知参数的马尔可夫过程。简单来讲,HMM模型包括两个序列三个矩阵:观察序列、隐藏序列、初始状态概率矩阵、状态转移概率矩阵、发射概率矩阵。通常情况下,我们要根据观察序列和三个矩阵,来得到隐藏序列。
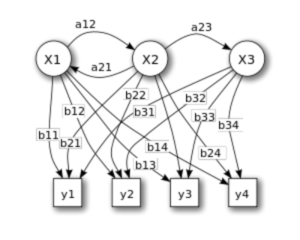
图1:HMM模型,其中X表示隐藏序列,y表示观察序列,a表示状态转移概率,b表示发射概率
以中文分词任务举例,使用“BMES”标签体系,HMM模型就是从切分好的语料中统计出初始状态概率矩阵、状态转移概率矩阵、发射概率矩阵这三个矩阵的概率参数。初始状态矩阵指的是序列第一个字符是BMES的概率,显然字符是M和E的概率为0。状态转移概率矩阵是BMES四种状态间转移的概率,显然B–>S,M–>S,M–>B等状态的转移概率为0。发射概率矩阵指的是一个字符是BMES四种状态其中一种的概率,比如“中–>B:0.3“、“中–>E:0.4“等。可以看到,HMM模型只需按照模型要求,统计出上述概率矩阵即可,因此HMM的优点是模型简单训练快,但因为马尔可夫假设的原因,模型效果相对较差。
2.2.2 CRF
CRF(Conditional random field,条件随机场)是一种判别式模型。条件随机场是给定随机变量X的情况下,随机变量Y的马尔科夫随机场。马尔科夫随机场是概率无向图模型,满足成对、局部及全局马尔可夫性。对于序列标注问题,一般使用线性链条件随机场。
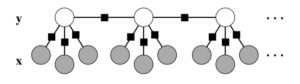
图2:一种线性条件随机场
对于条件随机场的模型训练,通常使用基于BFGS、SGD等算法的优化算法,不同软件包的实现上也有所区别。理论上CRF算法性能要优于HMM,因为CRF可以使用更多的特征,但同时,特征选择对于模型的性能有一定的影响,除此之外,相对于HMM,CRF模型的训练也更加复杂,时间相对较长。
2.2.3 RNN
随着深度学习的兴起,RNN、LSTM、BILSTM等模型已经被证明在NLP任务上有着良好的表现。相比传统模型,RNN能够考虑长远的上下文信息,并且能够解决CRF特征选择的问题,可以将主要的精力花在网络设计和参数调优上,但RNN一般需要较大的训练数据,在小规模数据集上,CRF表现较好。在学术界,目前比较流行的做法是将BILISTM和CRF进行结合,借鉴两个模型各自的优点,来达到更好的效果。
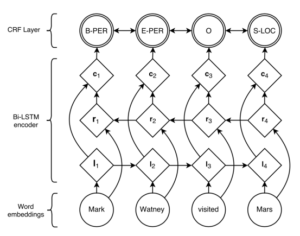
图3:BILSTM+CRF标注模型
3基于CRF模型打造中文NER系统
上面介绍了用于序列标注不同模型的特点。虽然深度学习有着广阔的前景,并且在机器翻译等任务上表现优异,但对于序列标注任务而言,CRF模型老而弥坚且比较成熟,在工业界中被广泛使用,因此本章使用CRF模型打造一个中文NER系统。(达观数据 高翔)
3.1 明确标注任务
前文讲过,NER可以根据业务需求标注各种不同类型的实体,因此首先要明确需要抽取的实体类型。一般通用场景下,最常提取的是时间、人物、地点及组织机构名,因此本任务提取TIME、PERSON、LOCATION、ORGANIZATION四种实体。
3.2 数据及工具准备
明确任务后就需要训练数据和模型工具。对于训练数据,我们使用经典的人民日报1998中文标注语料库,其中包括了分词和词性标注结果,下载地址为:http://icl.pku.edu.cn/icl_groups/corpus/dwldform1.asp。对于CRF,有很多开源的工具包可供选择,在此使用CRF++进行训练。CRF++官方主页为https://taku910.github.io/crfpp/,包括下载及使用等说明。
3.3 数据预处理
人民日报1998语料库下载完毕后,解压打开“199801.txt”这个文件(注意编码转换成UTF-8),可以看到内容是由word/pos组成,中间以两个空格隔开。我们需要的提取的实体是时间、人名、地名、组织机构名,根据1998语料库的词性标记说明,对应的词性依次为t、nr、ns、nt。通过观察语料库数据,需要注意四点:1,1998语料库标注人名时,将姓和名分开标注,因此需要合并姓名;2,中括号括起来的几个词表示大粒度分词,表意能力更强,需要将括号内内容合并;3,时间合并,例如将”1997年/t 3月/t” 合并成”1997年3月/t”;4,全角字符统一转为半角字符,尤其是数字的表示。
通过脚本将语料库数据进行处理,处理前后的结果如图4和图5所示。
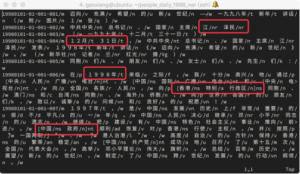
图4:人民日报1998标注语料数据处理前
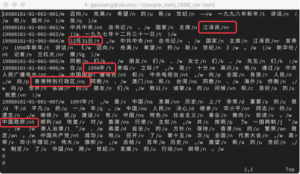
图5:人民日报1998标注语料数据处理后
3.4 模型训练
根据我们的NER任务需求及CRF++的训练要求,模型训练需要4个步骤:1,确定标签体系;2,确定特征模板文件;3,处理训练数据文件;4,模型训练。(达观数据 高翔)
3.4.1 确定标签体系
对于NER任务,常见的标签体系包括IO、BIO、BMEWO、BMEWO+。下面举例说明不同标签体系的区别。
| Tokens | IO | BIO | BMEWO | BMEWO+ |
| 昨 | O | O | O | O |
| 天 | O | O | O | O |
| , | O | O | O | O_PERSON |
| 李 | I_PERSON | B_PERSON | B_PERSON | B_PERSON |
| 晓 | I_PERSON | I_PERSON | M_PERSON | M_PERSON |
| 明 | I_PERSON | I_PERSON | E_PERSON | E_PERSON |
| 前 | O | O | O | PERSON_O |
| 往 | O | O | O | O_LOCATION |
| 上 | I_LOCATION | B_LOCATION | B_LOCATION | B_LOCATION |
| 海 | I_LOCATION | I_LOCATION | E_LOCATION | E_LOCATION |
| 。 | O | O | O | LOCATION_O |
表格1:不同标签体系的标注示例
大部分情况下,标签体系越复杂准确度也越高,但相应的训练时间也会增加。因此需要根据实际情况选择合适的标签体系。本文选择和分词系统类似的BMEWO标签体系。
3.4.2 特征模版设计
特征模版是一个文本文件,其内容如图6所示,其中每行表示一个特征。图6使用了unigram特征,并且仅以字符本身作为特征而不考虑其他特征。除当前字符外,还使用了其前后3个字,以及上下文的组合作为特征。CRF++会根据特征模版生成相关的特征函数。关于特征模版的详细解释可以查看官网文档,并且对于特征的选择和设计可以灵活配置,图6仅作为参考。
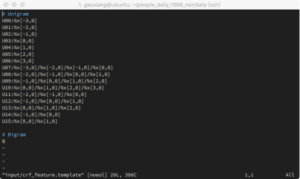
图6:特征模板设计
3.4.3 训练数据生成
CRF模型的训练数据是一行一个token,一句话由多行token组成。每一行可以分为多列,除最后一列外,其他列表示特征。本文所描述的NER系统,单字表示token,并且仅使用字符这一种特征,因此可以根据语料库中每个字在词中的位置和词性,以及所选的标签系统,生成CRF++的训练数据。生成的训练数据如图7所示。
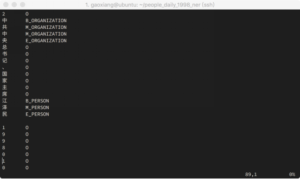
图7:CRF++训练数据示例
3.4.4 模型训练
准备好特征模版和训练数据后就可以进行模型训练,如图8所示。使用crf_learn命令,指定模版文件、训练数据文件和输出模型文件就可以进行训练。参数-f 1表示过滤频次低于1的特征,在这里不进行特征过滤,-c 1.0用来调节CRFs的超参数,c值越大越容易过拟合。除此之外,还有-a等其他参数进行控制调整。图9展示了训练完毕的相关数据。
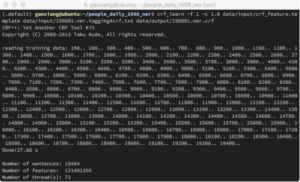
图8:CRF++训练过程
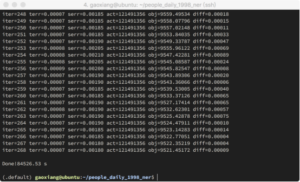
图9:CRF++训练结果
3.5 模型预测及使用
模型训练完毕后就可以进行预测。CRF++提供crf_test命令进行测试,我们使用文本“北京市委组织部长姜志刚调任宁夏副书记“进行测试,测试文件中每字一行,每句话使用空行隔开。测试结果如图10所示。
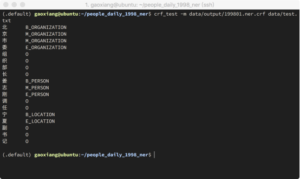
图10:CRF++测试结果
从图10的结果我们可以看到,CRF模型能够对输入文字序列输出相应的标签从而完成NER任务。在模型预测时,CRF++主要使用了维特比算法进行nbest输出。在模型训练时,可以指定-t参数输出文本格式的模型,方便debug或编写自己的模型加载及解码程序。
对于一个完整的NER过程,除了得到序列标签外,还要对标签序列进行解码得到最终的结果。CRF++同时提供了python接口,可以方便的在python 程序中进行模型的调用得到标签序列,然后通过标签解码得到最终的结果。图11展示了一个完整的NER预测结果。
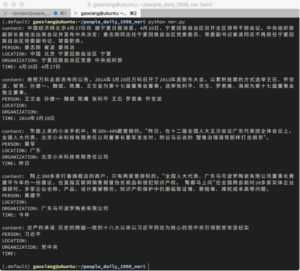
图11:使用python代码进行NER的预测结果
图11展示了较好的结果,能够识别出诸如“北京小米科技有限责任公司”这样的组织机构名。通过使用1998年的数据识别出了2010年才成立的公司,这就是模型算法的力量。当然模型也有瑕疵,诸如“郁亮“、”海闻”这样的人名没有识别出来,这除了和模型特征选择相关外,也和语料库的规模和标注有关,因此语料库的建设和积累更加重要。(达观数据 高翔)
4 总结
本文讲述了NER任务的基本概念及方法,并使用业界成熟的语料和工具开发了一个简单能work的基于CRF模型的中文NER系统,而实际提供线上服务的NER系统要比这个复杂的多。在自然语言处理的实际工作中,除了不同模型、算法、工具的使用和参数调优外,语料库的选择和积累也非常重要。对于中文文本语义分析技术,达观数据拥有多年的技术积累并紧跟行业潮流,对已有成熟技术进行深挖,对新兴技术进行研究集成。同时,针对不同行业及任务积累了丰富的文本语料,并源源不断的使用新数据对语料模型进行升级更新,保证分析结果的准确性和实时性,为客户提供高品质服务。(达观数据 高翔)
作者简介
高翔,达观数据联合创始人,首席数据官联盟成员,达观数据前端项目组、文本语义理解组负责人,自然语言处理技术专家,上海交通大学通信专业硕士,曾代表达观数据参加2016青年互联网创业大赛并赢得全国总冠军荣誉、第五届中国创新创业大赛优秀企业奖、中国电子i+创新创效创意大赛总决赛一等奖。曾就职于腾讯文学,盛大文学,盛大创新院,负责文本阅读类产品、搜索引擎、文本挖掘及大数据调度系统的开发工作。在自然语言处理和机器学习等技术方向有着丰富的经验。




